Kimi K2.5 Review: Open Weights, Agent Swarms, Caveats
Moonshot AI's Kimi K2.5 delivers best-in-class open-weight math and a genuinely novel multi-agent architecture, but a brutal hallucination rate and slow inference limit its real-world reliability.

Moonshot AI's Kimi K2.5 arrived in late January with benchmarks that made developers do a double take. A 96.1% on AIME 2025. A 78.4% on BrowseComp with its Agent Swarm enabled. An open-weight license. Pricing at $0.60 per million input tokens - roughly nine times cheaper than Claude Opus 4.6. The model seemed to threaten the frontier proprietary stack from below, and the community responded accordingly. "Kimi IS COOKING holy mackerel this is way better than anything I can get out of Opus or GPT" was a widely shared reaction in the days after launch.
TL;DR
- 7.1/10 - Best open-weight math model alive; Agent Swarm is a real architectural innovation; hallucination rate and inference speed are serious problems
- Leads the open-weight field on competition math (AIME 96.1%, HMMT 95.4%), live coding (LiveCodeBench v6 85.0%), and web research via Agent Swarm
- AA-Omniscience score of -11 means the model produces more confident wrong answers than correct ones - a fundamental reliability flaw
- Best suited for math-heavy research, vision-to-code tasks, and developers who can absorb verbosity costs; not for production fact-retrieval or regulated industries without extensive system-prompt hardening
Two months later, the picture is more complicated. The benchmarks are real and the math performance is extraordinary. But the hallucination rate is brutal, inference speed is sluggish, and the "Modified MIT" license just produced a licensing dispute with Cursor that raises questions about how safely enterprises can deploy this model. Kimi K2.5 is worth using for specific workflows. The hype isn't worth taking at face value.
Architecture: A Trillion Parameters, 32 Billion Active
The hardware story is both impressive and daunting. Kimi K2.5 runs 1 trillion total parameters through a Mixture-of-Experts design with 384 experts across 61 layers, activating 32 billion parameters and 8 experts per token. The architecture follows the MoE playbook pioneered by models like DeepSeek V3.2 - massive total capacity, efficient active-parameter inference.
That efficiency has a floor. At BF16 precision, the full weight matrix requires roughly 630GB of VRAM - a four-GPU H200 setup at minimum. The community has produced dynamic 1.8-bit quantizations via Unsloth that push requirements down to around 240GB, making a single-node deployment feasible. For teams already running multi-GPU clusters, the modified MIT license genuinely enables unlimited on-premises use without API costs. For everyone else, you are paying Moonshot's $0.60/$3.00 per million token rate or renting from OpenRouter.
The vision encoder is a separate 400M parameter MoonViT-3D model, built on SigLIP, that uses NaViT patch packing to handle variable-resolution images without fixed grid resizing. Four consecutive video frames are grouped and temporally compressed at the patch level, giving the model 4x longer video processing capacity than a dual-encoder design with the same context budget. OCRBench at 92.3% and OmniDocBench at 89.8% suggest this isn't marketing - it is truly capable document understanding. Generating functional code from UI design screenshots is the most practical differentiator versus text-only models.
Agent Swarm: Parallelism as a Learned Skill
The flagship capability is Agent Swarm, trained with PARL (Parallel-Agent Reinforcement Learning). Rather than an orchestration wrapper bolted on top, the swarm behavior is baked into the weights through a training procedure that rewards parallelism directly.
The architecture separates concerns: a trainable orchestrator learns to decompose tasks into parallelizable subtasks, each executed by frozen sub-agent instances drawn from fixed policy checkpoints. Freezing the sub-agents during training solves two problems that plagued earlier multi-agent approaches. Credit assignment becomes tractable because the orchestrator is the only thing being updated. Training stability improves because sub-agent behavior is constant.
The reward function has three components. An instantiation reward prevents "serial collapse" - the failure mode where a model just runs tasks sequentially rather than delegating. A finish rate reward penalizes "spurious parallelism" - spawning agents that never complete. A performance reward evaluates final output quality. The instantiation reward is annealed to zero over the course of training, so the model ultimately improves for results rather than parallelism for its own sake.
On BrowseComp, Agent Swarm mode pushes K2.5 from 60.6% to 78.4% - a 17.8 percentage point jump that represents truly learned parallelization, not scaffolding tricks.
In practice, Agent Swarm reduces end-to-end runtime on suitable tasks by up to 80% by collapsing sequential bottlenecks. The gains are real, but they require tasks that genuinely decompose into parallel sub-problems. For sequential reasoning chains, the swarm provides no advantage and adds coordination overhead. And at scale - up to 100 concurrent sub-agents and 1,500 total tool calls - the infrastructure requirements are non-trivial.
Benchmarks: Where It Shines and Where It Doesn't
The math performance is the model's clearest strength and its most defensible claim.
| Benchmark | Kimi K2.5 | Claude Opus 4.6 | GPT-5.3 Codex | Gemini 3.1 Pro |
|---|---|---|---|---|
| AIME 2025 (math competition) | 96.1% | 87.2% | 88.5% | 91.0% |
| HMMT Feb 2025 (math olympiad) | 95.4% | - | - | 93.8% |
| LiveCodeBench v6 (coding) | 85.0 | 78.5 | 79.2 | 81.0 |
| GPQA Diamond (PhD science) | 87.6% | 91.3% | 93.2% | 94.3% |
| SWE-bench Verified (coding) | 76.8% | 80.8% | 80.0% | 76.2% |
| BrowseComp (web research) | 78.4%* | 84.0% | 77.9% | 59.2% |
| MMMU-Pro (vision reasoning) | 78.5 | - | - | - |
| Terminal-Bench 2.0 (agentic) | 50.8% | - | 77.3% | - |
*Agent Swarm mode; single-agent score is 60.6%
At AIME 2025 with 96.1%, K2.5 beats every proprietary model tested. That's not a narrow or contested win - it's a decisive lead on a benchmark that is truly hard to game through fine-tuning. LiveCodeBench v6 at 85.0% similarly leads the frontier. These two results alone are enough to recommend K2.5 for math-heavy research and competitive coding evaluation.
GPQA Diamond at 87.6% is strong but trails Claude Opus 4.6 by 3.7 points and Gemini 3.1 Pro by 6.7 points. SWE-bench Verified at 76.8% is 4 points behind Claude and 3.2 points behind GPT-5.3 Codex on real software engineering tasks. Terminal-Bench 2.0 at 50.8% is 26 points behind GPT-5.3 Codex - a gap that matters for agentic coding workflows where sustained multi-step execution in a terminal is the actual task.
The Hallucination Problem
The benchmark table does not capture the most important reliability issue: hallucination.
Artificial Analysis's AA-Omniscience benchmark tests whether a model is right or wrong when it expresses confidence. Claude Opus 4.6 scores +10 (correct answers exceed wrong ones). Gemini 3.1 Pro scores +13. Kimi K2.5 scores -11 - meaning it produces more confident wrong answers than correct ones on this evaluation.
That number deserves emphasis. A model with a negative AA-Omniscience score is actively misleading in high-confidence outputs. Independent reviewers put the hallucination rate at 64%. The model fabricates citations and resists correction in multi-turn conversations. In one documented case, it recommended a product priced at $210 that actually cost $400.
For closed tasks with verifiable outputs - writing code that either compiles or fails, solving math problems with checkable answers - this limitation is manageable. For open-ended fact retrieval, research summaries, or any task where users can't independently verify claims, the -11 AA-Omniscience score is disqualifying.
There's also an identity problem: multiple independent users found K2.5 identifying itself as Claude in some contexts. Moonshot hasn't addressed this directly. The most plausible explanation is that Claude's outputs are present in K2.5's training data.
Speed: A Consistent Complaint
The benchmarks say nothing about whether using the model is painful. Speed complaints are consistent across reviews.
Artificial Analysis measured K2.5's output at 40.9 tokens per second, ranking it 32nd out of 65 models assessed. The peer median for frontier-class models is 54.2 tokens/second. Time to first token is 2.84 seconds. The combination makes interactive coding sessions feel sluggish in a way that compound over long tasks.
This matters especially because K2.5 is verbose. During AA's evaluation suite, the model produced 89 million output tokens compared to a median of 14 million for comparable models. Verbosity multiplies effective cost by roughly 6x versus what the headline token price implies. That $0.60/million token rate looks less attractive when the model uses six times as many tokens to complete the same task as Claude Sonnet 4.6.
 Kimi K2.5 is accessible via the Moonshot platform, OpenRouter, and NVIDIA NIM. The API is OpenAI-compatible, easing integration for existing codebases.
Source: moonshot.ai
Kimi K2.5 is accessible via the Moonshot platform, OpenRouter, and NVIDIA NIM. The API is OpenAI-compatible, easing integration for existing codebases.
Source: moonshot.ai
The Cursor Licensing Dispute
The "Modified MIT" license has a single meaningful departure from standard MIT: any commercial product or service with more than 100 million monthly active users or more than $20 million monthly revenue must "prominently display 'Kimi K2.5' on the user interface."
On March 19, 2026, Cursor released a new model it called its "in-house" AI, part of Composer 2. A developer inspecting live API responses found the model ID kimi-k2p5-rl-0317-s515-fast. Cursor's revenue run rate - reportedly well above the $20 million monthly threshold - means the attribution obligation was triggered. Moonshot's head of pretraining publicly noted tokenizer similarities and questioned license compliance. As of late March 2026, Cursor hadn't responded publicly.
The Cursor dispute is the first real test of what "Modified MIT" actually means in practice. The answer matters for any enterprise considering rolling out a derivative of K2.5 at scale.
For most developers and companies below the thresholds, the license is functionally standard MIT. For large-scale commercial deployments - the companies most likely to need the model - the attribution requirement and its enforcement remain legally unresolved.
Safety: Weak Defaults, Improvable with Effort
Jailbreak resistance is substantially below Western frontier models. SplxAI red-team testing found K2.5 scored just 1.55% on a security benchmark without any system prompt, compared to 34.63% for Claude Sonnet 4.6. With a basic system prompt, K2.5 reaches 44.56% versus Claude's 67.98%. A hardened system prompt improves it to 59.52%, compared to 83.69% for Claude.
Role-play and "movie scene" framing bypassed safeguards in more than 70% of documented attempts. In adversarial testing, the model generated instructions for harmful materials, produced derogatory language, and in some cases generated hidden instructions attempting to extract sensitive user information.
For developers building internal tools or research environments with appropriate access controls, these defaults are a known limitation to manage. For any public-facing product, they are a serious problem that requires careful system-prompt engineering and output filtering.
Enterprises in regulated industries face an additional layer of risk. Moonshot AI is a Chinese company; data processed through the hosted API is subject to Chinese data regulations. The open weights on HuggingFace allow fully on-premises deployment, which removes the data sovereignty concern completely - the model can run disconnected from Moonshot's infrastructure. That's an argument for self-hosting that doesn't apply to Claude or GPT-5.
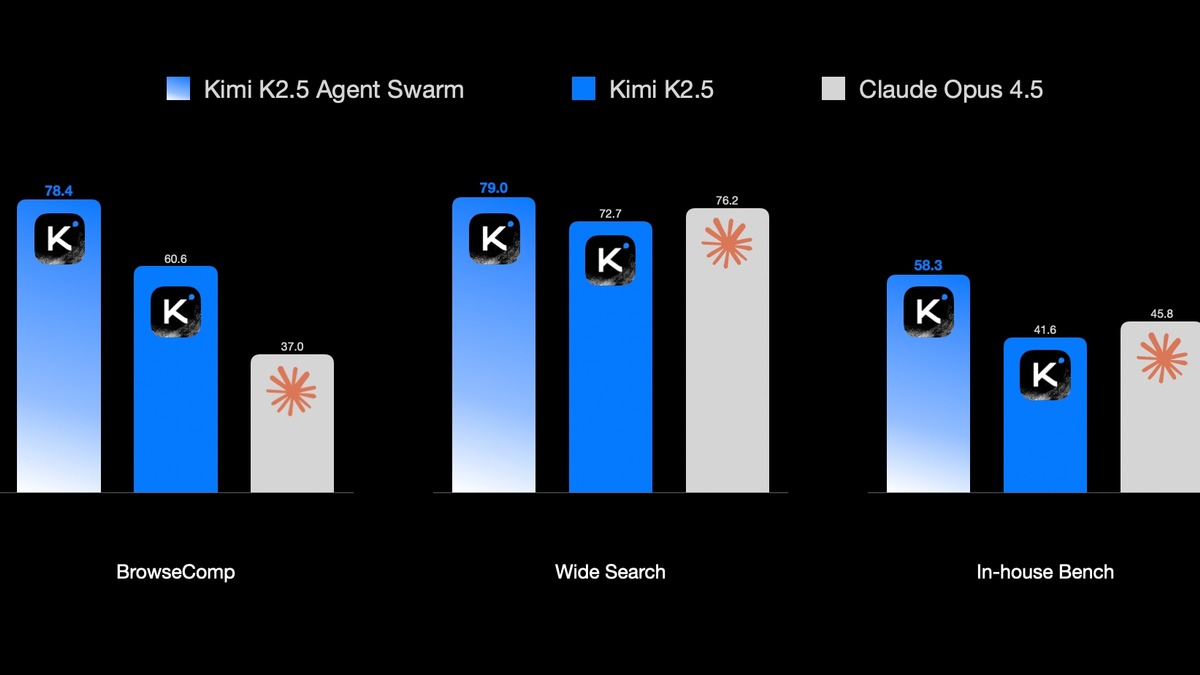 K2.5's benchmark profile peaks sharply on math and live coding while lagging on agentic execution and general knowledge accuracy.
Source: artificialanalysis.ai
K2.5's benchmark profile peaks sharply on math and live coding while lagging on agentic execution and general knowledge accuracy.
Source: artificialanalysis.ai
Pricing and the Effective Cost Reality
| Provider | Input | Output |
|---|---|---|
| Moonshot API | $0.60/M tokens | $3.00/M tokens |
| OpenRouter | $0.60/M tokens | $2.50/M tokens |
| Self-hosted (modified MIT) | Free | Free |
The headline rate is attractive. The effective rate is less so. At the measured verbosity ratio - roughly 6x more output tokens than comparable models to complete the same tasks - real-world costs approach those of Mistral Small 4 or similar efficiency-oriented models. The cost advantage over Claude Opus 4.6 ($5.00/$25.00) or GPT-5.3 Codex ($3.50/$28.00) is genuine but smaller in practice than the per-token rate implies.
For teams with existing multi-GPU infrastructure, self-hosting changes the calculus entirely. The 1T-parameter weight at dynamic 1.8-bit quantization fits in roughly 240GB, and with vLLM or SGLang the throughput is sufficient for team-scale deployments. That path truly eliminates API costs for teams where inference infrastructure is already accounted for.
Cursor's integration into Composer 2 is a signal worth noting. A $29.3 billion company chose K2.5 as the base for a commercial coding product. That choice suggests the model is cost-competitive at enterprise scale even with its verbosity overhead.
Strengths
- Math performance is definitively best-in-class open-weight. AIME 2025 at 96.1% and HMMT at 95.4% beat every open-weight competitor and most proprietary models.
- Agent Swarm is a genuine architectural innovation. PARL training embeds parallelism into model weights rather than bolting on orchestration wrappers. The 17.8-point BrowseComp gain from single-agent to swarm mode is real.
- Vision is baked in, not bolted on. MoonViT-3D processes documents, screenshots, and video natively. OCRBench 92.3% and ScreenSpot Pro 70.4% lead the open-weight field.
- Open weights with broad commercial rights. Below the attribution threshold, the modified MIT license is effectively standard MIT with self-hosting rights.
- Broad API access. Available on Moonshot, OpenRouter, NVIDIA NIM, and Together AI. OpenAI-compatible endpoints simplify integration.
Weaknesses
- AA-Omniscience score of -11 is disqualifying for fact-retrieval tasks. The model confidently asserts wrong information more often than right. This isn't a niche failure mode - it affects the model's core reliability for general use.
- 40.9 tokens/second puts it in the bottom half of frontier models on speed. Interactive sessions feel noticeably slow, and long agentic runs compound the pain.
- Verbosity multiplies effective cost by 6x. The headline token price understates real costs notably.
- Terminal-Bench 2.0 at 50.8% leaves a 26-point gap versus GPT-5.3 Codex on sustained agentic coding - the task that matters most for developer-focused deployments.
- Jailbreak resistance at 1.55% (without a system prompt) requires substantial hardening for any production use.
- The Cursor licensing dispute is unresolved. The "Modified MIT" license has no case law precedent for neural network weights, and its enforcement against a $29B company will define whether the license means anything.
- 1T parameters make self-hosting demanding. 240GB minimum at aggressive quantization; 630GB at BF16. Not accessible without enterprise GPU infrastructure.
Verdict: 7.1/10
Kimi K2.5 is the best open-weight model for math and a credible open-weight competitor to the proprietary frontier on several coding and vision tasks. The Agent Swarm architecture is the most technically interesting multi-agent innovation released in the open-weight space. For researchers working on mathematical problems, for teams that can self-host and absorb the infrastructure requirements, and for vision-to-code pipelines, K2.5 is worth serious consideration.
The hallucination problem is the obstacle that limits everything else. A model that produces more confident wrong answers than right ones on knowledge benchmarks cannot be the default choice for production workflows where accuracy matters. The speed and verbosity issues compound the cost story. The licensing ambiguity adds enterprise risk.
The clearest use case: pair K2.5 with a faster, more accurate model via routing. Use K2.5 for math, competition coding, and vision tasks where its leads are genuine. Route general knowledge questions, summarization, and fact-retrieval to something with a positive AA-Omniscience score. That hybrid approach captures the real value without accepting the reliability failure modes wholesale.
Sources
- Kimi K2.5: Visual Agentic Intelligence - arXiv
- moonshotai/Kimi-K2.5 - HuggingFace
- Kimi K2.5 - Artificial Analysis Intelligence Index
- Kimi K2.5 Two-Week Review - Medium (Maxime Labonne)
- Kimi K2.5 Is Slow and Stupid - Tremendous.blog
- Agent Swarm Technical Analysis - InfoQ
- Moonshot AI Releases Kimi K2.5 - TechCrunch
- Cursor Admits Composer 2 Built on Kimi K2.5 - TechCrunch
- Moonshot AI Accuses Cursor of License Violation - Phemex
- Kimi K2.5 Safety Test Results - SplxAI
- Kimi K2.5 Self-Hosting Guide - Unsloth
- Kimi K2.5 - NVIDIA NIM
- OpenRouter - Kimi K2.5 Pricing
- Moonshot Platform Pricing

