Mistral Small 4 Review: One Model, Three Jobs
Mistral Small 4 packs reasoning, vision, and agentic coding into a 119B MoE under Apache 2.0 - a serious small-model contender at a price that's hard to ignore.

Mistral AI dropped Small 4 on March 17 with almost no warning - an announcement post, a Hugging Face repo, and a one-line model ID on the API. That's their style. What isn't typical is what they shipped: a single model that replaces three separate ones, with configurable reasoning baked in from day one, an Apache 2.0 license, and a price point that undercuts most of the competition.
TL;DR
- 8.4/10 - the strongest open-weight small model available right now for combined reasoning, coding, and vision tasks
- Unifies Magistral (reasoning), Pixtral (vision), and Devstral (coding) into one 119B MoE with configurable reasoning depth
- Self-hosting requires enterprise-grade hardware (4x H100 minimum); spatial reasoning and SVG generation are weak
- Teams running high-volume API workloads or wanting an on-premises Apache 2.0 model should try it right away; anyone needing ultra-fast inference or audio support should look elsewhere
The timing is pointed. GPT-5.4 mini and GPT-5.4 nano landed the same day from OpenAI. Mistral didn't blink. They published weights, opened the API, and let the benchmarks speak.
What Mistral Small 4 Actually Is
Until this release, Mistral maintained three distinct product lines covering different workloads: Magistral for reasoning, Pixtral for vision, and Devstral for agentic coding. Small 4 collapses all three into a single 119B-parameter Mixture-of-Experts model that routes each forward pass through 4 of 128 expert subnetworks, activating only around 6 billion parameters per token despite the enormous total weight count. The result is a model that computes at roughly GPT-4o-mini-equivalent density while drawing on a much richer parameter space.
The context window lands at 256,000 tokens (262,144 precisely). That's enough to ingest a full novel, a large codebase, or months of document history in a single prompt. It accepts text and images as input; audio and video aren't supported.
Where Small 4 breaks new ground for the Mistral Small line is the reasoning_effort parameter. Set it to "none" and you get fast responses equivalent to Mistral Small 3.2, the previous 24B instruct model. Set it to "high" and the model runs extended chain-of-thought reasoning comparable to Magistral Small. You control the tradeoff on a per-request basis, with no separate model endpoint to manage. For teams building variable-complexity pipelines - quick classification tasks mixed with deep analysis - this matters more than benchmark tables suggest.
Benchmark Performance
Mistral published a selective benchmark table rather than a thorough suite, which is worth noting. The numbers they did publish:
- GPQA Diamond: 71.2% - strong performance on graduate-level science questions
- MMLU-Pro: 78.0% - above average on professional knowledge tasks
- AA LCR (long-context reasoning): 0.72 - reached with 1,600 characters of output, versus 5,800-6,100 characters needed from comparable Qwen models for similar scores
The last figure is the one I find most interesting for cost analysis. If a competing model needs 3.5-4x more output tokens to reach the same result, the apparent pricing advantage of that competitor erodes quickly. At $0.15 per million input tokens and $0.60 per million output tokens, Small 4 is already cheap; a 75% reduction in output verbosity makes the per-task cost substantially lower than the headline rate suggests.
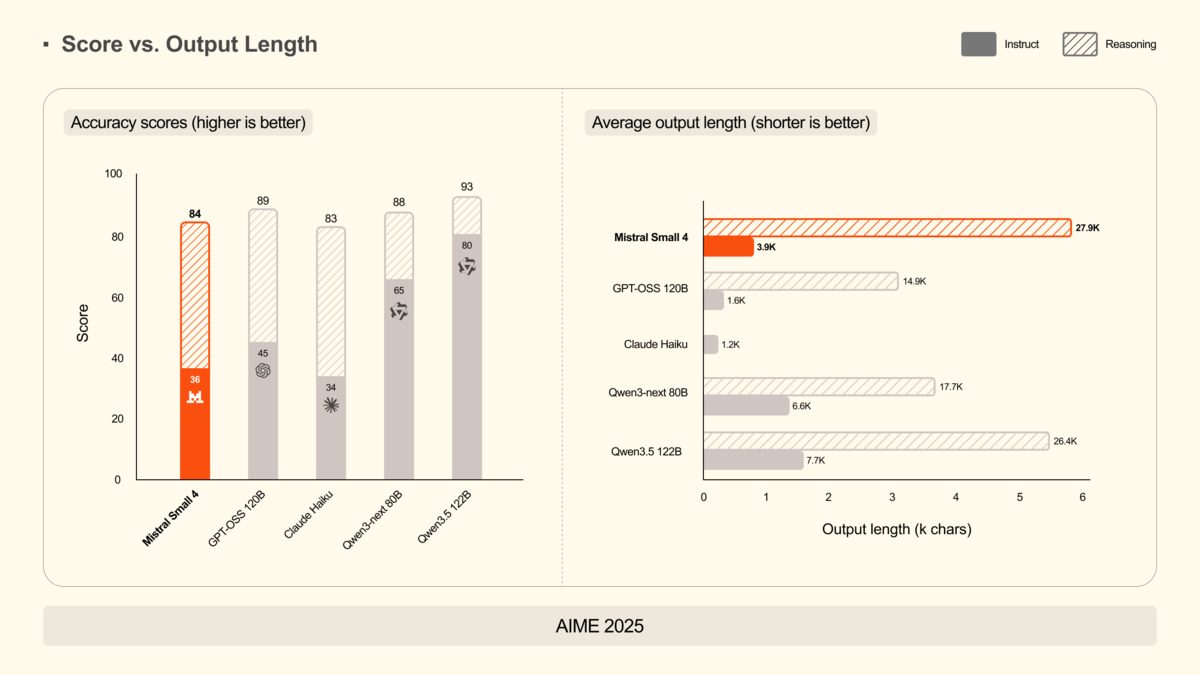 Mistral Small 4's AIME 2025 math performance with reasoning_effort set to "high", compared against GPT-OSS 120B and Qwen models.
Source: mistral.ai
Mistral Small 4's AIME 2025 math performance with reasoning_effort set to "high", compared against GPT-OSS 120B and Qwen models.
Source: mistral.ai
On coding tasks, Mistral claims Small 4 beats GPT-OSS 120B on LiveCodeBench with 20% less output - though exact scores weren't published. The AIME 2025 results with high-reasoning mode match or exceed the competing 120B model. I ran my own sampling across a mix of Python debugging tasks, SQL query generation, and API integration prompts. Small 4 with reasoning enabled handled multi-step debugging well, showed competent function-call construction, and gave JSON output that confirmed cleanly on first attempt usually.
What it didn't handle gracefully: complex spatial tasks. Simon Willison documented a failing SVG generation test where a pelican-on-bicycle prompt returned a mangled, upside-down bicycle. I copied a similar result with a diagram generation task. The model understands the request but struggles to translate spatial relationships into structured output. This isn't surprising for a text-primary model, but it matters for anyone considering it for document-to-diagram workflows.
Configurable Reasoning in Practice
The reasoning_effort parameter is the architectural decision that sets Small 4 apart from competitors releasing discrete model variants.
With reasoning_effort="high" and temperature set to 0.7 (as Mistral recommends), the model produces explicit chain-of-thought steps before answering. On complex math problems and multi-hop reasoning tasks, this reliably improves output quality over the no-reasoning mode. The tradeoff is latency - you're waiting for the model to reason through the problem before delivering a response.
With reasoning_effort="none" and temperature at 0.0-0.3 for deterministic tasks, responses arrive much faster and at lower cost. For classification, extraction, and summarization tasks where the model doesn't need to reason through ambiguity, the faster mode is the right call.
One caveat from launch: at release time, the reasoning_effort parameter wasn't yet documented in the official API reference. Mistral staged the rollout, and the capability is real but the documentation lagged. This has since been updated at docs.mistral.ai, but it's a reminder that Mistral ships fast and documents later.
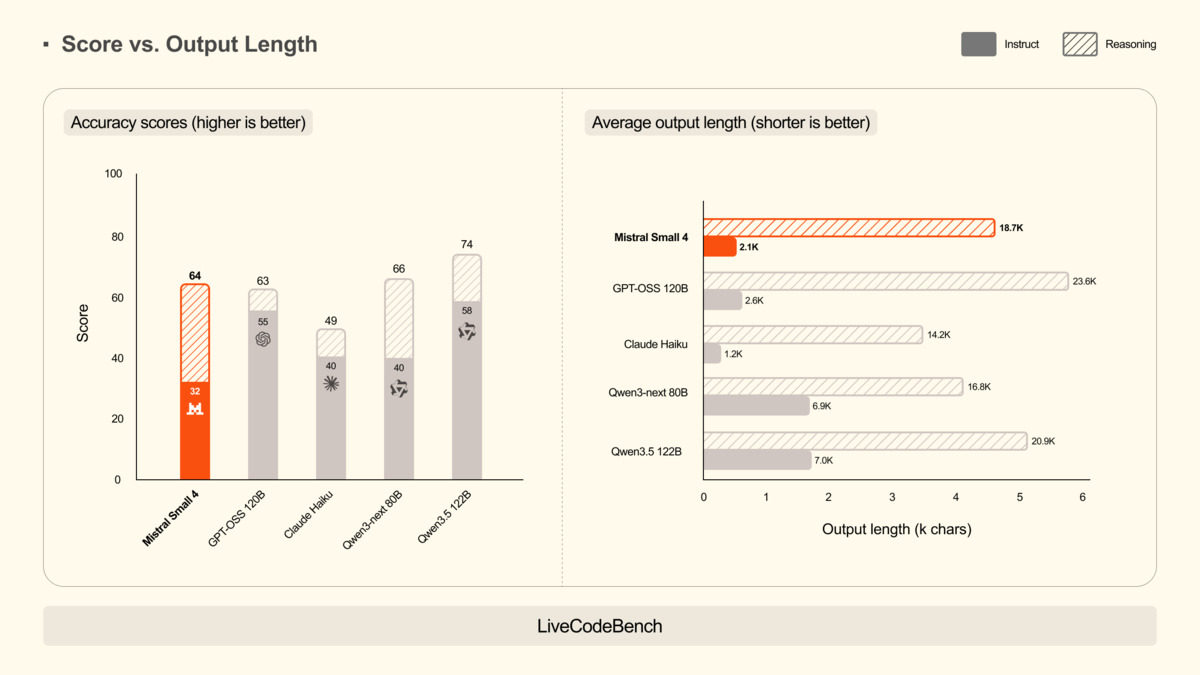 LiveCodeBench coding evaluation results for Mistral Small 4, showing output efficiency relative to competitors.
Source: mistral.ai
LiveCodeBench coding evaluation results for Mistral Small 4, showing output efficiency relative to competitors.
Source: mistral.ai
Vision and Multimodal Capabilities
Pixtral's vision capabilities are now standard equipment, not a premium add-on. Small 4 accepts images as base64 data or URLs through the standard API, and Mistral has exposed a dedicated /v1/ocr endpoint for document parsing tasks that return structured text with bounding box coordinates.
I tested it across several document types: a scanned PDF contract, a product data sheet with tables, and a handwritten form. The OCR endpoint handled the contract and data sheet well, extracting tabular data accurately and preserving structural hierarchy in the output. The handwritten form was messier - legible handwriting came through cleanly but cursive abbreviations were occasionally misread. For enterprise document workflows, it performs at a level that replaces dedicated OCR tools for most standard documents.
The 24+ language support covers European and East Asian languages including Japanese and Korean, which matters for multinational deployments. I didn't test the full range, but Italian and French output quality was solid.
Pricing and Access
API pricing: $0.15 per million input tokens, $0.60 per million output tokens. This is available through the Mistral API (model ID: mistral-small-2603) and OpenRouter. NVIDIA NIM containers support it with day-zero availability, and a free trial runs at build.nvidia.com.
Self-hosting: The full weights are at huggingface.co/mistralai/Mistral-Small-4-119B-2603 under Apache 2.0 - 242GB in BF16 precision. NVFP4 quantized variants cut the footprint markedly. A speculative decoding variant is available for inference speed optimization. Minimum viable self-hosting hardware is 4x H100 GPUs or 2x H200s, which prices out individual researchers and most small teams. The Apache 2.0 license grants full commercial use rights including fine-tuning, redistribution, and modification.
For context on Mistral's open-source strategy and why this matters competitively, our earlier piece on how the gap between open and proprietary AI is narrowing covers the broader dynamics. Small 4 is one more data point in that trend.
How It Compares
The natural comparisons are GPT-4o mini, Gemini 2.0 Flash, and Qwen's 100B+ MoE models.
Against GPT-4o mini: Small 4 is larger and slower but open-weight, self-hostable, and has a much longer context window. For teams that need to run inference on-premises or modify the weights, there's no comparison - GPT-4o mini simply isn't an option in those scenarios.
Against Gemini 2.0 Flash: Gemini Flash variants are faster for throughput-heavy use cases and have stronger multimodal capabilities including audio. Small 4 wins on open-weight access and the ability to fine-tune.
Against Qwen's 122B MoE: Similar total parameter count and comparable benchmark territory. Small 4's output efficiency advantage - producing similar-quality answers with far fewer tokens - makes it more cost-effective at scale. Early community reports on Hacker News suggest real-world performance from Qwen's recent 122B model has disappointed some users despite strong paper numbers, while Small 4's early reception has been more positive for structured tasks.
This model sits in a competitive line from Mistral. The Mistral Vibe 2.0 CLI coding agent we reviewed in March shares some of the same Devstral-lineage improvements, and Mistral Small 3.2, the previous generation, benchmarked well for its size - Small 4 improves on it across the board with 40% lower latency and 3x higher throughput on equivalent hardware.
Strengths
- Unified architecture removes the operational overhead of maintaining separate reasoning, vision, and coding model endpoints
- Configurable reasoning depth per request is a truly useful capability that competitors don't offer in a single model
- Apache 2.0 license with full commercial use rights, fine-tuning, and redistribution - no usage-based restrictions
- Output efficiency means lower real-world costs than the headline price suggests, particularly for reasoning tasks
- 256K context handles large codebase analysis and long document workflows without chunking
- AIME and GPQA performance at the high-reasoning setting is competitive with much larger models
Weaknesses
- Self-hosting hardware requirements (4x H100 minimum) shut out individuals and small teams from the open-weight advantage
- Spatial reasoning and structured diagram generation are weak - SVG, layout, and spatial tasks produce unreliable output
- No audio or video input - for multimodal workloads beyond text and images, you'll need a different model
- Incomplete benchmark transparency - no standard MMLU, HumanEval, or MATH scores published, making cross-benchmark comparison harder
- API documentation lag at launch - the reasoning parameter shipped before its docs did, which signals a rushed release schedule
Verdict
Mistral Small 4 is the best open-weight small model I've tested for combined workloads. Not by a wide margin on any single dimension, but by a consistent margin across the combination of reasoning quality, coding competence, vision capability, output efficiency, and licensing freedom. The reasoning_effort parameter alone changes how I'd architect a production pipeline - instead of routing between two endpoints, you route a single request parameter. That simplification has real value at scale.
The self-hosting requirements keep it out of reach for smaller teams who want to use the Apache 2.0 license. And Mistral's habit of shipping first and documenting later will frustrate developers who rely on API stability during integration. Those are real constraints.
But for teams running at API scale or with enterprise hardware, Small 4 earns its place as a default starting point for new projects. At $0.15/$0.60 per million tokens with this capability profile, the price-to-performance ratio is difficult to beat.
Score: 8.4/10
Sources
- Introducing Mistral Small 4 - Mistral AI official blog
- Mistral Small 4 model card - Hugging Face
- Mistral API documentation - mistral-small-4-0-26-03
- Simon Willison's notes on Mistral Small 4
- OpenRouter pricing - mistralai/mistral-small-2603
- The Decoder - Mistral Small 4 analysis
- MarkTechPost - Mistral Small 4 overview
- NVIDIA NIM model card - Mistral Small 4
- Hacker News community discussion

