Gemma 4 Review: Google's Biggest Open-Source Bet
Google's Gemma 4 family - four models, full Apache 2.0 licensing, and benchmark scores that challenge models 10x their size - is the most consequential open-weight release of 2026 so far.

Google's Gemma team has been patient. The first two Gemma generations were technically solid but commercially awkward, hobbled by a proprietary license that made enterprise adoption more legal puzzle than engineering exercise. With Gemma 4, released April 2, Google changed the terms completely - four models, Apache 2.0 across the board, and benchmark numbers that put the 31B Dense variant in the top three on the global Chatbot Arena leaderboard. That last part gets the headlines, but the license is the story that matters for anyone actually building with these models.
TL;DR
- 8.2/10 - The best open-weight family available right now, held back mainly by MoE inference speed and early tooling roughness
- Apache 2.0 on all four variants is a genuine inflection point for enterprise and sovereign AI deployments
- The 26B MoE runs surprisingly slowly despite low active parameter count; KV cache memory consumption trails Qwen 3.5
- Best for: enterprises needing unrestricted deployment, developers wanting capable local inference, multilingual applications. Skip if: you need audio input at scale (31B/26B don't support it) or fine-tuning workflows are critical right now
Four Models, One License Change That Changes Everything
Gemma 4 ships in four variants that cover the range from edge deployment to workstation inference:
| Model | Architecture | Effective Params | Context | Multimodal |
|---|---|---|---|---|
| E2B | Dense | 2.3B active | 128K | Image, Video, Audio |
| E4B | Dense | 4.5B active | 128K | Image, Video, Audio |
| 26B A4B | MoE | 3.8B active | 256K | Image, Video |
| 31B | Dense | 30.7B | 256K | Image, Video |
The "E" prefix on the smaller models denotes "Effective" - the total parameter count including embeddings is higher (5.1B and 8B respectively), but the active compute matches the label. The 26B MoE activates only 3.8B parameters per forward pass, which explains why it fits comfortably on 16GB VRAM cards.
None of this is unusual for a 2026 model release. What's unusual is Apache 2.0 on all four at once.
Gemma 3 shipped under Google's custom "Gemma Terms of Use" - a license that required developers to enforce Google's acceptable-use policy on all downstream users, extended ambiguously to models trained on Gemma-generated synthetic data, and could be updated unilaterally. Legal teams at enterprises with actual compliance functions wouldn't touch it without months of review. Apache 2.0 eliminates all of that. No prohibited-use carve-outs requiring legal interpretation. No MAU limits. No obligation to police downstream users. The same terms Qwen, Mistral, and most of the open-source AI ecosystem already use - legal teams already have the approved boilerplate.
Nathan Lambert at Interconnects.ai called it correctly: this change will "massively boost adoption." The previous Gemma family reached 400 million community downloads under the restrictive license. The ceiling with Apache 2.0 is much higher.
Benchmark Performance: The Numbers Hold Up
The top-line figures from Google's announcement survived independent testing better than most lab claims do.
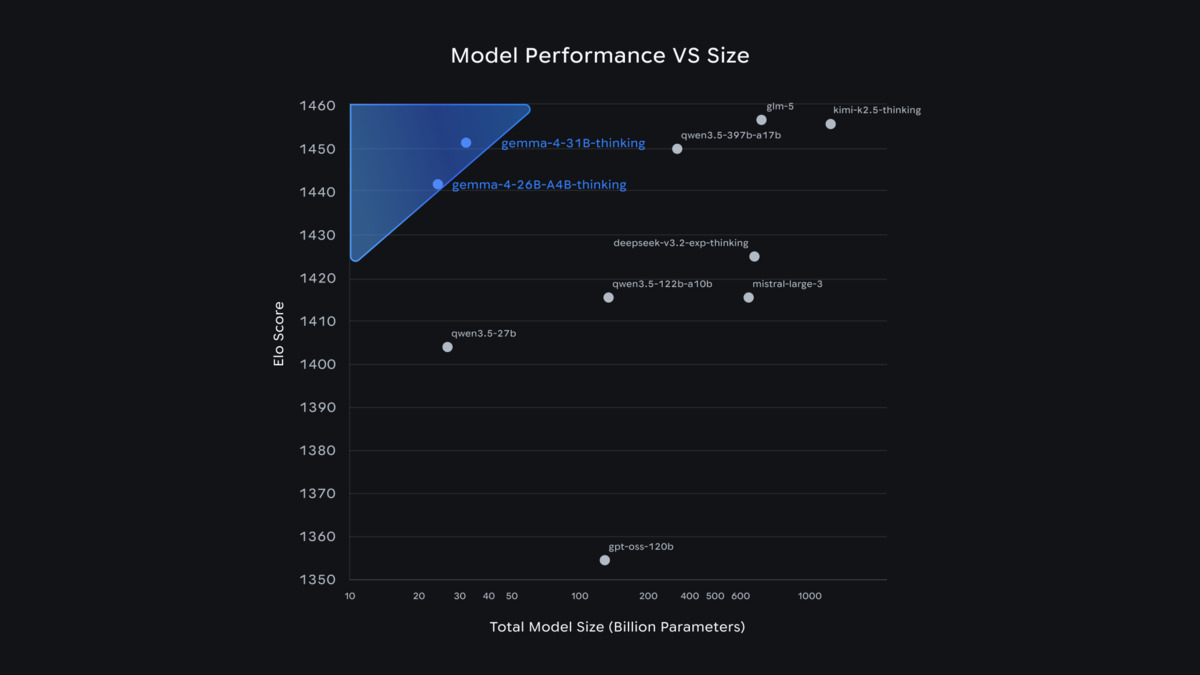 Gemma 4 31B ranks #3 globally on Chatbot Arena, above models with 10x more parameters.
Source: blog.google
Gemma 4 31B ranks #3 globally on Chatbot Arena, above models with 10x more parameters.
Source: blog.google
The 31B Dense model scores 84.3% on GPQA Diamond and 89.2% on AIME 2026 - the latter representing a jump of roughly 68 points over Gemma 3 27B. On LiveCodeBench v6 it scores 80.0%, which translates to a Codeforces ELO of 2150 (Grandmaster territory). The Chatbot Arena ELO of approximately 1452 places it third globally and first among US-accessible open models.
That last ranking matters. Llama 4 Maverick, which sits at Arena ELO ~1417, is nominally also an open-weight model - but Maverick's total parameter count is reported around 400B with 128 experts, requiring multi-GPU data-center setups most organizations can't access locally. Gemma 4 31B fits on a single consumer GPU with Q4 quantization. The comparison isn't entirely fair to Maverick, but from a practical deployment standpoint, Gemma 4 is the more accessible model with the competitive benchmark score.
The agentic performance improvement is the figure worth highlighting in context. The 31B model scores 86.4% on tau2-bench, up from 6.6% in Gemma 3. That isn't incremental improvement - it's a different model category. Google built native function calling via dedicated special tokens (the model produces tool calls in structured format rather than through prompt engineering hacks), native system instructions, and extended thinking via a enable_thinking=True parameter. For anyone building agent workflows, the capability gap between Gemma 3 and Gemma 4 is as large as the gap between Gemma 3 and a frontier proprietary model was a year ago.
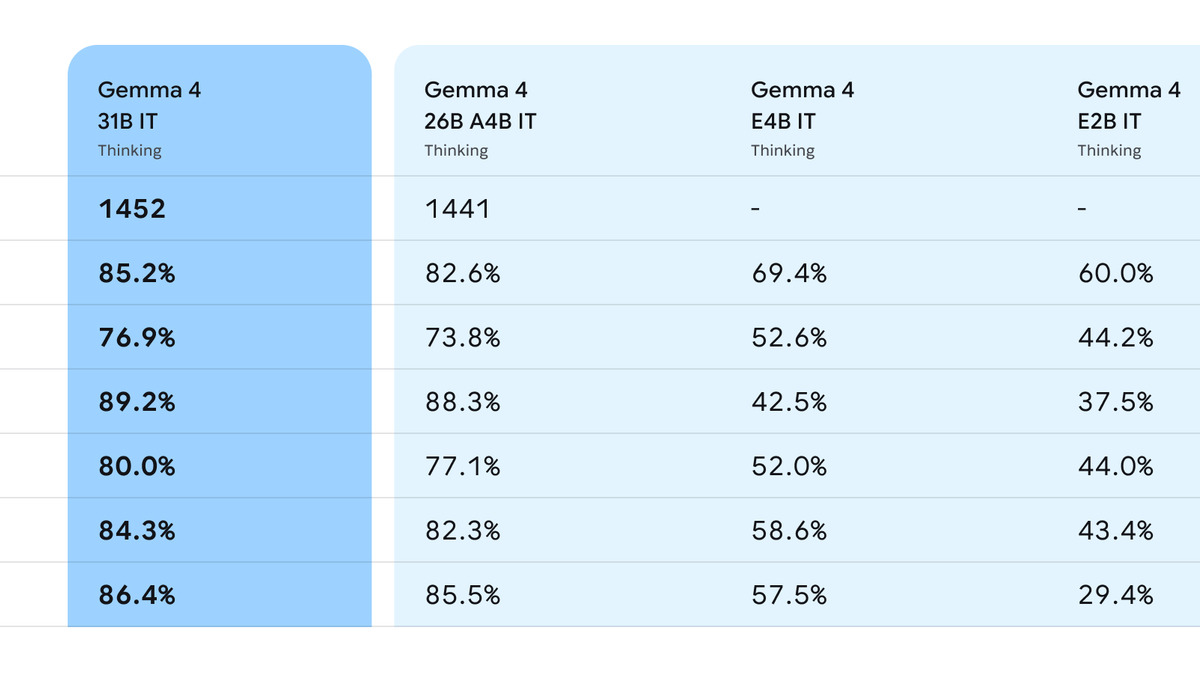 The full Gemma 4 family benchmark table, including Chatbot Arena comparisons across all four model sizes.
Source: blog.google
The full Gemma 4 family benchmark table, including Chatbot Arena comparisons across all four model sizes.
Source: blog.google
Architecture: Novel Enough to Cause Tooling Friction
The engineering under the hood is truly innovative and also the reason early adopters hit friction.
The E2B model - just 2.3B effective parameters - reportedly beats Gemma 3 27B on most benchmarks. That's not a gradual scaling result.
Gemma 4 uses hybrid attention with a 5:1 ratio of local sliding-window layers to global full-context layers, combined with dual RoPE embeddings (standard for sliding layers, proportional for global layers to enable the 256K context). The Per-Layer Embeddings system - a secondary embedding table feeding residual signals to every decoder layer - is distinctive and contributes to the performance-per-parameter efficiency that makes the E2B results so striking.
The vision encoder handles variable aspect ratios with configurable token budgets and multidimensional RoPE. The audio encoder in E2B and E4B uses an USM-style conformer architecture (the same base as Gemma 3n), capped at 30-second clips.
This is "very much not a standard transformer" in one community contributor's words, which is accurate and consequential. At launch, installing HuggingFace Transformers from source was required for the gemma4 architecture to be recognized. PEFT couldn't handle the new Gemma4ClippableLinear layer. Fine-tuning workflows were broken for the first days. The ecosystem needs roughly four to six weeks to stabilize around novel architectures - Qwen 3.5 went through the same adjustment period. If fine-tuning is on your near-term roadmap, waiting another month before committing is reasonable.
The MoE Speed Problem
The 26B A4B is the model most deployments will gravitate toward - it fits on cards with 16GB VRAM, matches the 31B on most agentic benchmarks, and reaches Arena ELO ~1441. There's one problem: it's slow.
Developers testing it on RTX 5060 Ti 16GB hardware reported roughly 11 tokens per second for the 26B A4B, compared to 60+ tokens/second for Qwen 3.5 35B-A3B on the same card. Qwen's MoE architecture routes tokens more efficiently, and the inference overhead of Gemma's hybrid attention layers compounds the issue. For interactive applications, this is a real constraint.
KV cache memory consumption is the second issue. The 31B's 256K context window is theoretically impressive, but on a single RTX 5090 one community benchmark found usable context capped at around 20K tokens when KV cache quantization was active - versus 190K tokens for Qwen 3.5 27B Q4 on the same card. The 256K context isn't useful under typical local inference setups at this model size.
This doesn't make the 26B A4B a bad choice. For batch processing, API access through Google's infrastructure (priced at $0.13 per million input tokens / $0.40 per million output tokens for the 26B variant), or applications where latency isn't the bottleneck, the capability-per-dollar is competitive. But the MoE inference overhead relative to Qwen 3.5 is real and reproducible.
Multilingual Performance Is a Genuine Differentiator
One area where community testing finds Gemma 4 clearly ahead: multilingual tasks.
Gemma 4 supports 140 languages natively. The 31B scores 88.4% on MMMLU, the multilingual MMLU variant, and users testing German, Arabic, Vietnamese, and French report Gemma 4 outperforming Qwen 3 on non-English tasks despite similar scores on English benchmarks. For applications targeting non-English-speaking markets, this matters more than the Arena ELO number.
The E2B and E4B models add 30-second audio input in 140 languages, which makes them viable for multilingual voice applications at edge scale. No other open-weight model at that parameter count offers both image and audio input simultaneously under Apache 2.0.
Strengths and Weaknesses
Strengths:
- Apache 2.0 across all four variants, with zero ambiguity for commercial and sovereign deployments
- 31B ranks #3 globally on Chatbot Arena, above models 10x larger
- 86.4% on tau2-bench signals truly capable agentic function calling
- E2B at 2.3B effective parameters beats Gemma 3 27B on most benchmarks
- Day-0 ecosystem support: Ollama, llama.cpp, LM Studio, MLX, transformers.js, Vertex AI
- 140-language support with leading multilingual benchmark scores
- Audio input on edge variants (E2B/E4B) under Apache 2.0 is unique at this parameter range
Weaknesses:
- 26B MoE inference speed significantly trails Qwen 3.5 on equivalent hardware
- KV cache memory efficiency limits practical 256K context on consumer GPUs
- Fine-tuning tooling was broken at launch; ecosystem stabilization needs more time
- 31B and 26B lack audio input completely (E2B/E4B only)
- Early reports of stability issues and jailbreak vulnerabilities at smaller sizes
- Long-context recall (MRCR v2) drops notably for E4B at 25.4% - the 128K window is less useful in practice than the spec implies
Verdict
Gemma 4 is the strongest open-weight model family available right now by the metrics that matter most for real deployments: license clarity, per-parameter performance, and ecosystem reach. The Apache 2.0 move isn't a marketing decision - it's what made news coverage of the release focus on actual capability rather than license gotchas for the first time in Gemma's history.
The 31B's benchmark numbers are legitimate. The agentic improvements are sizable. The multilingual support is the best in the open-weight tier. And 883,700 Ollama downloads in the first few days suggest the community recognizes what's on offer.
The friction points are real too. MoE inference speed, KV cache constraints, and immature fine-tuning tooling are issues that'll improve over the next month as the ecosystem catches up - but they exist now. If you're rolling out against a deadline this week, budget for the rough edges.
For most teams assessing open-weight models in April 2026, Gemma 4 is the default starting point. The open-source LLM leaderboard will need updating.
Score: 8.2 / 10
Sources
- Google Blog: Introducing Gemma 4
- HuggingFace Blog: Gemma 4 - The Open-Weight Multimodal Models
- Google DeepMind: Gemma 4 Model Page
- Google AI Dev: Gemma 4 Official Model Card
- Google Open Source Blog: Gemma 4 Apache 2.0 Announcement
- The Decoder: Google's Gemma 4 is now available with Apache 2.0 licensing for the first time
- VentureBeat: Google releases Gemma 4 under Apache 2.0
- Ollama: Gemma 4 Library Page
- PricePerToken: Gemma 4 26B-A4B Pricing
- Interconnects.ai: Gemma 4 and What Makes an Open Model
- DEV Community: Gemma 4 after 24 hours - What the Community Found
- Lushbinary: Gemma 4 vs Llama 4 vs Qwen 3.5 Comparison
- Google Cloud Blog: Gemma 4 on Vertex AI
- Latent.space AINews: Gemma 4 - The Best Small Multimodal

