MiniMax M3 Review: The Price Disruptor with Caveats
MiniMax M3 arrives as the first open-weight model to combine frontier coding, 1M-token context, and native multimodality - at a fraction of proprietary pricing - but every benchmark figure is self-reported and the weights weren't even shipped at launch.

A task that burns $5 on Claude Opus 4.8 costs about $0.27 on MiniMax M3 at launch-week pricing. That single number explains why M3 produced more developer discussion in its first 72 hours than any Chinese open-weight model since DeepSeek V3. The harder question - whether the performance justifies routing your production workloads through a Shanghai-based API - is more complicated.
TL;DR
- 7.5/10 - genuine cost edge and novel sparse attention, but every benchmark is vendor-run and weights weren't shipped at launch
- 1M-token context via MSA sparse attention at $0.60/M input tokens - roughly 10x cheaper than comparable frontier models
- MiniMax benchmarked M3 against Opus 4.7, which had already been superseded by Opus 4.8 three days earlier
- Use if cost-sensitive long-context coding is the priority; skip if Chinese data jurisdiction is a compliance concern
MiniMax released M3 on June 1, 2026, claiming it's the first open-weight model to combine three properties simultaneously: frontier-tier coding, a one-million-token context window, and native multimodal input. Those are credible differentiators for an open-weight model. Whether M3 actually delivers on them depends on which numbers you trust - and right now, the only numbers available are MiniMax's own.
The Architecture: Why It's Actually Interesting
The headline technology is MiniMax Sparse Attention, which the company calls MSA. Standard transformer attention is quadratic in sequence length: double the context and attention cost quadruples. MSA replaces that with a two-stage mechanism. A lightweight index branch scans the incoming tokens first, selects which key-value cache blocks are actually relevant, and only then runs the expensive attention math on those blocks.
The result at 1M context is roughly 9.7x faster prefill and 15.6x faster decoding versus M2, with per-token compute at about one-twentieth of the previous generation. MiniMax trained M3 on over 100 trillion tokens with multimodal data interleaved from pretraining - not tacked on at fine-tuning - which is a meaningful distinction for models handling image and video inputs.
None of this is verifiable yet. The technical report and open weights were promised within ten days of launch, targeting Hugging Face around June 11. Until those ship, MSA's claimed efficiency gains are taking MiniMax's word for it.
The Benchmark Problem
M3's launch benchmarks are the most complicated part of this review.
On SWE-Bench Pro - a coding eval that tests autonomous resolution of real GitHub issues - M3 scores 59.0%. That beats GPT-5.5 (58.6%) and Gemini 3.1 Pro (54.2%). On BrowseComp, which measures autonomous web research, M3 scores 83.5, edging out Claude Opus 4.7's 79.3. On MCP Atlas, a multi-tool agent evaluation, it hits 74.2%.
The problems start when you look at how those numbers were produced.
Every figure in MiniMax's launch materials was run on MiniMax's own infrastructure, using agent scaffolding MiniMax configured, with baselines MiniMax selected. That's not an accusation of fraud - it's just how vendor benchmarks work, and the same caveat applies to Anthropic and OpenAI at launch. Independent evaluations from Artificial Analysis and LMArena were still pending at publication.
There's a second problem. MiniMax benchmarked M3 against Claude Opus 4.7. Opus 4.8 had shipped three days before M3's launch. At the Opus 4.8 baseline, M3's SWE-Bench Pro gap grows: 59.0% versus 69.2%. On Terminal-Bench (M3 used version 2.1; competitors were measured on 2.0, making direct comparison unreliable), M3 scores 66.0% against Opus 4.8's 74.6% on the prior version. OSWorld-Verified shows 70.06% for M3 versus 83.4% for Opus 4.8 on GUI automation tasks.
The benchmark comparison looks better against a model that was already outdated when M3 launched. Whether that was oversight or strategy, MiniMax didn't flag it.
| Benchmark | MiniMax M3 | GPT-5.5 | Gemini 3.1 Pro | Claude Opus 4.8 |
|---|---|---|---|---|
| SWE-Bench Pro | 59.0% | 58.6% | 54.2% | 69.2% |
| Terminal-Bench (2.1) | 66.0% | - | - | 74.6% (v2.0) |
| OSWorld-Verified | 70.06% | - | - | 83.4% |
| BrowseComp | 83.5 | - | - | - |
| GPQA Diamond | 92.68% | - | 94.3% | - |
| PostTrainBench (overall) | #3 | #2 | - | #1 |
Note: Terminal-Bench scores for M3 (v2.1) and Opus 4.8 (v2.0) are different versions of the benchmark and can't be compared directly.
What M3 actually shows at launch: it sits in the same tier as GPT-5.5 on SWE-Bench Pro, and ahead of Gemini 3.1 Pro on coding. For an open-weight model at this pricing, that's a real achievement. It doesn't match Opus 4.8 on autonomous software tasks, and the vendor-run nature of every figure means developers should run their own evals before committing production workloads.
What the Demos Actually Show
MiniMax published three autonomous capability demonstrations with M3. Two of them are truly striking.
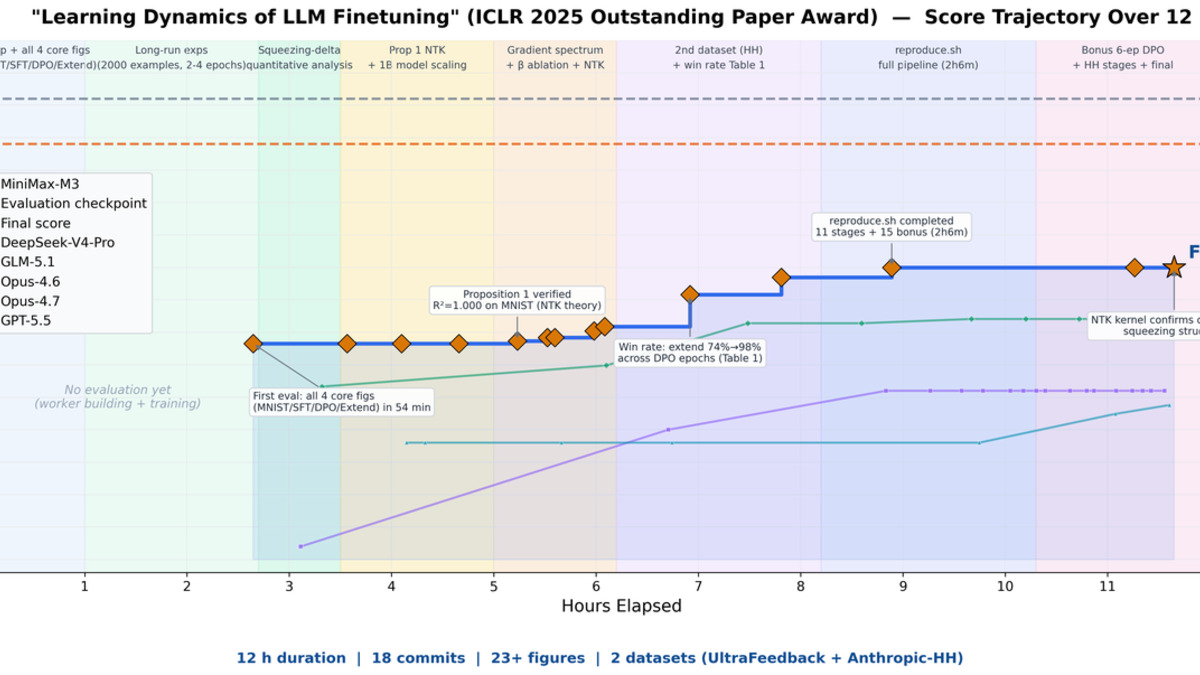 M3's autonomous paper reproduction: 18 commits, 23 experimental figures over a 12-hour run, recreating an ICLR 2025 result from scratch without human intervention.
Source: minimax.io
M3's autonomous paper reproduction: 18 commits, 23 experimental figures over a 12-hour run, recreating an ICLR 2025 result from scratch without human intervention.
Source: minimax.io
The first is an ICLR 2025 paper reproduction. Over 12 hours, M3 ran data synthesis, training, evaluation, and iterative refinement - generating 18 commits and 23 figures - without human intervention. The second is a CUDA kernel optimization task: M3 improved hardware utilization on Hopper architecture from 7.6% to 71.3% over 147 attempts, a task MiniMax says normally takes an engineer one to two weeks.
These aren't benchmark scores. They're capability demonstrations designed to show long-context agentic behavior under realistic workloads. They're compelling, and they also can't be independently verified yet. Whether M3 reproduces those results on your codebase and your tasks is the only test that actually matters.
The 1M-token context matters specifically for these kinds of long-horizon tasks. Most frontier API models cap at 128K-200K tokens. Loading a large codebase, its test suite, and several rounds of execution history into a single context without chunking is a different category of capability. SubQ takes this further with a 12M-token subquadratic architecture, but it's at an earlier commercial stage.
Pricing: The Real Story
The $0.27 versus $5.00 comparison circulating in developer discussions comes from launch-week promotional pricing. MiniMax offered a 50% discount on standard rates for the first week after launch.
Standard rates: $0.60/M input tokens, $2.40/M output tokens. Against Claude Opus 4.8 at roughly $6-8/M input at high volumes, M3 is around 10x cheaper on input at standard pricing. That's still a meaningful advantage - just not the 15-25x headline figure that was calculated using the temporary promo rate.
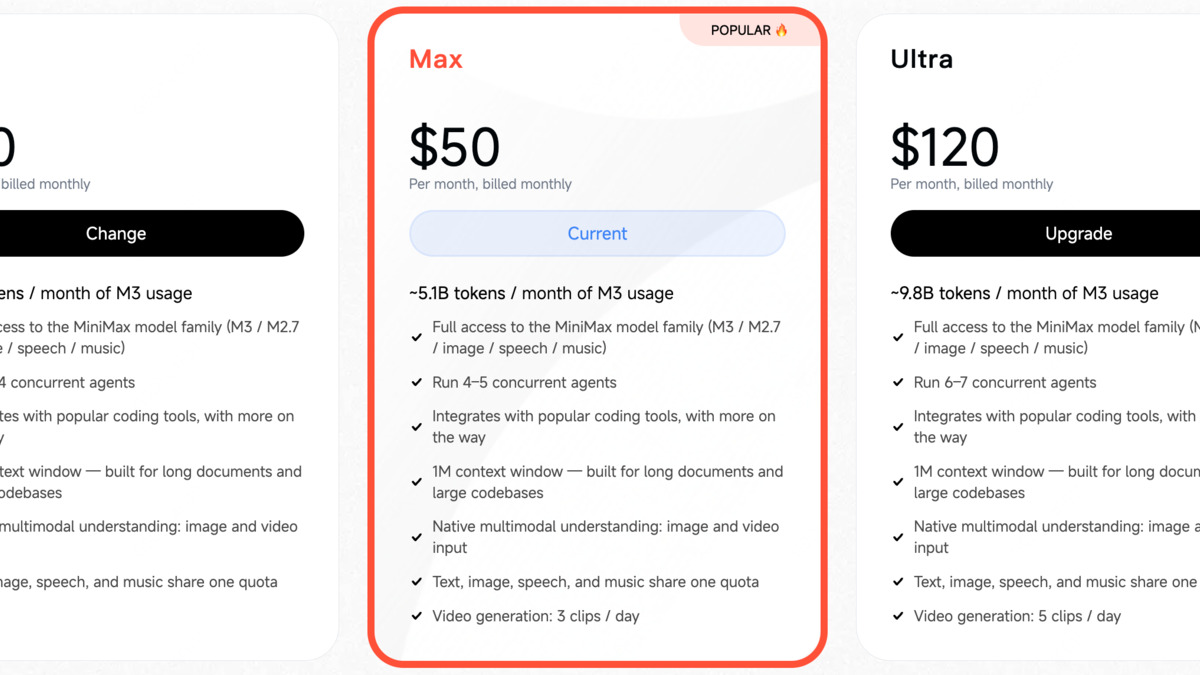 MiniMax M3 token plans: $20/month (Plus), $50/month (Max), $120/month (Ultra). Text, image, speech, and music share the same token pool.
Source: minimax.io
MiniMax M3 token plans: $20/month (Plus), $50/month (Max), $120/month (Ultra). Text, image, speech, and music share the same token pool.
Source: minimax.io
One detail that gets less attention: the 512K token surcharge. Standard pricing applies to inputs up to 512K tokens. Push beyond that into M3's extended context range and a higher rate kicks in. MiniMax hasn't published the surcharge multiplier publicly. For workloads that actually use the 1M-token window, the cost comparison against Opus narrows.
Subscription plans - Plus at $20/month, Max at $50/month, Ultra at $120/month - pool tokens across text, image, speech, and music. If your use case is purely coding, the per-token API pricing is likely more predictable.
Multimodal Input
M3 accepts text, image, and video inputs, with output in text only. The multimodal support is natively trained from pretraining rather than appended at fine-tuning, which matters for how coherently the model integrates visual and textual reasoning.
MiniMax reports M3 scores above Gemini 3.1 Pro on OmniDocBench and above Claude Opus 4.7 on SVG-Bench. Desktop computer operation - clicking, scrolling, interacting with GUI applications - is also claimed. Again, these are self-reported scores using MiniMax's own infrastructure.
For agentic AI applications that process documents with code, native multimodality at this pricing is a real differentiation. Most open-weight coding-focused models don't handle image or video at all.
The Open-Weight Question
MiniMax called M3 "open-weight" at launch. The weights weren't available at launch. The technical report wasn't available. Both are promised within ten days, targeting around June 11.
This is an unusual launch posture. Releasing an API and calling the model open-weight before shipping the weights means developers can't run the model privately, can't fine-tune it, and can't verify any of the architectural claims. It also means the license terms - which matter markedly for commercial use - are unknown until the weights land.
MiniMax's previous model, M2.7, shipped with a license restricting commercial use without written authorization from MiniMax. If M3 follows the same pattern, enterprise teams building on top of it need explicit sign-off before going to production. Read the license before building anything.
The self-hosted deployment case is also the answer to the data jurisdiction problem.
Data Jurisdiction
China's 2017 National Intelligence Law requires every Chinese company - including MiniMax - to cooperate with state intelligence requests. That obligation applies continuously, covers all data processed through MiniMax's infrastructure regardless of server location, and provides no legal pathway for MiniMax to refuse a government request.
For workloads involving proprietary source code, customer data, regulated health or financial information, or anything that would be sensitive if accessed by a foreign government, routing it through the MiniMax API carries material compliance risk. The American Enterprise Institute flagged MiniMax specifically in April 2026 analysis of this issue.
This isn't a reason to dismiss M3 completely. It is a reason to use the open weights on your own infrastructure once they ship, rather than the API, if the data sensitivity is real. The MiniMax M2.7 review covers similar considerations for the predecessor.
Strengths and Weaknesses
Strengths:
- Competitive SWE-Bench Pro score (59%) at a fraction of frontier proprietary pricing
- MSA architecture delivers genuine long-context efficiency gains if the technical claims verify
- Native multimodal training from pretraining, not a fine-tuned add-on
- BrowseComp score of 83.5 beats published Opus 4.7 figures on autonomous web tasks
- Strong autonomous demo results for long-horizon coding tasks
Weaknesses:
- All launch benchmarks self-reported; independent verification was pending at publication
- Weights and technical report not shipped at launch despite "open-weight" branding
- Benchmarked against Opus 4.7, not Opus 4.8, creating a misleading head-to-head
- Terminal-Bench version mismatch makes direct score comparisons unreliable
- Chinese API jurisdiction: National Intelligence Law applies to all prompt traffic
- 512K surcharge applies above the guaranteed context minimum; pricing at full 1M context is unclear
Verdict
MiniMax M3 is the most interesting cost-efficiency bet on the frontier coding market right now. If the benchmark numbers hold up under independent evaluation - a meaningful if - it offers SWE-Bench Pro performance in the GPT-5.5 tier at 10x lower input pricing. The MSA architecture, if the technical report confirms the claimed efficiency, addresses a real problem in long-context inference.
What it isn't: a validated drop-in replacement for Opus 4.8. The gap on autonomous software tasks is real (59% vs 69.2% on SWE-Bench Pro). The benchmarking against an already-superseded Opus version was either an oversight or a choice, and neither reflects well on the launch. The weights not shipping at launch is odd for a company calling this an open-weight release.
The practical read: watch for the weights around June 11. If the technical report confirms the MSA efficiency claims and the license permits commercial use, M3 becomes a serious option for teams doing cost-sensitive long-context agentic work on non-sensitive data. For teams with compliance exposure to Chinese data jurisdiction, wait for the open weights and self-host.
Score: 7.5 / 10
See the MiniMax M3 model profile for full specs, benchmark tables, and pricing details. For background on MiniMax's approach to autonomous model training, see our M2.7 coverage.
Sources
- MiniMax M3 Official Blog Post - Launch announcement with architecture details, benchmarks, and availability
- The Decoder: MiniMax M3 open-weight model challenges proprietary leaders - Technical overview and benchmark context
- TechTimes: MiniMax M3 - Frontier Claims, Unverified Benchmarks - Critical analysis of self-reported benchmark methodology
- DataNorth: MiniMax Launches M3 with 1M Context - Coverage of pricing and positioning at launch
- Lushbinary: MiniMax M3 Developer Guide - Benchmarks and Pricing - Developer-focused breakdown of MSA and API pricing structure
- Medium / Cogni Down Under: I Evaluated MiniMax M3 for Agentic Workflows - Independent evaluation findings and real-world testing caveats
- TechTimes: Chinese AI Models Lead OpenRouter Traffic - Data Risk - Context on Chinese AI data jurisdiction and enterprise compliance
- Kingy AI: MiniMax M3 Specs and Benchmarks - Benchmark compilation and model positioning
- OpenRouter: MiniMax M3 listing - Current API pricing and availability
- MarkTechPost: MiniMax Releases MiniMax M3 with MSA Architecture - Technical summary of MSA architecture claims
