MiniMax M2.7 Review: The Model That Trains Itself
MiniMax M2.7 is the first open-weight frontier model to automate 30-50% of its own training pipeline - but a controversial license change and sluggish speed complicate the story.

MiniMax M2.7 does something no model at its price point has done before: it trains itself. Not as a marketing metaphor, but literally - an internal version of M2.7 managed over 100 autonomous optimization iterations on MiniMax's own reinforcement learning pipeline, analyzing failure trajectories, adjusting code, and running evaluations without a human in the loop. The result, per MiniMax's own measurements, was a 30% performance improvement on internal benchmarks.
TL;DR
- 8.0/10 - A credible self-evolving coding model that fixes M2.5's worst problem (hallucinations), then introduces a new one (license bait-and-switch)
- Hallucination rate collapsed from 88% to 34% - the most significant improvement over M2.5, and now lower than Claude Sonnet 4.6
- License shifted from MIT to a commercial-use-restricted "Modified-MIT" without warning, drawing "faux open-source" criticism from the developer community
- Developers building multi-agent coding pipelines who can live with the licensing terms; skip it if you need multimodal or truly fast inference
That claim deserves scrutiny, and we'll give it some. But first: M2.7 is a meaningful step forward from M2.5, fixing the biggest complaint against that model while staying in the same pricing bracket. It also arrives with a licensing controversy that matters for anyone assessing it for commercial use.
What Changed Since M2.5
MiniMax released M2.7 on March 18, 2026, and open-sourced the weights on April 12. The architecture is identical to M2.5: a Mixture-of-Experts model with 230 billion total parameters and just 10 billion active per inference step, a 200K token context window, and the same sparse routing that keeps inference costs low relative to dense models of comparable quality.
What changed is the training approach. Our earlier coverage of M2.5 noted an 88% hallucination rate on Artificial Analysis's AA-Omniscience evaluation - a serious liability for factual work, regardless of how strong the coding benchmarks were. M2.7 drops that rate to 34%. For context, Claude Sonnet 4.6 sits at 46% on the same evaluation. A model costing $0.30 per million input tokens now hallucinates less than one costing roughly 10 times more.
That single improvement changes the calculus for a lot of use cases.
The other major change is the self-evolution harness. MiniMax built a three-component framework - short-term memory, self-feedback, self-optimization - and launched M2.7 as an agent inside their own RL research pipeline. The model reads experiment logs, identifies failures, modifies the training scaffold, and runs smoke tests across extended autonomous loops. According to VentureBeat's reporting on the announcement, M2.7 now handles 30-50% of MiniMax's internal RL research workflow end-to-end.
"This process initiates a cycle of model self-evolution," MiniMax said in the release announcement, framing M2.7 not as a finished product but as a starting point for a feedback loop they intend to accelerate.
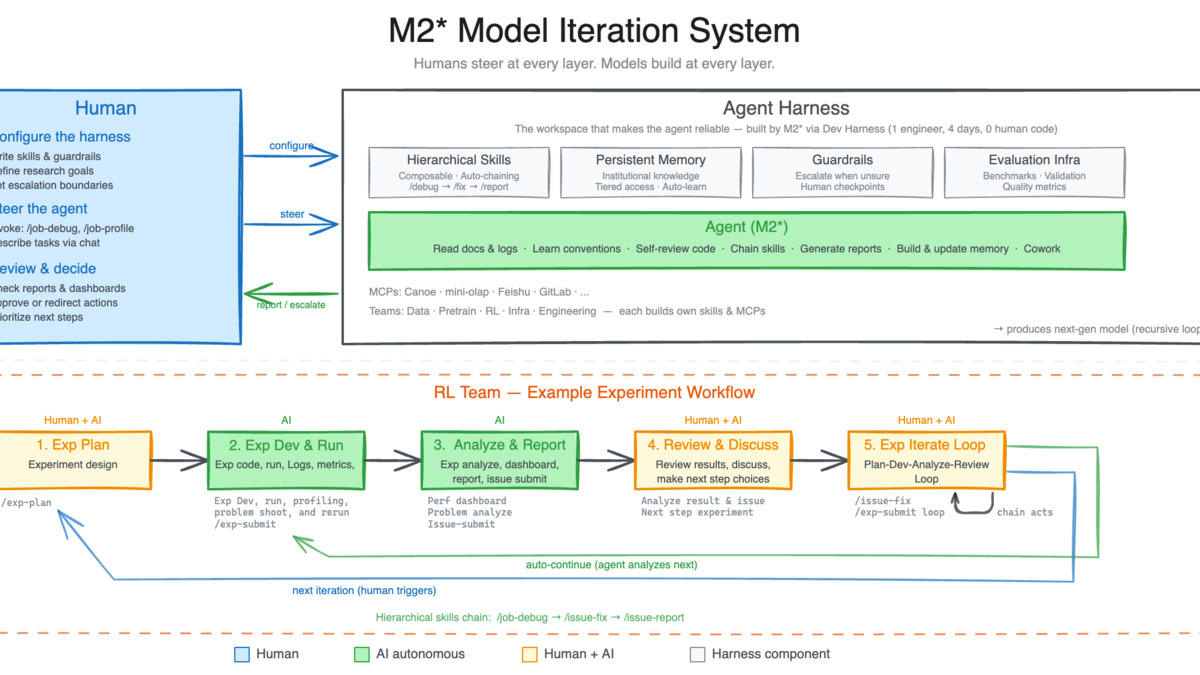 MiniMax's M2 Model Iteration System: human researchers handle top-level objectives; the agent harness manages experiment execution, log analysis, debugging, and metric reporting autonomously.*
Source: minimax.io
MiniMax's M2 Model Iteration System: human researchers handle top-level objectives; the agent harness manages experiment execution, log analysis, debugging, and metric reporting autonomously.*
Source: minimax.io
Coding Performance
The headline benchmark for M2.7 is SWE-Pro at 56.22%. SWE-Pro differs from the better-known SWE-Bench Verified in that it covers multiple programming languages and real-world tasks including log analysis, bug troubleshooting, security review, and ML workflow debugging - not just Python patch application.
On SWE-Bench Verified specifically, M2.7 scores 78%. That's actually below M2.5's 80.2%, which sounds like a regression but reflects the fact that M2.5 may have been more narrowly optimized for that benchmark format. The broader picture from independent evaluators suggests M2.7 is stronger at complex, multi-step production tasks even where the SWE-Bench number is slightly lower.
Other coding benchmarks worth noting:
| Benchmark | M2.7 Score | What It Measures |
|---|---|---|
| SWE-Pro | 56.22% | Multi-language real-world engineering |
| SWE-Bench Verified | 78% | Python repo bug fixing |
| Terminal Bench 2 | 57.0% | System-level engineering comprehension |
| VIBE-Pro | 55.6% | End-to-end project delivery |
| SWE Multilingual | 76.5% | Cross-language software engineering |
| Multi SWE Bench | 52.7% | Multi-repo coordination |
| MLE Bench Lite | 66.6% medal rate | ML competition workflow automation |
The MLE Bench Lite result is the one that validates the self-evolution story most directly. ML competition workflows are structurally similar to what M2.7 does in MiniMax's own RL pipeline - experiment design, code iteration, metric tracking. A 66.6% medal rate on 22 Kaggle-style competitions, second only to Claude Opus 4.6 and GPT-5.4, is a real signal that the model has internalized research patterns, not just code syntax.
On Artificial Analysis's Intelligence Index, M2.7 ranks #7 out of 85 models with a score of 50 - a 8-point improvement over M2.5 and well above the 30 average for open-weight models in its size class. The coding benchmarks leaderboard tracks how this compares to current proprietary frontier models.
Practical Testing: Where It Shines
In real-world testing published by WaveSpeed, M2.7 delivered roughly 90% of Claude Opus 4.6's code quality at 7% of the cost. That gap manifests mainly in test coverage - Opus tends to write more thorough test suites - and in handling of truly ambiguous requirements. M2.7 is more likely to pick an interpretation and run with it rather than asking for clarification.
For agentic pipelines with clear specifications, that directness is an asset. For collaborative development where the model needs to surface uncertainty, it isn't.
Tool adherence is another standout. MiniMax reports 97% skill adherence across 40+ complex skills each topping 2,000 tokens. That's the kind of reliability that matters in production agent systems where a single tool-call failure can cascade.
The Licensing Controversy
This is where M2.7 gets complicated.
M2 and M2.5 shipped under a MIT license - fully permissive, allowing commercial use without restriction. M2.7 ships under what MiniMax calls a "Modified-MIT" license that bans commercial deployment without written authorization from MiniMax. The company defended the change as protection against third-party providers degrading the model experience and damaging the brand.
The developer community wasn't sympathetic. A Hugging Face discussion thread titled "Open source my ass -- they are liars" built up hundreds of comments. The core objection is accurate: a license that restricts commercial use isn't MIT in any meaningful sense. Per the GNU Free Software Foundation's definitions, M2.7 fails the test for free software. It's source-available, not open-source.
MiniMax's position isn't unusual for Chinese AI labs navigating the tension between community goodwill and revenue protection. But the bait-and-switch timing - releasing M2.5 with genuine MIT, building a user base, then restricting M2.7 - is exactly the pattern that erodes trust fastest. Our earlier coverage of the distillation controversy around M2.5 noted that MiniMax's relationship with the open-source community has always been complicated. M2.7 doesn't simplify it.
For enterprise evaluation: if commercial use of M2.7 requires written authorization from a Shanghai-based company, build that dependency and approval timeline into your planning.
Speed and Limitations
M2.7 runs at 47.1 tokens per second with a 1.98-second time-to-first-token, per Artificial Analysis measurements. That places it at #34 out of 85 models overall - middle of the pack, not the bottleneck for most batch or agent workloads.
It's a bottleneck for latency-sensitive applications. IDE-inline autocomplete, real-time voice agents, and anything where a 2-second TTFT is perceptible to a user: these aren't M2.7's workloads. MiniMax offers a Highspeed API variant at $0.60/$2.40 per million tokens (double the base price) for teams where throughput matters more than cost.
The model is also text-only. No native image, audio, or video input. You can bolt on vision through MCP or tool calling, but it adds latency and complexity. Gemini 3.1 Pro has a native multimodal advantage here that M2.7 simply doesn't match.
Self-hosting requires serious hardware. The recommended minimum is 4 GPUs with 96GB VRAM each - four H100s or equivalent. The 8-GPU 144GB configuration supports context caches up to 3 million tokens. Unsloth maintains GGUF quantizations on Hugging Face; the 3-bit dynamic version fits in about 101GB of unified memory, which works on a high-end Mac with significant throughput reduction.
Strengths and Weaknesses
Strengths:
- Hallucination rate of 34% is truly lower than Claude Sonnet 4.6 at 46%, a credible correction from M2.5's 88%
- $0.30/$1.20 per million tokens makes frontier-class agentic coding economically viable at scale
- Self-evolution story is real, not marketing - MLE Bench Lite and internal RL automation results support it
- MoE architecture keeps inference costs proportional to 10B active parameters, not 230B total
- Supports SGLang, vLLM, Transformers, NVIDIA NIM for flexible deployment
Weaknesses:
- "Modified-MIT" license restricts commercial use - not genuinely open-source by any standard definition
- No native multimodal input in a market where Gemini and GPT-5.5 handle text, image, audio, and video natively
- 47 t/s and 1.98s TTFT rule out latency-sensitive applications
- Self-hosting hardware threshold (4x 96GB GPUs minimum) is realistic only for well-resourced teams
- SWE-Bench Verified score (78%) is actually a step back from M2.5's 80.2%, suggesting narrow benchmark overfitting was corrected at some cost
Verdict: 8.0/10
MiniMax M2.7 is a better model than M2.5 in the ways that matter most for production deployment. The hallucination regression that defined M2.5's biggest criticism is largely corrected. The self-evolution claims are supported by benchmark evidence, not just press releases. And the price-to-performance ratio stays exceptional.
The licensing change is the genuine problem. Not because "Modified-MIT" makes M2.7 unusable - for non-commercial use, research, and teams who secure written authorization, it works fine - but because it signals that MiniMax's open commitment is conditional. That conditionality is worth pricing into any long-term infrastructure decision.
If you're building coding agents and can tolerate the licensing terms, M2.7 earns serious consideration. If you need truly permissive weights, M2.5 is still available under genuine MIT, and the coding performance gap is narrower than MiniMax's marketing suggests.
Sources
- MiniMax M2.7: Early Echoes of Self-Evolution - MiniMax Official Announcement
- MiniMax M2.7 open-sourced with self-evolving capabilities - MarkTechPost
- MiniMax M2.7 performs 30-50% of RL research workflow - VentureBeat
- MiniMax-M2.7 Intelligence and Performance Analysis - Artificial Analysis
- MiniMax M2.7 self-evolving agent model benchmarks - WaveSpeed Blog
- MiniMax M2.7 license controversy - HuggingFace discussion
- MiniMax M2.7 Open Source License Change Sparks Controversy - BigGo Finance
- MiniMaxAI/MiniMax-M2.7 - Hugging Face Model Page
- MiniMax M2.7 Advances Agentic Workflows on NVIDIA Platforms - NVIDIA Technical Blog
- MiniMax M2.7 Is Now Open Source - Hacker News
