Perplexity Computer Review: 19 Models, One Goal
Perplexity Computer orchestrates 19 AI models to run complex multi-step tasks in the background - impressive research depth, punishing credit costs.
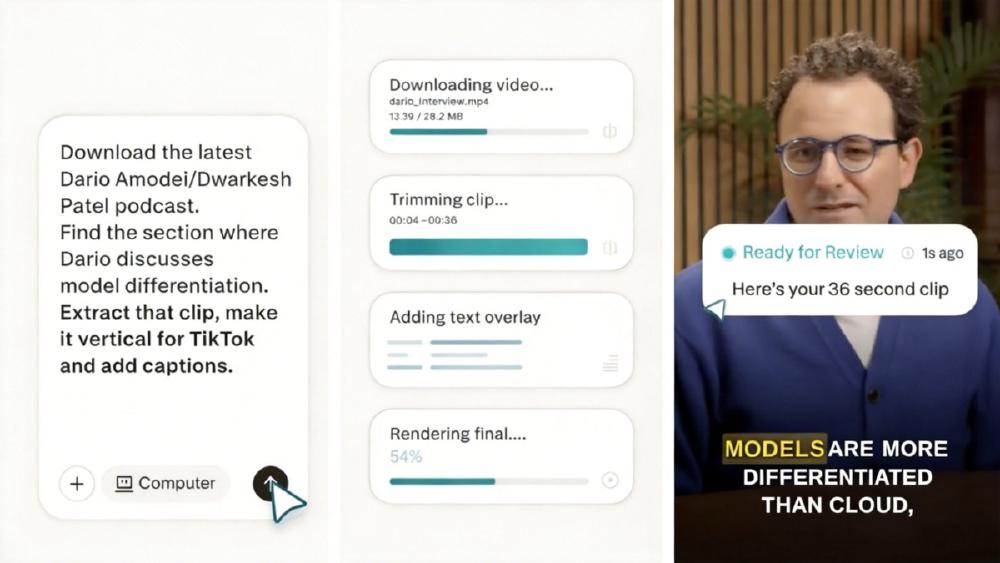
Perplexity just made its clearest statement about the current AI market: the models don't matter, the orchestration does. Launched on February 25, Perplexity Computer is a cloud-based multi-agent system that accepts a high-level goal, breaks it into subtasks, and routes each to one of 19 AI models running in parallel. It's expensive, occasionally infuriating, and genuinely useful in ways that single-model tools aren't. Whether it's worth $200 a month depends completely on what you throw at it.
TL;DR
- 7.2/10 - The most capable multi-model agent available, undercut by opaque credit costs and no debugging visibility
- Orchestrating specialist models across research, code, and media tasks produces output that single-model tools can't match
- Failed runs still burn credits, and the sandbox resets between conversations with no debugging trail
- Best for research-heavy power users who can absorb a variable monthly bill; skip if your workflows are mostly single-task
What Perplexity Computer Is
The product runs entirely in Perplexity's cloud inside a managed Linux sandbox - 2 vCPU, 8GB RAM, with Python, Node.js, and ffmpeg pre-installed. You submit a high-level goal in plain text. Claude Opus 4.6 acts as the orchestrator, breaking the goal into subtasks and routing each to a specialist model. GPT-5.2 handles long-context recall. Gemini takes on deep research queries. Grok picks up speed-sensitive work. Nano Banana produces images. Veo 3.1 handles video. Thirteen more models fill out the pool - Perplexity hasn't named them individually.
The background execution model is the core bet. Tasks run while you close your browser and do something else. You can start a competitive analysis, leave for a meeting, and return to a finished report. Context persists across subtask boundaries, so a later research step knows what an earlier retrieval step found.
Perplexity CEO Aravind Srinivas put the philosophy directly in a Fortune interview: "When you build a team, you don't build a homogenous group where everyone has the same skills. You build a team with diverse strengths." That philosophy is the product.
 The Perplexity Computer task interface, with its minimal "What should we work on next?" prompt and the Max plan requirement.
Source: semafor.com
The Perplexity Computer task interface, with its minimal "What should we work on next?" prompt and the Max plan requirement.
Source: semafor.com
Where It Actually Works
Research workflows are where Computer earns its subscription price. Seven parallel search types - web, academic, people, image, video, shopping, social - run simultaneously, reading full source pages rather than snippets. For competitive analysis, market due diligence, or multi-source synthesis, the output depth is measurably better than a single model with a browsing plugin.
Multi-format deliverables impress consistently. In one documented test by reviewer Karol Zieminski, a single brand-guidelines file and a text prompt produced two fully branded, working tools rolled out to GitHub in under 30 minutes. Another user fed Computer a podcast clip URL and got back a trimmed, captioned, ready-to-post video. Both tasks would have taken a human several hours each.
The long-running background execution also differentiates Computer from tools like Manus AI or standard AI agent setups. There's no babysitting the session. Complex multi-step projects don't require a human in the loop at each transition. The 400+ OAuth connectors (Slack, Gmail, GitHub, Notion) and 50+ pre-built skill playbooks give the orchestrator enough surface area to handle real business workflows without manual API wiring.
The combination of deep parallel search with session-level context persistence is the genuine technical distinction. It isn't just faster than doing it yourself - it finds things a single search pass misses.
The Credit System Is a Risk
This is where the product gets complicated.
$200 a month gets you the Perplexity Max subscription plus 10,000 monthly credits. New subscribers currently receive 20,000 to 35,000 bonus credits at signup (expiring after 30 days). Credit consumption varies by task complexity, number of subagents spawned, and which models get invoked. Costs only appear after task completion via a usage dashboard.
One Builder.io reviewer spent roughly $200 in compute credits building a single webpage over two days - on top of the subscription fee. Heavy users on Reddit estimate $1,500 per month in credits for intensive workflows. The configurable monthly spending cap maxes at $2,000, putting the theoretical ceiling at $2,200 per month for a single account.
Two structural problems compound the cost. First: failed processes consume credits without clear failure signals. If an agent hits an unexpected state, the system keeps attempting to recover and keeps spending. There's no cost-runaway alert. Second: the sandbox resets between conversations. No custom environment persists. Multi-session projects rebuild context from files rather than from state, which affects both credits consumed and output consistency.
 Aravind Srinivas, Perplexity co-founder and CEO, at TechCrunch Disrupt 2024. He has described Computer as "the orchestration is the product."
Source: techcrunch.com
Aravind Srinivas, Perplexity co-founder and CEO, at TechCrunch Disrupt 2024. He has described Computer as "the orchestration is the product."
Source: techcrunch.com
Auto-refill is off by default - Perplexity doesn't charge without opt-in. But the opacity of credit consumption before a task completes is a real problem. You don't know what a complex workflow will cost until after it runs.
Where It Falls Short
Coding iteration is weaker than the research capability suggests it should be. The sandbox offers no live preview and no hot-reloading. Visual changes require full cloud deployments to Vercel, adding 2-3 minutes per iteration. For any kind of iterative UI work, that's a painful loop. The orchestrator also makes counterintuitive technical choices - Builder.io noted it using GitHub's API directly for repo manipulation rather than standard development workflows, which produces fragile results.
The invisible sandbox is the structural limitation. Manus AI shows a real-time replay of every action its agents take. Computer shows nothing while tasks run. When output is wrong or a task fails, there's no execution trace to debug. You re-prompt and hope.
OAuth connector coverage is uneven. The Ahrefs integration, for example, surfaces only backlink data - no keyword research, no site audit - despite Ahrefs covering all of those as a product. Mobile support was absent at launch. Custom MCP servers aren't supported. Generated apps ship with a "Generated with Perplexity Computer" watermark.
Perplexity also carries active copyright litigation related to its content-sourcing practices. Semafor's coverage notes that lawyers have described this as posing an "existential threat" to AI companies aggregating publisher content without licensing agreements. For enterprise users building workflows on the platform, that legal exposure is worth factoring in.
How It Compares
Independent benchmark data doesn't exist yet for Computer as a system. Perplexity published its own "Draco" benchmark for complex research tasks, and its deep research component - powered by Claude Opus 4.6 - claims top placement on Google DeepMind's Deep Search QA and Scale AI's Research Rubric. Those are self-reported comparisons. Against the agentic AI benchmarks tracked independently, Computer hasn't been formally assessed.
Against Manus AI: Computer has stronger research depth and longer-running task support. Manus has better execution transparency, a free tier, and broader consumer distribution via Meta's platforms. Against Claude Cowork: Cowork runs locally with a single model, flat monthly pricing with no usage fees, and HIPAA compliance - a better fit for regulated industries and document-heavy work. Computer beats both on raw research tasks. It costs more and shows you less while running.
The three tools serve different use cases more than they directly compete. Computer is the right pick for multi-source research and long-horizon agentic tasks. Manus wins on accessibility and transparency. Cowork wins on predictable costs and data governance.
Verdict
Perplexity Computer is the best execution of the multi-model orchestration thesis I've seen. The research output quality is real. Background execution works as advertised. The multi-format deliverables are truly impressive for complex projects.
The problems are structural rather than cosmetic. Opaque credit consumption, no debugging visibility, and sandbox resets between sessions mean the product rewards users who can tolerate uncertainty and absorb variable costs. For research-heavy power users who run complex, multi-source projects and can stomach a potentially $500+ monthly bill, Computer probably delivers enough time savings to justify it.
For everyone else, the Pro and Enterprise tier rollout - which Perplexity has signaled is coming - is worth waiting for. Broader access with more predictable pricing would make this truly competitive for a larger market.
Score: 7.2/10
Sources
- Perplexity launches Computer super-agent - Semafor, Feb 25, 2026
- Perplexity CEO Aravind Srinivas on Computer - Fortune, Feb 26, 2026
- Perplexity's Computer is another bet on many AI models - TechCrunch, Feb 27, 2026
- Perplexity launches Computer AI agent coordinating 19 models - VentureBeat, Feb 2026
- Perplexity Computer hands-on review - Builder.io
- Perplexity Computer review with working examples - Karol Zieminski, Substack
- Manus vs Claude Cowork vs Perplexity Computer comparison - Sliq
- Perplexity Computer cost and pricing breakdown - Sliq
- Introducing Perplexity Computer - Perplexity official blog
- Perplexity Computer - enterprise multi-model architecture - The AI Insider

