MiniMax M2.5 Review: Frontier Code at Bargain Cost
MiniMax M2.5 matches Claude Opus 4.6 on SWE-Bench at 1/20th the price - but a spike in hallucinations and a distillation controversy complicate the story.

MiniMax M2.5 lands on the pricing floor that frontier AI has been approaching for years. Released on February 12, 2026, it scores 80.2% on SWE-Bench Verified - 0.6 percentage points behind Claude Opus 4.6 - while costing roughly $1.20 per million output tokens versus Opus's $25. That's not a rounding error. That's a different economic universe.
TL;DR
- 7.8/10 - Exceptional cost-performance ratio for coding and agentic tasks, held back by a meaningful regression in factual reliability
- Best-in-class SWE-Bench score among open-weight models (80.2%), matching proprietary frontier models at a fraction of the price
- Hallucination rate jumped from 67% to 88% generation-over-generation - a serious reliability concern for factual work
- Developers building coding agents or agentic pipelines who need to control costs; skip it if you need strong math reasoning or reliable factual retrieval
But this isn't a clean win. Artificial Analysis measured an 88% hallucination rate on their AA-Omniscience evaluation, up from 67% with M2.1. The model's maker, Shanghai-based MiniMax, also became the subject of a major industry controversy when Anthropic accused it of using over 13 million synthetic Claude interactions to train M2.5, creating them through 24,000 fraudulent accounts. Both details matter when evaluating whether this model belongs in your stack.
What MiniMax M2.5 Actually Is
MiniMax is a Chinese AI lab founded in 2021 by researchers from SenseTime. It raised $619 million in a Hong Kong IPO in January 2026, backed by Alibaba and Tencent. The M2.5 model is the company's third generation in this series, following M2 and M2.1.
The architecture is Mixture-of-Experts: 230 billion total parameters, 10 billion active during inference. That active parameter count is why the pricing is so low - inference costs scale with active parameters, not total ones. The context window is 200K tokens, and MiniMax ships two API variants: M2.5 Standard at roughly 50 tokens per second and M2.5-Lightning at 100 tokens per second.
Weights are released on HuggingFace under a Modified-MIT license, which allows commercial use, self-hosting, and fine-tuning. The catch is hardware: unquantized at 457GB, you're looking at multi-GPU setups to self-host. Unsloth has GGUF quantizations available - a 3-bit dynamic version at 101GB fits on a 128GB unified-memory Mac with around 20-25 tokens per second throughput.
The training story is interesting. MiniMax built a framework called Forge - an agent-native reinforcement learning system that decouples the training loop from the agent's internal state. The key innovation is that it reaches about 40x training throughput by running RL training across hundreds of thousands of real-world environments at context lengths up to 200K tokens, maintaining millions of samples per day. The algorithm used is CISPO, a method MiniMax carried over from M2.1 to keep MoE training stable.
Coding and Agentic Performance
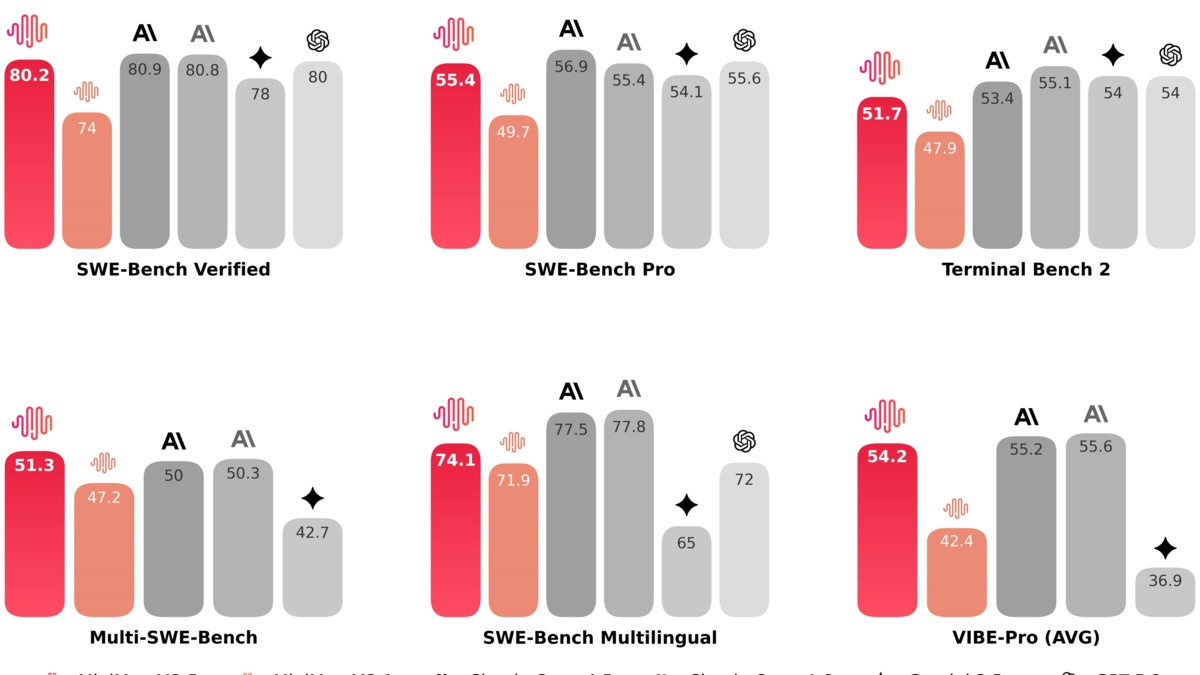 Coding benchmark comparison from MiniMax's official announcement. M2.5 sits within 0.6 points of Claude Opus 4.6 on SWE-Bench Verified while leading on Multi-SWE-Bench and Droid.
Source: minimax.io
Coding benchmark comparison from MiniMax's official announcement. M2.5 sits within 0.6 points of Claude Opus 4.6 on SWE-Bench Verified while leading on Multi-SWE-Bench and Droid.
Source: minimax.io
The headline number is 80.2% on SWE-Bench Verified. For context, as we track in our coding benchmarks leaderboard, SWE-Bench Verified scores above 75% now represent a small cluster of frontier models. M2.5 sits in that cluster as the highest-scoring open-weight model by a clear margin.
It doesn't stop at raw score. The model completed the SWE-Bench evaluation 37% faster than its predecessor M2.1 - 22.8 minutes average versus 31.3 minutes - while consuming 20% fewer agentic rounds and 3.52 million tokens versus 3.72 million per task. On Multi-SWE-Bench, it scores 51.3%, beating Claude Opus 4.6's 50.3%.
Tool calling is genuinely impressive. BFCL Multi-Turn, which measures multi-step function calling across complex API schemas, lands at 76.8% for M2.5 versus 63.3% for Opus 4.6. That's a 13.5 point gap for the cheaper model. In practice, this shows up in agents that maintain clean state across many sequential tool calls without losing context or confabulating intermediate results.
OpenHands, the open-source agentic framework, published testing results after M2.5's release and found it competitive with Claude Sonnet-class performance on multi-file development tasks. Their assessment was that M2.5 "delivers a flawless closed-loop system and proactively adds value-add features" during long-running tasks. That's a significant claim for a model at this price point.
MiniMax itself reports that 80% of new code committed internally is now generated by M2.5, and 30% of company tasks generally use M2.5. These are vendor claims and should be weighted accordingly, but they align with the benchmark picture.
The Price Math
M2.5 Standard costs $0.15 per million input tokens and $1.20 per million output tokens. Claude Opus 4.6 runs $5.00 per million input and $25.00 per million output. Gemini 3.1 Pro, which I reviewed in our Gemini 3.1 Pro coverage, charges $2.00 per million input and $8.00 per million output.
For a typical agentic coding workload - say 10 million input tokens and 2 million output tokens per day - M2.5 Standard costs roughly $4.70/day. Opus 4.6 costs roughly $100/day. Gemini 3.1 Pro costs about $36/day.
M2.5 Lightning doubles both price and throughput: $0.30 per million input, $2.40 per million output, 100 tokens/second. MiniMax's marketing claim - "intelligence too cheap to meter" - is hyperbole, but the hourly cost of $1 at full throughput is a real number worth sitting with.
Our cost efficiency leaderboard tracks these metrics across models. M2.5 Standard currently holds one of the best price-performance ratios among frontier-class models by any reasonable measure.
The open-weights release adds another economic dimension. If you have the hardware and the ops appetite, you can self-host M2.5 and reduce marginal inference costs to electricity and hardware amortization. For high-volume production workloads, that calculus is worth running.
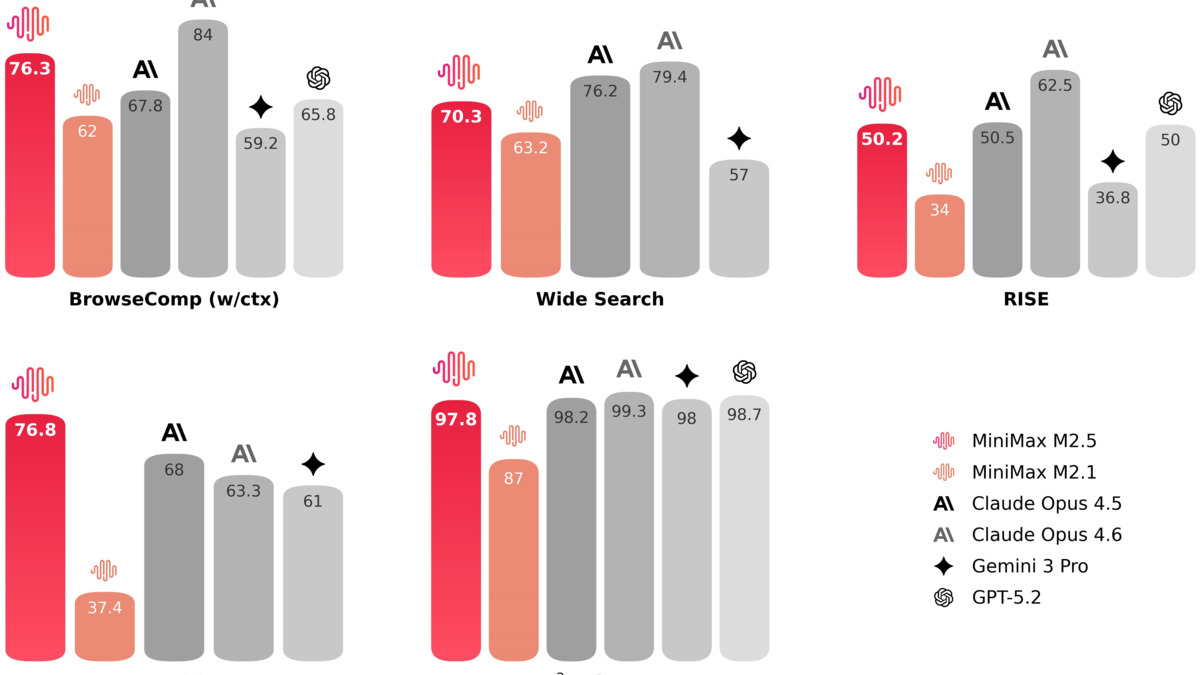 MiniMax M2.5's tool-calling and search benchmarks versus Claude Opus 4.6. The 13.5-point gap on BFCL Multi-Turn is the headline figure for agentic workflows.
Source: minimax.io
MiniMax M2.5's tool-calling and search benchmarks versus Claude Opus 4.6. The 13.5-point gap on BFCL Multi-Turn is the headline figure for agentic workflows.
Source: minimax.io
Where It Struggles
The hallucination regression is the most significant weakness. Artificial Analysis measured M2.5's AA-Omniscience Index at -41, down from M2.1's -30. Their evaluation puts the hallucination rate at 88%, up from 67% in the previous generation. That's not a subtle decline - it's the model becoming meaningfully less reliable on factual questions compared to what it replaced.
For coding and agentic tasks, this matters less directly: code either runs or it doesn't, and the model's strong agentic scores suggest it handles execution feedback well. But for any workflow where the model creates factual claims, retrieves information, or writes content alongside code, the hallucination rate is a real liability.
Pure reasoning is another gap. On AIME 2025, M2.5 scores 86.3, compared to 95.6 for Claude Opus 4.6, 96.0 for Gemini 3 Pro, and 98.0 for GPT-5.2. That's a 9-12 point gap on hard math reasoning. GPQA Diamond shows a similar pattern: 85.2 for M2.5 against 90.0 for Opus 4.6. The model isn't optimized for this kind of work and doesn't pretend to be.
On the Artificial Analysis Intelligence Index, M2.5 scores 42, compared to 57 for both Gemini 3.1 Pro and GPT-5.4, and 53 for Claude Opus 4.6. That's a more complete picture of overall capability than SWE-Bench alone.
Verbosity is also worth flagging. Artificial Analysis measured M2.5 producing 56 million tokens during their Intelligence Index evaluation, compared to a median of about 16 million across models. That's not a safety concern, but it inflates effective costs in ways the headline pricing doesn't reflect.
Finally: M2.5 is text-only. No image input, no multimodal capabilities. If your agent workflows involve screenshots, diagrams, or visual debugging, you need a different model.
The Distillation Controversy
No review of M2.5 can honestly omit what Anthropic reported in February 2026. As we covered in detail, Anthropic published evidence that MiniMax, with DeepSeek and Moonshot AI, ran what it called a systematic "distillation attack" against Claude. The accusation: MiniMax created over 24,000 fraudulent accounts and generated more than 13 million interactions with Claude to harvest training data for M2.5.
Anthropic noted that when it released a new model during MiniMax's active campaign, MiniMax "pivoted within 24 hours, redirecting nearly half their traffic to capture capabilities from our latest system."
MiniMax hasn't publicly confirmed or denied the specifics. The legal and technical lines around distillation are contested - AI companies routinely distill their own models, and the question of what counts as unauthorized extraction versus legitimate API use isn't settled. But the scale described isn't ambiguous. If Anthropic's evidence is accurate, M2.5's performance on tasks where it matches Claude is less surprising.
This doesn't invalidate M2.5 as a product. If the model works, it works. But it does inform how you interpret benchmark comparisons against Anthropic's models specifically.
Strengths and Weaknesses
Strengths
- 80.2% SWE-Bench Verified - highest of any open-weight model, competitive with proprietary frontier
- Output tokens at $1.20/M - roughly 20x cheaper than Claude Opus 4.6 on output
- BFCL Multi-Turn at 76.8% - meaningfully outperforms Claude Opus 4.6 on function calling
- Open weights under Modified-MIT - commercial use, self-hosting, fine-tuning allowed
- M2.5-Lightning at 100 tok/s sustained throughput - fast for high-volume pipelines
- 37% faster agentic task completion versus M2.1, with fewer tokens consumed per task
Weaknesses
- Hallucination rate up to 88% from 67% (M2.1) - significant regression in factual reliability
- AIME 2025 at 86.3 trails frontier reasoning models by 9-12 points
- No image input - text-only model limits multimodal agent workflows
- Verbose outputs inflate effective costs relative to headline pricing
- Benchmark trust concerns - community skepticism around MiniMax's history, plus the distillation accusation
- 457GB unquantized - self-hosting requires serious infrastructure investment
Verdict
MiniMax M2.5 is the most cost-effective coding agent I've tested at this performance tier. For teams running high-volume agentic coding pipelines, the economics are difficult to argue with: near-Opus-level SWE-Bench performance at a fraction of the price, open weights, and a credible RL training approach in Forge.
The caveats are real. The hallucination regression is a genuine reliability concern that makes M2.5 a poor fit for any workflow that mixes factual retrieval with code generation. The distillation controversy doesn't break the product, but it should inform how you think about the benchmarks. And on reasoning-heavy tasks - hard math, scientific knowledge, anything requiring deep chain-of-thought - the model is clearly behind the frontier proprietary tier.
My recommendation: if coding and agentic tool use are your primary use cases, and you're currently running Claude Opus 4.6 or Gemini 3.1 Pro, MiniMax M2.5 is worth a serious benchmark against your actual workload. You might cut your inference bill by 80-95% without a meaningful performance drop on the tasks that matter to you. If you need factual reliability or hard reasoning with coding, stay with a proprietary model or run M2.5 as a draft layer with a higher-reliability model for verification.
Score: 7.8/10
Sources
- MiniMax M2.5: Built for Real-World Productivity - Official Announcement
- MiniMaxAI/MiniMax-M2.5 - Hugging Face Model Card
- MiniMax-M2.5: Everything You Need to Know - Artificial Analysis
- MiniMax-M2.5 Performance and Price Analysis - Artificial Analysis
- MiniMax's new open M2.5 near state-of-the-art while costing 1/20th of Claude Opus 4.6 - VentureBeat
- MiniMax M2.5: Open Weights Models Catch Up to Claude Sonnet - OpenHands
- Anthropic accuses DeepSeek, Moonshot and MiniMax of distillation attacks - TechCrunch
- MiniMax M2.5 Released: 80.2% on SWE-Bench - Hacker News Discussion
- Forge: Scalable Agent RL Framework - MiniMax
- MiniMax raises $619M in Hong Kong IPO - SiliconANGLE
- MiniMax M2.5: How to Run Guide - Unsloth Documentation
- MiniMax M2.5 API Pricing - OpenRouter

