Nemotron 3 Super Review: Best Open Model for Agents
NVIDIA Nemotron 3 Super is the strongest open-weight model for agentic coding as of March 2026, but its efficiency-first design means real trade-offs on general knowledge and chat quality.

NVIDIA released Nemotron 3 Super at GTC 2026 on March 11, and it's a truly unusual model. It's a 120-billion parameter open-weight model that activates only 12 billion of those parameters per token, runs on a context window of one million tokens, and tops the SWE-bench Verified leaderboard among open models. For AI agents doing real software work, nothing open-weight comes close right now. The question is whether the architecture decisions that make it so fast for agents quietly break it for everything else. The answer, unfortunately, is yes, in specific ways worth knowing before you commit.
TL;DR
- 8.2/10 - the best open-weight model for agentic coding and long-context tasks, but a poor fit for general Q&A or conversational use
- Strongest open-model score on SWE-bench Verified (60.47%) and RULER@1M (91.75%), with 5x throughput over the previous generation
- Arena-Hard-V2 at 73.88% trails gpt-oss-120b's 90.26%; tool calling degrades significantly without the reasoning mode active
- Essential for teams building multi-agent coding pipelines on open infrastructure; skip it if you need broad scientific knowledge or high-quality chat responses
What NVIDIA Built - and Why the Architecture Matters
The model profile at awesomeagents.ai/models/nvidia-nemotron-3-super-120b-a12b covers the raw specs in full. Briefly: 120B total parameters, 12B active per forward pass, a hybrid Mamba-2 plus Transformer architecture with NVIDIA's proprietary LatentMoE routing, and Multi-Token Prediction (MTP) layers that function as a built-in speculative decoder.
The architecture is a serious piece of engineering. Most large open MoE models - Qwen, Llama, Mixtral - route tokens to experts using standard transformer attention at every layer. Nemotron 3 Super interleaves three fundamentally different components: Mamba-2 state-space layers handle the bulk of sequence processing in linear time, periodic Transformer attention layers provide precision reasoning at key depths, and LatentMoE layers compress tokens into a smaller latent space before routing, activating four times more expert specialists for the same compute cost.
The practical result is a model that handles one million tokens on hardware where most competitors would give up or hallucinate badly. On RULER (a long-context retrieval benchmark at 1M tokens), Super scores 91.75% versus GPT-OSS-120B's 22.30%. That's not a small gap - it's a different class of capability for workflows that actually need million-token contexts.
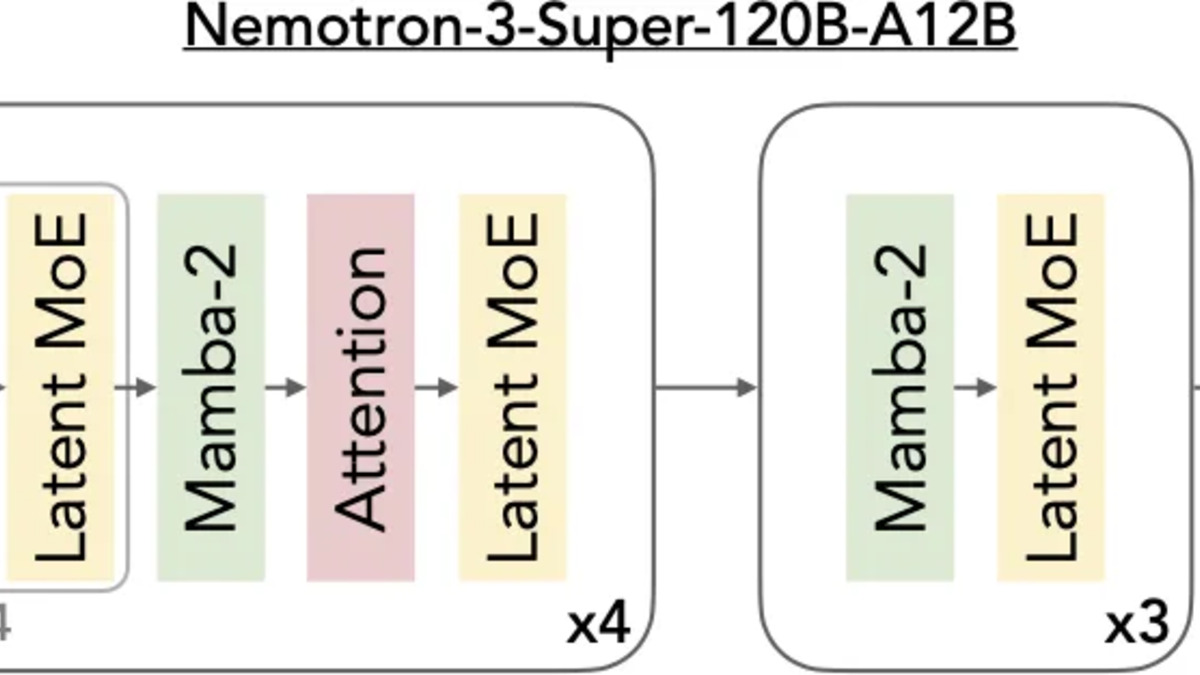 The layer pattern diagram from the technical blog: Mamba-2 blocks alternate with LatentMoE layers, with full attention at select depths. This design enables linear-time context scaling while preserving reasoning depth.
Source: developer.nvidia.com
The layer pattern diagram from the technical blog: Mamba-2 blocks alternate with LatentMoE layers, with full attention at select depths. This design enables linear-time context scaling while preserving reasoning depth.
Source: developer.nvidia.com
The NVFP4 Angle
One detail that's easy to miss: Nemotron 3 Super was pretrained natively in NVFP4, not post-quantized. Most quantized models start in full precision and lose quality during conversion. NVIDIA trained from the first gradient update in 4-bit floating point, which means the model has learned to be accurate within 4-bit arithmetic constraints rather than being compressed after the fact.
On NVIDIA Blackwell GPUs, this delivers a 4x inference speedup over FP8 on Hopper (H100). The NVFP4 PTQ process on a single B200 node (8 GPUs) completes in under two hours and recovers 99.8% of BF16 median accuracy. For teams deploying on Blackwell - or on the NVIDIA DGX Spark - this matters a great deal.
Benchmark Performance
Key Benchmarks vs Similar-Class Open Models
| Benchmark | Nemotron 3 Super | GPT-OSS-120B | Qwen3.5-122B |
|---|---|---|---|
| SWE-Bench Verified | 60.47% | 41.90% | ~55% |
| SWE-Bench Multilingual | 45.78% | 30.80% | - |
| RULER @ 1M tokens | 91.75% | 22.30% | - |
| PinchBench (agentic) | 85.6% | - | - |
| MMLU | 86.01% | - | - |
| Arena-Hard-V2 | 73.88% | 90.26% | - |
| GPQA | 79.23% | - | 86.60% |
| Intelligence Index (AA) | 36 | 33 | 42 |
The agentic and coding numbers are outstanding. The 60.47% on SWE-bench Verified is the best published result for any open-weight model today. SWE-bench Multilingual at 45.78% also comfortably beats GPT-OSS-120B.
But the Arena-Hard and GPQA numbers tell a different story. Arena-Hard-V2 at 73.88% versus GPT-OSS-120B's 90.26% is a large gap on general conversational quality. GPQA at 79.23% compared to Qwen3.5's 86.60% shows the model has been tuned away from broad scientific knowledge. The Artificial Analysis Intelligence Index score of 36 beats gpt-oss (33) but trails Qwen3.5-122B (42), which has six more intelligence points at the cost of 40% lower throughput per GPU.
This is the core engineering trade-off. NVIDIA made an explicit choice to optimize for agent workflows rather than benchmark breadth, and it shows up in both the numbers and the way the model actually behaves.
Hands-On: What It's Good At
Greptile tested Super on real pull requests using their internal evaluation harness. On a 19-file, 134KB diff, the model "returned a useful review in 12.5 seconds with just 2 tool calls," surfacing five findings including a critical CORS regression where an origin check disappeared before CORS headers were set. That's fast and accurate.
Where it showed limits: comments requiring broader codebase context were thinner, and some feedback "skewed more toward cleanup than correctness." Greptile's verdict was "a strong first-pass reviewer, especially on PRs where latency and signal both matter."
PinchBench, which specifically measures model performance as the planning brain in multi-agent systems, gives it 85.6% across the full test suite - the highest score for any open model. It scored 100% on automation tasks like project structure creation and search-and-replace operations, and 98-100% on CSV and Excel data summarization. For the orchestration layer of an agent pipeline, these numbers are hard to argue with.
 The official product image for Nemotron 3 Super, showing NVIDIA's "5x throughput" headline claim for the model's agentic positioning.
Source: blogs.nvidia.com
The official product image for Nemotron 3 Super, showing NVIDIA's "5x throughput" headline claim for the model's agentic positioning.
Source: blogs.nvidia.com
The Verbosity Problem
One practical issue that multiple users have flagged: the model is verbose. Third-party token analysis puts Super's average output volume far above peer models at the same context length. This inflates cost and latency on hosted APIs, and it means prompt engineering for conciseness is more work than usual. On free-tier access via OpenRouter this doesn't matter much, but on production volume it adds up.
Tool calling performance without reasoning enabled is described as "very poor" in independent testing. The initial thinking segment adds to latency but is effectively required for reliable tool use. There's no free lunch here.
Deployment and Pricing
The model is truly open: weights, training data, and fine-tuning recipes are published under the NVIDIA Nemotron Open Model License on Hugging Face. The license is permissive for commercial use but includes a patent termination clause - not Apache 2.0. That distinction matters if your legal team needs to review it before deployment.
Access options are wide. Weights are available in BF16, FP8, and NVFP4 variants. Hosted inference runs across DeepInfra, Together AI, Fireworks AI, Google Cloud, Nebius, Cloudflare, and a dozen others. OpenRouter offers a free tier at $0 per million tokens for both input and output. For production API use, the median price across providers sits at $0.30 input / $0.80 output per million tokens, with DeepInfra at $0.10 / $0.50 as the cheapest hosted option.
For local deployment, vLLM, SGLang, and TensorRT-LLM all support it. NVIDIA also packages the model as a NIM container - standardized inference with SLA-backed cloud options and a clear path to on-premises infrastructure. The NVIDIA NIM ecosystem is one of the practical advantages here for enterprise teams who want to run it privately.
"Nemotron 3 Super is by far the most intelligent model ever released with this level of openness." - Artificial Analysis
At 120B total parameters with 12B active, it can run on configurations most teams already have access to. On single-GPU setups with NVFP4, the DGX Spark can run it - as demonstrated by early community testing that ran the full model on a GB10 Superchip shortly after launch.
The Competitive Picture
Qwen 3 remains the better choice for teams that need broad capability - better on GPQA, better on the general intelligence index, with Apache 2.0 licensing. But it delivers that at roughly 40% of Nemotron 3 Super's throughput in production. If you're running high-volume inference pipelines, that difference in tokens-per-second per GPU translates directly to infrastructure cost.
Llama 4 Maverick - reviewed here - is a multimodal competitor with strong general reasoning but doesn't touch Super on SWE-bench or long-context retrieval. GPT-OSS-120B is closer on general benchmarks but falls behind on agentic tasks and context length.
The honest positioning is: if you're building a coding or software-development agent pipeline and you want open-weight models, there's nothing better available right now. If you need one model to handle everything from customer chat to scientific Q&A to code generation, Super is the wrong tool.
 NVIDIA unveiled Nemotron 3 Super at GTC 2026 with a broader agent stack including NemoClaw and the Nemotron Coalition with Mistral AI, Cursor, and Perplexity as founding members.
Source: blogs.nvidia.com
NVIDIA unveiled Nemotron 3 Super at GTC 2026 with a broader agent stack including NemoClaw and the Nemotron Coalition with Mistral AI, Cursor, and Perplexity as founding members.
Source: blogs.nvidia.com
Strengths
- SWE-bench Verified 60.47% - highest published score for any open model, by a wide margin over GPT-OSS-120B (41.90%)
- RULER@1M 91.75% vs 22.30% for GPT-OSS - the 1M context window actually works
- 5x throughput over the previous Nemotron Super, 2.2x over GPT-OSS-120B in production; 458-484 tokens/second on hosted APIs
- NVFP4 native training delivers 4x speedup on Blackwell over FP8 on Hopper while retaining 99.8% of BF16 accuracy
- Fully open weights, training data, and fine-tuning recipes - 83 on the Artificial Analysis Openness Index
- Wide deployment surface: NIM, vLLM, SGLang, TensorRT-LLM, free tier on OpenRouter
Weaknesses
- Arena-Hard-V2 at 73.88% vs GPT-OSS-120B's 90.26% - general chat quality is noticeably weaker
- GPQA 79.23% vs Qwen3.5-122B's 86.60% - broad scientific knowledge takes a back seat
- Tool calling reliability drops significantly when reasoning mode is disabled
- Model is excessively verbose, producing far more tokens per task than peer models at similar capability
- NVIDIA Nemotron Open Model License, not Apache 2.0 - includes patent termination clause
Verdict
Nemotron 3 Super is the model to use when you're building open-weight software agents and throughput matters. It leads every comparable open model on SWE-bench, long-context retrieval, and agentic task benchmarks. The hybrid Mamba-Transformer architecture and NVFP4 native training are real innovations that deliver measurable advantages, not marketing claims.
The weaknesses are real too. It's been optimized narrowly. If your stack requires general knowledge breadth, conversational quality, or reliable lightweight tool use without the reasoning overhead, look at Qwen3.5 or GPT-OSS instead. Super knows exactly what it is, which is both its strength and its limitation.
Score: 8.2/10 - the best open model for agentic coding pipelines, with clear gaps in general use.
Sources
- Introducing Nemotron 3 Super - NVIDIA Technical Blog
- Nemotron 3 Super Technical Report (PDF)
- NVIDIA Nemotron 3 Super: The new leader in open, efficient intelligence - Artificial Analysis
- Hands-On Evaluation of NVIDIA Nemotron 3 Super: Punching Above Its Weight Class - Greptile
- New NVIDIA Nemotron 3 Super Delivers 5x Higher Throughput for Agentic AI - NVIDIA Blog
- NVIDIA Nemotron 3 Super - Intelligence, Performance & Price Analysis - Artificial Analysis
- Nemotron 3 Super Pricing & Benchmarks - TokenCost
- nvidia/NVIDIA-Nemotron-3-Super-120B-A12B-BF16 - Hugging Face
- Nemotron 3 Super (free) - OpenRouter
- NVIDIA Nemotron 3 Super vs Qwen3.5 122B Comparison - Artificial Analysis
- NVIDIA Nemotron 3 Super vs Qwen3.5 122B Comparison - Artificial Analysis

