Mercury 2 Review: 1,000 Tokens per Second, Tested
Mercury 2 by Inception Labs is the fastest reasoning LLM available, built on diffusion architecture. We tested the speed, quality, and real-world trade-offs.

Something strange happens when you first use Mercury 2. You type a prompt, hit enter, and the response appears before you have fully processed that you asked a question. It isn't a streaming effect or a neat UI trick. The model genuinely generates over 1,000 tokens per second - roughly ten times faster than Claude 4.5 Haiku and nearly fourteen times faster than GPT-5 Mini. For anyone who has spent years waiting on inference pipelines, it feels slightly uncanny.
TL;DR
- 7.4/10 - A genuinely fast diffusion LLM that delivers Haiku-tier quality at a fraction of the cost, but with real architectural trade-offs
- Key strength: 711-1,196 tokens/second throughput with 1.7-second end-to-end latency - reproducible and independently verified
- Key weakness: Text-only, cloud-only, no fine-tuning, and an emerging architecture with fewer production battle scars than autoregressive models
- Use it if: You are building latency-sensitive agents, real-time voice AI, or high-volume RAG pipelines where Haiku-class quality is sufficient
- Skip it if: You need multimodal capabilities, on-premises deployment, or frontier-level reasoning for complex research tasks
That speed is not a marketing claim massaged from ideal conditions. Artificial Analysis, the independent model benchmarking firm, measured Mercury 2 at 711.6 tokens per second in their standardized multi-turn evaluation - ranking it first across 132 models they track. Inception Labs' own numbers, measured on NVIDIA Blackwell GPUs with NVFP4 precision, show 1,009 tokens per second with 1.7 seconds end-to-end latency. For comparison: Gemini 3 Flash takes 14.4 seconds end-to-end. Claude 4.5 Haiku with reasoning takes 23.4 seconds. The gap is not incremental.
The question worth asking is not whether the speed is real - it is - but whether a model that moves this fast can be trusted to think carefully.
How Mercury 2 Actually Works
Every language model you have used before Mercury 2 produces text the same way: one token at a time, left to right, each token conditioned on all previous tokens. This sequential dependency is architecturally fundamental to transformer-based autoregressive models. It is also a hard ceiling on throughput. No amount of engineering can make a model produce token N until token N-1 is complete.
Mercury 2 breaks that constraint by using a diffusion architecture for text - the same class of algorithm that powers image generators like Stable Diffusion. Rather than committing to tokens sequentially, the model starts with a noisy, incomplete draft of the entire response and runs a denoising process that refines multiple tokens simultaneously across a small number of passes. The result converges to a coherent output in far fewer sequential steps than an autoregressive chain.
Inception Labs was founded by researchers from Stanford, UCLA, and Cornell, including CEO Stefano Ermon, who co-invented the diffusion techniques used in Stable Diffusion and DALL-E. Ermon spent two years at Stanford applying diffusion to language sequences before spinning out to commercialize the research. Mercury 2 is the production version of that effort.
 Stefano Ermon is a professor of computer science at Stanford and the co-inventor of diffusion-based generative methods. He founded Inception Labs to apply those techniques to language model inference.
Stefano Ermon is a professor of computer science at Stanford and the co-inventor of diffusion-based generative methods. He founded Inception Labs to apply those techniques to language model inference.
The architecture has a less-discussed implication: diffusion models are less suited to producing very short outputs than long ones. A traditional autoregressive model answering "yes" or "no" does two decode steps. A diffusion model still runs its full refinement passes regardless of output length. This isn't a showstopper for most use cases, but it is worth knowing if you are routing short-answer queries through it.
Benchmarks: Where It Lands
Mercury 2 is positioned as a Haiku/Mini-tier model optimized for throughput, not as a frontier reasoner. The benchmark profile reflects that honestly.
On AIME 2025, the competitive mathematics benchmark, Mercury 2 scored 91.1 - competitive with the Haiku/Mini class and well above what you'd expect from a speed-optimized model. GPQA Diamond, which tests graduate-level science reasoning, came in at 73.6. Instruction following on IFBench scored 71.3. LiveCodeBench, a contamination-resistant coding evaluation, landed at 67.3. SciCode, which requires multi-step scientific problem solving, scored 38.4. TAU-bench, a more complex agentic evaluation, came in at 52.9.
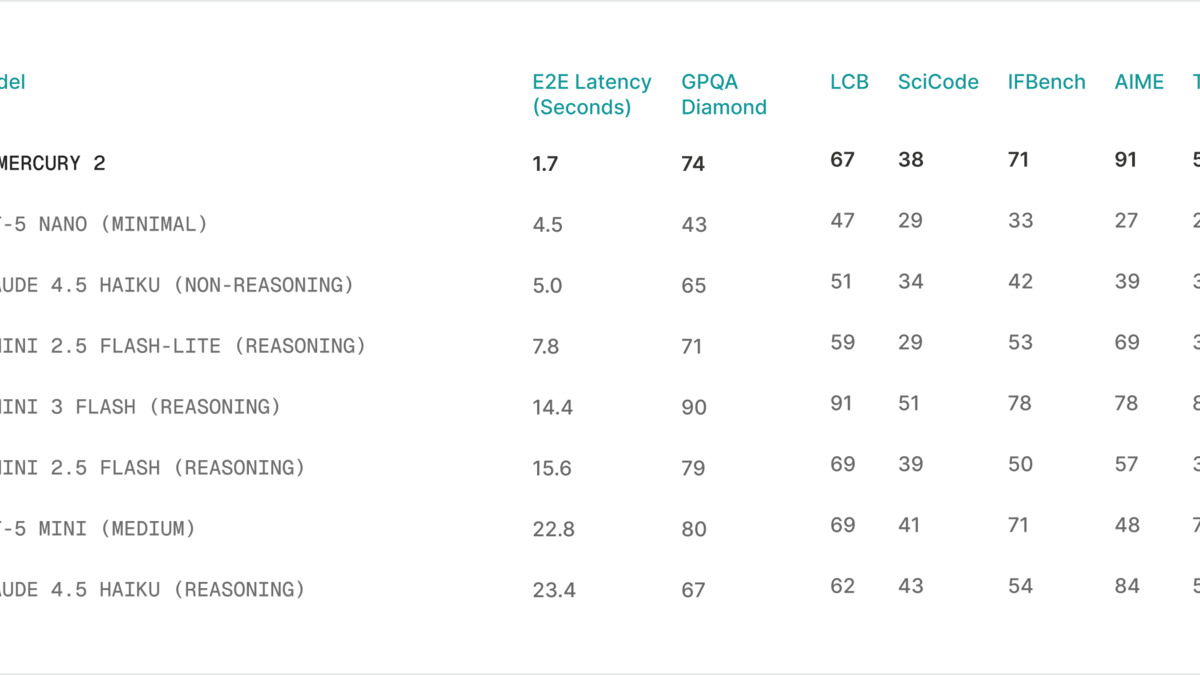 Inception Labs' published benchmark comparison for Mercury 2 against comparable models. The speed column is the story - quality is competitive with fast models at a fraction of their output cost.
Inception Labs' published benchmark comparison for Mercury 2 against comparable models. The speed column is the story - quality is competitive with fast models at a fraction of their output cost.
On the Artificial Analysis Intelligence Index, which aggregates quality signals across evaluations, Mercury 2 scored 33 out of 100 and ranked 22nd out of 132 models. The median score is 19, so it sits well above average for its price tier. It is not o3 or Gemini 3.1 Pro - those score in the 80s and 90s respectively on that index - but it isn't trying to be. The relevant comparison is against Claude 4.5 Haiku, GPT-5 Mini, and similar lightweight fast models, where it holds up well on quality while posting dramatically better throughput.
For context on where these scores sit relative to the broader landscape, the reasoning benchmarks leaderboard tracks AIME and GPQA scores across all major models. Mercury 2's AIME 91.1 puts it in the same band as the Haiku/Mini tier - capable of structured mathematical reasoning but not at the level of the best extended-thinking models.
One caution on the benchmark numbers: AIME problems are short-context, well-defined, and amenable to the kind of structured reasoning that diffusion models handle cleanly. There's no published data on multi-turn coherence over long exchanges, deep chain-of-thought over 10K+ tokens, or rare edge cases in complex agent loops. The 128K context window is present and documented; what actually happens to quality at 50K or 100K tokens isn't.
Pricing: The Real Story
The pricing is where Mercury 2 becomes genuinely interesting for production use cases. Input tokens cost $0.25 per million; output tokens cost $0.75 per million. The blended rate at a 3:1 input-to-output ratio works out to $0.38 per million tokens.
Compare that to the speed-class competition:
- Claude 4.5 Haiku: ~$4.90/M output tokens - 6.5x more expensive on output
- GPT-5 Mini: ~$1.90/M output tokens - ~2.5x more expensive on output
- Gemini 3 Flash: approximately 4x more expensive on output
For a pipeline producing tens of millions of tokens per day - an agent loop, a document processing system, a high-volume RAG retrieval stage - the cost differential compounds fast. At this price, Mercury 2 isn't just faster than its direct competitors; it's dramatically cheaper. The cost efficiency leaderboard captures this: when you weight both speed and price together, Mercury 2 sits near the top for throughput-intensive workloads.
There's an asterisk. Mercury 2 is verbosely produced - Artificial Analysis found that it produced 69 million output tokens during their Intelligence Index evaluation, against a median of 20 million. This suggests the model can be more verbose than necessary, which inflates effective cost on the output side. Prompt engineering to constrain output length will matter for cost-sensitive deployments.
Real-World Use: Where It Shines and Where It Does Not
The clearest use case for Mercury 2 is anything where you need many model calls with tight latency constraints and Haiku-class quality is sufficient.
Agent loops are the canonical example. Multi-step AI systems - an agentic framework coordinating tool calls, a coding agent iterating on a file, an automated research pipeline - compound latency across every model call. If each step takes 20 seconds instead of 2, a 10-step workflow takes over three minutes. At Mercury 2 speeds, that same workflow completes in under 20 seconds. This isn't a marginal improvement; it changes what kinds of interactive agent systems are feasible.
Real-time voice assistants are the second strong case. At 70-90 tokens per second, autoregressive models are borderline usable for live voice generation - there is perceptible lag that breaks conversational naturalness. Mercury 2's throughput removes that constraint completely.
Search and RAG pipelines benefit from the throughput for summarization and classification stages. Summarizing a 5,000-word document in under 3 seconds versus ChatGPT's roughly 35 seconds changes the economics of real-time search applications notably.
Where it doesn't work as well: complex, long-form reasoning tasks where the best models are truly better. If you're running analysis on a 100-page technical document, evaluating edge cases in legal contracts, or doing multi-step research synthesis, the quality gap between Mercury 2 and a frontier model like Gemini 3.1 Pro or Claude Opus 4.6 is real and matters. Speed isn't the bottleneck for those tasks - correctness is.
Limitations You Should Know
Text-only. Mercury 2 processes and generates text exclusively. No images, audio, or video. In a product landscape where multimodal capability is increasingly table stakes, this is a meaningful gap.
Cloud-only, no fine-tuning. Mercury 2 isn't available as open weights. You can't download and run it locally, deploy it on-premises, or fine-tune it on your own data. If data residency, model ownership, or custom training matter to your use case, this is not the answer.
Architecture novelty. Diffusion language models are an emerging class. The training recipes, failure modes, and debugging patterns are less understood than autoregressive models. There's a smaller community of engineers who have worked through production issues with dLLMs. When something breaks - and something always breaks in production - the support surface is shallower. This is a real cost that doesn't show up in benchmarks.
Blackwell optimization. The fastest numbers assume NVIDIA Blackwell GPUs with NVFP4 precision. Artificial Analysis's 711.6 tokens/second figure is real-world across standard cloud infrastructure, which is still extraordinary - but the headline 1,009+ t/s claims assume specific datacenter hardware. Developers on older CUDA setups will see less dramatic gains, though no published figures on older hardware are available.
Verbosity. The model tends to create more tokens than needed. This is manageable with system prompts, but it's a default behavior that affects cost calculations and adds noise to structured output workflows.
Strengths and Weaknesses
Strengths
- Independently verified throughput of 711-1,196 tokens/second - truly unprecedented for a reasoning model
- End-to-end latency of 1.7 seconds vs. 14-23 seconds for comparable models
- Pricing at $0.25/$0.75 per million tokens undercuts speed-class competitors by 2.5-6.5x
- OpenAI API-compatible - drop-in replacement for existing integrations
- Competitive reasoning benchmark scores (AIME 91.1, GPQA 73.6) for its price tier
- 128K context window with tool use and JSON output support
Weaknesses
- Text-only - no multimodal capability
- Cloud-only, no open weights or fine-tuning
- Diffusion architecture is architecturally less efficient for very short outputs
- Verbose by default - output length management requires deliberate prompting
- Smaller ecosystem of production experience compared to GPT/Claude/Gemini
- Optimum speed requires NVIDIA Blackwell hardware
Verdict
Mercury 2 is the most interesting model launch of early 2026 - not because it's the most capable, but because it represents a genuine architectural departure from everything the field has built for the past decade. The speed is real, independently verified, and transformative for latency-sensitive use cases. The pricing makes it the cheapest fast model available by a wide margin. The quality is where it says it is: Haiku-tier, honest about its positioning, good enough for the use cases it targets.
The trade-offs are also real. Text-only, cloud-only, no fine-tuning, and a novel architecture that fewer engineers know how to debug in production - these are not footnotes. For teams that need multimodal capability, on-premises deployment, or frontier-level reasoning, Mercury 2 is the wrong tool.
For teams building agent frameworks, voice interfaces, or high-volume document processing pipelines - and who can accept Haiku-class quality - it's the best option on the market at its price point. The architecture bet Stefano Ermon has been running since his Stanford diffusion research is, at minimum, not wrong. Whether dLLMs can eventually match frontier autoregressive quality at this speed remains the open question. Mercury 2 doesn't answer it yet, but it makes the question worth taking seriously.
Score: 7.4/10
Sources
- Inception Labs - Introducing Mercury 2
- Gigazine - Inception Announces Mercury 2
- Artificial Analysis - Mercury 2 Performance Analysis
- The Decoder - Mercury 2: First Diffusion-Based Language Reasoning Model
- Analytics Vidhya - Mercury 2: The AI Model That Feels Instant
- InfoWorld - Mercury 2 Speeds Around LLM Latency Bottleneck
- Hacker News - Mercury 2 Discussion
- Inception Labs - Platform
- Inception Labs - The Next Step for dLLMs
- The AI Journal - Inception Launches Mercury 2
