GLM-5.2 Review: Best Open-Weight Coder at 1/6 Cost
Z.ai's GLM-5.2 delivers frontier coding performance with open weights and MIT license at roughly one-sixth the cost of GPT-5.5 - but can it replace Claude Opus 4.8?

Two weeks after its June 13 release, GLM-5.2 has done something no open-weight model has managed since the GPT-4 era: it made the cost argument irrelevant. At roughly one-sixth the price of GPT-5.5 and with a full MIT license on the weights, Z.ai's latest flagship has moved from "impressive for open source" to "competitive with the best in the world" on the benchmarks developers actually use.
TL;DR
- 8.7/10 - the best open-weight coding model available, trailing only Claude Opus 4.8 on long-horizon tasks
- 744B total parameters (MoE, ~40B active per token), 1M token context, MIT license - the most capable open model you can legally download and run anywhere
- Trails Claude Opus 4.8 by ~6 points on SWE-bench Pro and one month of capability on abstract reasoning; verbose output adds cost at scale
- Developers who need frontier coding without cloud lock-in or US model restrictions; enterprises in regulated sectors should assess data residency before using Z.ai's API
The release landed at a pointed moment. It came one day after the US Commerce Department suspended global access to Claude Fable 5, and Z.ai founder Jie Tang opened his launch post with: "the sudden restriction of certain frontier models is deeply regrettable." The geopolitical subtext is hard to miss, but the model stands on its own technical merits regardless of how you feel about the timing.
What Is GLM-5.2
GLM-5.2 is the third major iteration in Z.ai's GLM-5 series, built on the same Mixture-of-Experts foundation as its predecessors. The headline specification is 744 billion total parameters with roughly 40 billion active per token - a MoE ratio that keeps inference costs low for a model of this capability tier. It was trained completely on 100,000 Huawei Ascend 910B chips using the MindSpore framework, with no NVIDIA hardware anywhere in the pipeline.
The model ships under a MIT license with no commercial or regional restrictions. Weights are available on the zai-org Hugging Face account. From a licensing standpoint, this is the most permissive release at this capability level to date.
The two meaningful upgrades from GLM-5.1 are context and architecture. Context jumps from 200K to 1,048,576 tokens, with a maximum output of 32,768 tokens per response. The architectural change is IndexShare, a new sparse attention mechanism that matters more than the parameter count suggests.
IndexShare: The Real Technical Story
IndexShare addresses a specific bottleneck in long-context inference. Standard sparse attention runs a full top-k indexer computation on every transformer layer - at 1M token context, that becomes prohibitively expensive. GLM-5.2's fix is to run the indexer only once every four layers and reuse the selected token indices across the remaining three.
The results are material: 2.9x fewer per-token FLOPs at 1M context length, and a 1.82x speedup on prefill (the step that processes the full context before generation starts). Z.ai also improved the Multi-Token Prediction layer through KVShare, rejection sampling, and end-to-end TV loss, increasing speculative acceptance length by 20%.
For practical agentic work - long repository ingests, marathon coding sessions, multi-file refactors - this matters. The previous 200K limit forced agents to compact frequently. At 1M tokens, a GLM-5.2-backed session can hold substantially more context before hitting the wall.
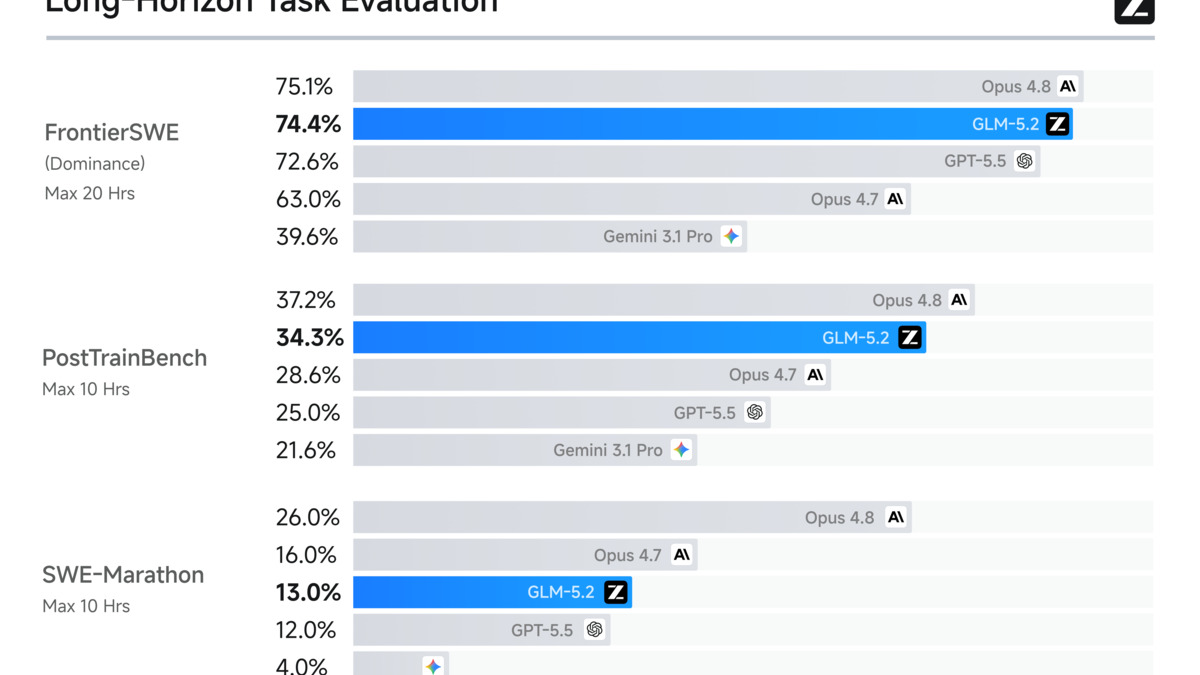 GLM-5.2 benchmark results showing performance on long-horizon coding tasks versus frontier models.
Source: huggingface.co
GLM-5.2 benchmark results showing performance on long-horizon coding tasks versus frontier models.
Source: huggingface.co
Benchmark Performance
The numbers are the strongest argument for GLM-5.2. On standard coding benchmarks, it is the best open-weight model available.
| Benchmark | GLM-5.2 | GLM-5.1 | Claude Opus 4.8 | GPT-5.5 |
|---|---|---|---|---|
| SWE-bench Pro | 62.1% | 58.4% | 69.2% | 58.6% |
| FrontierSWE | 74.4% | - | 75.1% | 72.6% |
| Terminal-Bench 2.1 | 81.0 | 63.5 | 85.0 | - |
| Design Arena | #1 (Elo) | - | - | - |
| GPQA Diamond | 92.4 | - | - | 93.6 |
On SWE-bench Pro - the most widely cited benchmark for real-world software engineering tasks - GLM-5.2 scores 62.1%, comfortably ahead of GPT-5.5 (58.6%) and the previous GLM-5.1 (58.4%), while trailing Claude Opus 4.8 (69.2%) by roughly seven points. The gap to Opus is real and worth naming: if you're doing the hardest long-horizon work and price is no object, Opus is still ahead.
Where GLM-5.2 closes the gap most convincingly is FrontierSWE - a benchmark designed for realistic long-horizon tasks with tight feedback loops. At 74.4%, it sits within one percentage point of Opus 4.8 (75.1%) and three points ahead of GPT-5.5 (72.6%). That's a meaningful data point: on the tasks most representative of actual agentic coding, the performance gap almost disappears.
The Design Arena result - where GLM-5.2 placed first overall, beating Claude Fable 5 by 10 Elo points - was unexpected. Design Arena uses human preference comparisons rather than automated scoring, and UI code generation isn't the use case Z.ai leads with. It suggests the model has generalised well beyond its primary training objective.
GLM-5.2 hits 74.4% on FrontierSWE - within one percentage point of Claude Opus 4.8, at roughly one-sixth the API cost.
Zvi Mowshowitz flagged GLM-5.2 as "the new best open model" shortly after release. Artificial Analysis confirmed it is the highest-ranked open-weight model on their Intelligence Index. The consensus is clear: in the open-weight category, this is the current ceiling.
Coding in Practice
Developer testing has generally confirmed the benchmark path. On agentic tool use, GLM-5.2 handles function calling cleanly - it chooses the right tool for the task, passes valid arguments, continues sensibly after tool results feed back, and shows restraint on simple questions that do not need external calls.
The 1M context window makes a practical difference for repository-scale work. Developers running GLM-5.2 through OpenCode report that the model holds more context across sessions than its predecessors, reducing the mid-task compaction that disrupts longer agentic runs. Z.ai's own documentation describes a 35-hour autonomous coding run that fired 1,158 tool calls - a number that would have been impossible with the previous 200K limit.
The model supports two thinking-effort levels, High and Max. Z.ai recommends Max for multi-step coding tasks; High runs faster and is presumably cheaper per token, though the exact cost differential between modes hasn't been published.
Day-one API support covered eight coding environments: Claude Code, Cline, OpenCode, Roo Code, Goose, Crush, OpenClaw, and Kilo Code through an OpenAI-compatible endpoint. The model ID is glm-5.2[1m]. For Claude Code users, the config maps both the Opus and Sonnet slots to the same GLM-5.2 endpoint.
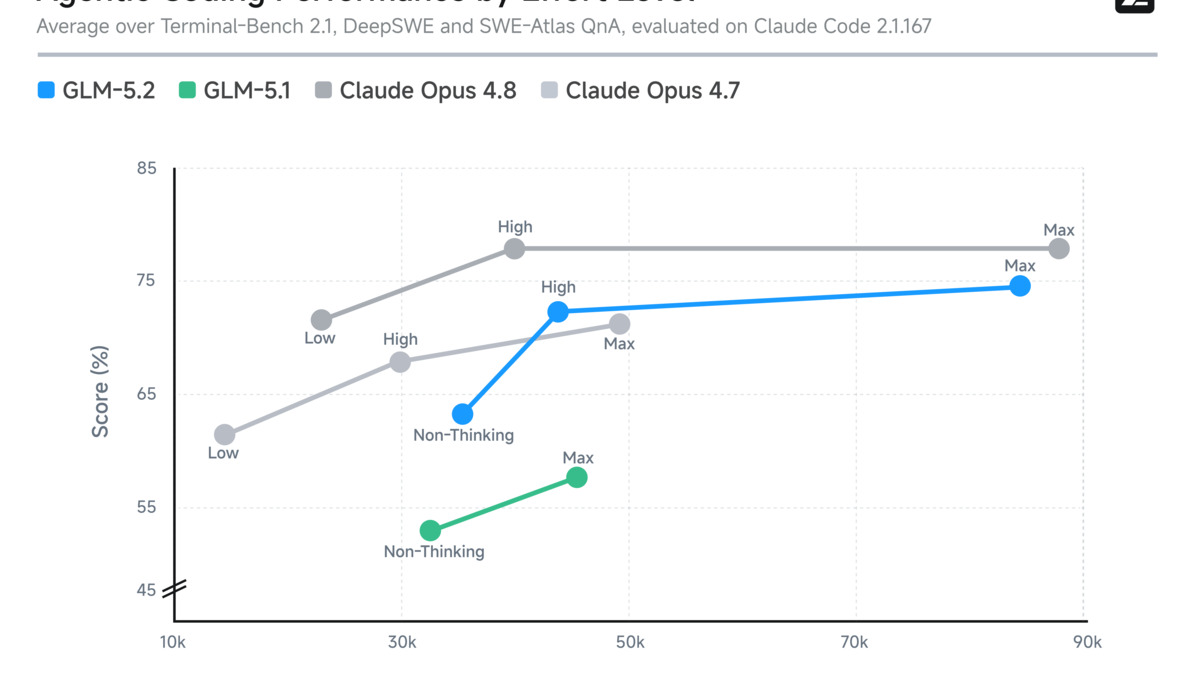 GLM-5.2 context window performance showing the 1M-token capability and IndexShare efficiency gains over the prior generation.
Source: huggingface.co
GLM-5.2 context window performance showing the 1M-token capability and IndexShare efficiency gains over the prior generation.
Source: huggingface.co
Security Benchmark Surprise
A standout data point came from Semgrep, which ran GLM-5.2 on their IDOR (Insecure Direct Object Reference) vulnerability detection benchmark - the same dataset they had used to assess frontier coding agents.
GLM-5.2 scored 39% F1 with no scaffolding, beating Claude Code's 32% on the same task. At GLM-5.2's pricing, the open-weight run cost roughly $0.17 per vulnerability found. For security teams running continuous scanning across large codebases, per-bug economics matter more than headline capability scores.
Semgrep's authors were explicit about the limits: this is one dataset, one task, one run, and their own multimodal pipeline (which scored 53-61% F1) outperformed both models significantly. The point isn't that GLM-5.2 is a security tool - it is that on a reasoning-heavy task outside its primary training objective, it beat a specialist frontier coding agent.
See the GLM-5.2 coverage at the open-source LLM leaderboard for a broader comparison across benchmarks.
Pricing and Deployment
API pricing through the Z.ai Coding Plan is subscription-based:
| Tier | Monthly Price | Weekly Quota |
|---|---|---|
| Lite | ~$10/month | ~400 prompts |
| Pro | ~$30/month | ~2,000 prompts |
| Max | ~$80/month | ~8,000 prompts |
Standalone token-based API pricing (now live) runs at about $0.95-$1.40 per million input tokens and $3.00-$4.40 per million output tokens, depending on provider. For cached input, Z.ai offers $0.26 per million tokens. During the launch promotion period, quota consumption is billed at 3x during peak hours and 2x off-peak.
For comparison, GPT-5.5 input pricing is approximately $8/M tokens - roughly six to eight times higher depending on configuration. Claude Opus 4.8 at API tier is similarly priced. The cost gap is real and large.
For self-hosting, GLM-5.2 requires 8x H200 SXM GPUs at FP8 precision with expert parallelism enabled in vLLM or SGLang. A 2-bit quantised GGUF variant (239GB) can run on a 256GB unified memory Mac or a 4x RTX 3090 setup, with significant capability trade-offs. The model is available on 20+ third-party providers including Together AI and GMI Cloud for those who don't want to manage the infrastructure.
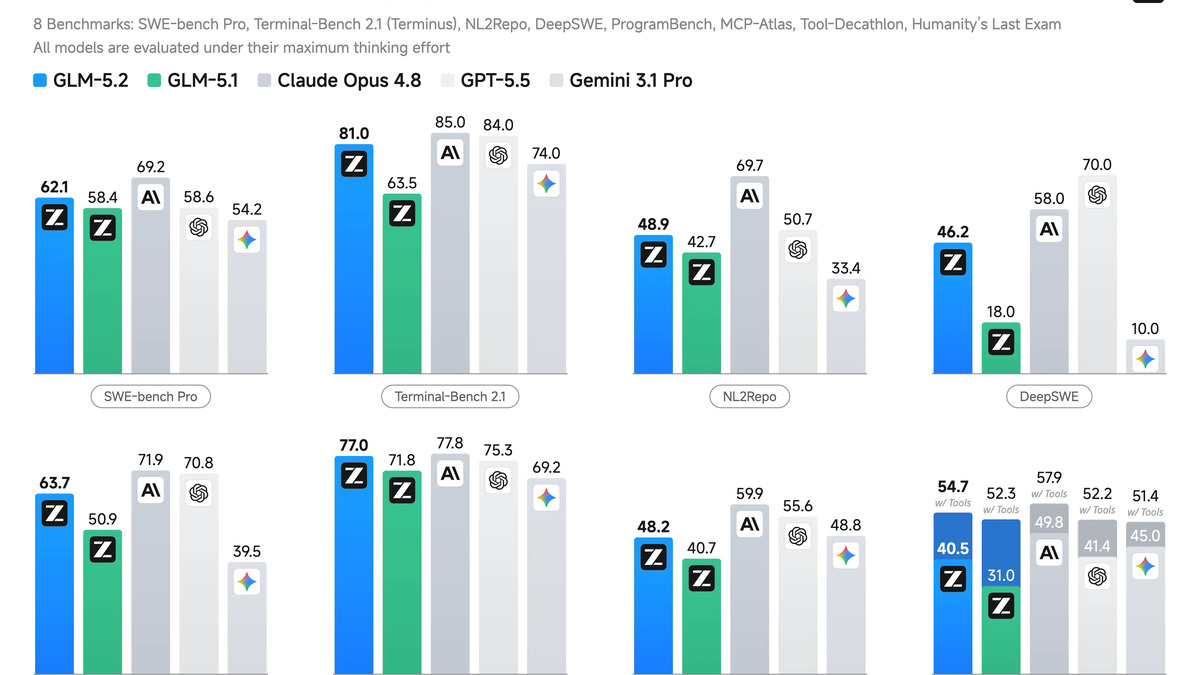 The IndexShare mechanism reduces indexer computation by 75% across four-layer blocks, enabling 2.9x fewer FLOPs at 1M context.
Source: huggingface.co
The IndexShare mechanism reduces indexer computation by 75% across four-layer blocks, enabling 2.9x fewer FLOPs at 1M context.
Source: huggingface.co
Strengths and Weaknesses
Strengths:
- Best open-weight coding model on SWE-bench Pro (62.1%), FrontierSWE (74.4%), and Terminal-Bench 2.1 (81.0%)
- MIT license with no commercial or regional restrictions - genuinely permissive for enterprise deployment
- 1M token context window enables sustained agentic coding runs without compaction
- IndexShare delivers 2.9x fewer FLOPs at full context - not just a marketing claim
- Costs one-sixth to one-eighth of comparable US frontier API tiers
- Trained without NVIDIA hardware - immune to GPU export control scenarios
- Beats Claude Code on Semgrep's IDOR security benchmark at $0.17 per finding
- Inference speed of ~300 tokens/second is fast for the 744B parameter class
Weaknesses:
- Trails Claude Opus 4.8 by ~7 points on SWE-bench Pro and ~4 points on Terminal-Bench 2.1
- Token verbose: uses roughly 43K output tokens per Artificial Analysis Intelligence Index task, higher than MiniMax-M3 and Kimi K2.6 at similar capability levels
- Abstract reasoning lags frontier proprietary models by around one generation cycle
- Enterprises using Z.ai's hosted API must assess data residency - traffic routes through Chinese infrastructure
- Self-hosting the full FP8 model requires 8x H200 GPUs ($1M+ hardware investment)
- Peak-hour quota pricing (3x multiplier) makes cost estimation unpredictable on subscription tiers
Verdict
GLM-5.2 is the model to reach for if you need frontier-tier coding performance, a MIT license, and the ability to self-host or run outside US cloud infrastructure. On FrontierSWE - the benchmark that best captures real agentic coding work - it sits within 0.7 percentage points of Claude Opus 4.8 at one-sixth the cost. That gap, for most practical purposes, has closed.
The remaining weaknesses are real but bounded. The token verbosity adds cost at scale; abstract reasoning still trails Opus 4.8 by a cycle; and enterprises operating in regulated environments need to think carefully about Z.ai's API data routing before deploying at scale. For those concerns, self-hosting on H200 hardware is the answer - though the entry price for that's steep.
For anyone who has been waiting for a genuinely open, truly competitive coding model that doesn't require an US-resident API call or a closed-source licence agreement, the wait is over.
Score: 8.7/10
Sources
- GLM-5.2: Built for Long-Horizon Tasks - HuggingFace Blog
- Z.ai's open-weights GLM-5.2 beats GPT-5.5 on multiple long-horizon coding benchmarks - VentureBeat
- GLM-5.2 is the new leading open weights model on the Artificial Analysis Intelligence Index
- We have Mythos at Home: GLM 5.2 beats Claude in our Cyber Benchmarks - Semgrep
- GLM-5.2 Benchmarks 2026 - BenchLM.ai
- GLM-5.2 Just Beat GPT-5.5 at a Sixth of the Cost - Labellerr
- GLM 5.2 Is The New Best Open Model - Zvi Mowshowitz
- GLM-5.2 API - OpenRouter
- SWE-bench Pro Leaderboard 2026 - MorphLLM
- GLM-5.2 vs Llama 4 Maverick - DocsBot
- GLM 5.2 vs Claude Opus 4.8 vs GPT-5.5 - Lushbinary
- Deploy GLM-5.2 on GPU Cloud - Spheron
- zai-org/GLM-5.2 on Hugging Face
- GitHub - zai-org/GLM-5
