Gemini 3.5 Flash Review: When Flash Surpasses Pro
Gemini 3.5 Flash leads on agentic benchmarks, runs 4x faster than Claude and GPT-5.5, and undercuts both on price - but a hidden long-context weakness and a 3x price hike over its predecessor deserve scrutiny.

Google launched Gemini 3.5 Flash at I/O 2026 on May 19 with a headline worth unpacking: a Flash-tier model that beats the previous Pro tier on nearly every agentic benchmark, runs four times faster than Claude Opus 4.7 and GPT-5.5, and costs about a third of either. After two days of testing API calls, reading the independent analyses, and parsing what the benchmark numbers actually say, my verdict is nuanced. Flash 3.5 is genuinely excellent at what it's built for. It's also not the bargain Google's marketing implies, and there's a long-context caveat that could catch teams off-guard if they skip the fine print.
TL;DR
- 8.5/10 - the best model for speed-sensitive agentic pipelines at this price point, but not the top coder
- Leads all frontier models on MCP Atlas tool-use (83.6%) and runs at 289 tok/s - roughly 4x Claude Opus 4.7
- Long-context retrieval collapses: MRCR v2 drops from 77.3% at 128K to 26.6% at 1M tokens
- Skip it for multi-file software engineering (SWE-Bench Pro 55.1% vs Claude Opus 4.7's 64.3%); use it for orchestration-heavy agent pipelines, document analysis, and high-volume API workloads
What Changed With 3.5
The Flash family has historically been Google's price-speed play - capable but clearly below the Pro tier on reasoning and instruction-following. That positioning ends here.
Gemini 3.5 Flash doesn't just beat the previous Flash models. On most of the benchmarks that matter for agentic AI - MCP Atlas, Toolathlon, Finance Agent v2 - it outscores Gemini 3.1 Pro. The model ships with configurable thinking levels (minimal, low, medium, high), native multimodal inputs across text, image, audio, video, and PDF, a 1 million token context window, and full MCP compatibility out of the box. It's the default model in the Gemini app and powers AI Mode in Google Search for over a billion monthly users - a deployment at a scale that very few model releases can claim.
The Artificial Analysis Intelligence Index places it 5th overall with a score of 55, sitting behind GPT-5.5 (60), Claude Opus 4.7 (57), and Gemini 3.1 Pro Preview (57). Fifth-place sounds modest, but that ranking measures general intelligence. The specific categories where agents actually spend their time - tool orchestration, multi-step task chains, long-form document analysis - are where Flash 3.5 leads.
Speed: The Real Differentiator
289 output tokens per second. That's the number that separates Gemini 3.5 Flash from everything in its competitive tier. For comparison, Claude Opus 4.7 outputs around 67 tok/s and GPT-5.5 runs at roughly 71 tok/s. Flash 3.5 is about four times faster on throughput.
For interactive applications this feels like a different product entirely. Responses that would take 15 seconds from Claude complete in under four. In multi-step agent pipelines - where each tool call blocks waiting for a model response - that four-to-one advantage compounds across every step.
There's a catch. Time to first token from Google AI Studio averages 18.55 seconds according to Artificial Analysis measurements. That's the latency between sending a request and seeing the first output token. For applications that show a typing indicator while waiting, nearly 19 seconds of silence before text starts flowing is a real user experience problem. For background batch jobs, it doesn't matter at all. Know which you're building before committing.
Thinking mode affects both dimensions. At medium (the default), the model applies enough reasoning to handle most agent tasks without meaningfully spiking latency. At high, response time increases markedly - similar to what you'd see from a dedicated reasoning model. At minimal, you get something closer to raw generation speed with reduced quality on complex prompts. The API uses a string enum: minimal, low, medium, high.
Agentic Performance
This is where Gemini 3.5 Flash earns its score.
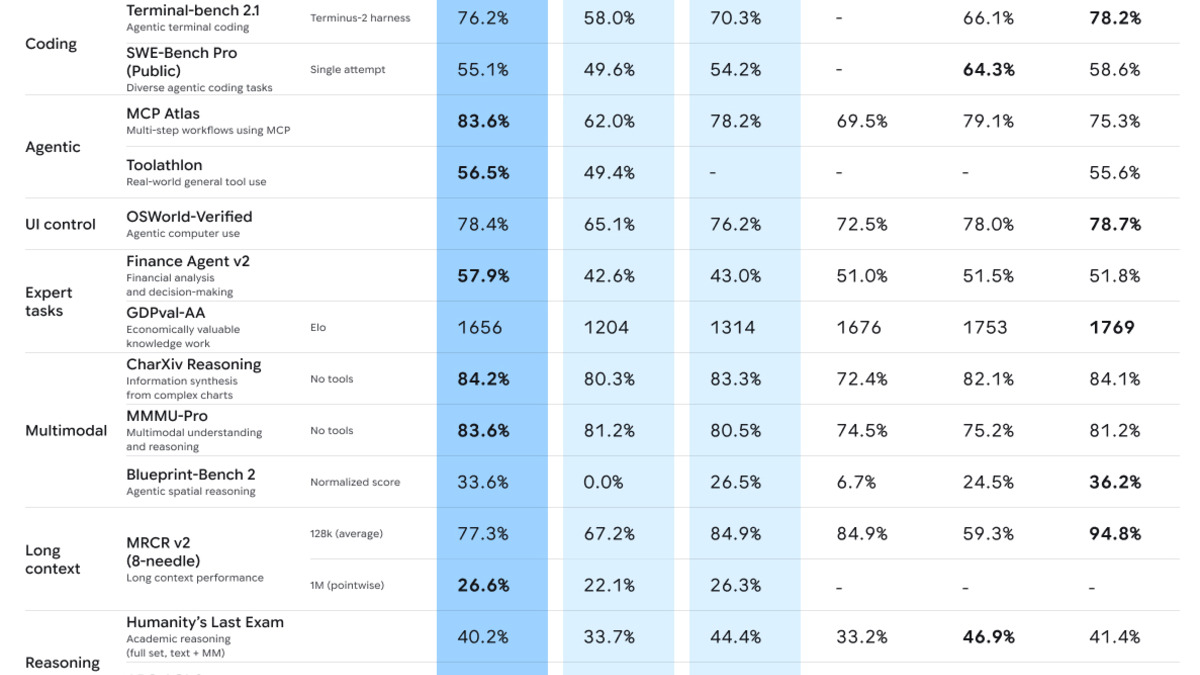
MCP Atlas measures scaled tool-use reliability across hundreds of tasks using the Model Context Protocol. Flash 3.5 hits 83.6%. Claude Opus 4.7 scores 79.1%. GPT-5.5 lands at 75.3%. That's not a narrow lead - it's eight points above the nearest OpenAI competitor on a benchmark that directly models what agentic pipelines do all day.
On Toolathlon, which tests a model's ability to select and chain the right tools across diverse task types, Flash again leads. Finance Agent v2, measuring autonomous financial analysis workflows, scores 57.9% against GPT-5.5's 51.8%.
The production evidence backs this up. Google announced deployments at Shopify (parallel subagent analysis for merchant forecasting), Macquarie Bank (document-heavy customer onboarding), Salesforce (multi-turn tool calling in Agentforce), Databricks (real-time diagnostic workflows), and Xero (autonomous tax form preparation). These aren't internal demos - they're live production workloads. The pattern is the same across all of them: long-horizon tasks that previously took human teams hours.
Flash 3.5 also powers Gemini Spark, Google's new personal AI agent that runs 24/7 on cloud infrastructure and integrates with Gmail, Docs, Slides, and third-party apps including Canva and Instacart. Spark is still in beta for AI Ultra subscribers, but it's built on this model - which tells you something about how Google rates its agentic reliability.
 Google's published benchmark comparisons for Gemini 3.5 Flash across agentic, coding, and reasoning categories.
Source: blog.google
Google's published benchmark comparisons for Gemini 3.5 Flash across agentic, coding, and reasoning categories.
Source: blog.google
Coding: Solid But Not the Leader
On software engineering, the picture is more complicated. Terminal-Bench 2.1 tests full terminal-based coding tasks including file editing, running builds, and debugging. Flash scores 76.2%. Gemini 3.1 Pro scored 68.5% - so it's a real improvement within the family. But GPT-5.5 scores 78.2% on the same benchmark, which means Flash isn't leading the field here either.
SWE-Bench Pro is where the gap becomes most visible. Claude Opus 4.7 scores 64.3% on repository-scale software engineering. GPT-5.5 posts 58.6%. Flash 3.5 lands at 55.1%. That's a nine-point deficit against Claude on the benchmark that most closely models real codebase work - multiple files, test suites, build systems, version history.
For generating code from a spec, single-file fixes, UI generation, and rapid prototyping, Flash 3.5 is very capable. Testing showed it creating complete responsive HTML/CSS layouts in under ten seconds. For multi-file refactors, complex debugging sessions requiring persistent state, or production-grade engineering where correctness matters more than speed, Claude Opus 4.7 maintains a clear edge.
The coding benchmarks leaderboard and SWE-Bench coding agent leaderboard have current rankings as independent evaluations come in.
Flash 3.5 is the right model for coordinating agents. It isn't the right model for deep software engineering.
The Long-Context Warning
Google's marketing leans hard on the 1 million token context window. The caveat is in the MRCR v2 scores, which test long-context retrieval - finding specific information across very long documents.
At 128K tokens, Flash 3.5 scores 77.3%. That's below Gemini 3.1 Pro's 84.9% at the same context length, which means 3.1 Pro already had an edge on long-document retrieval. At 1 million tokens, Flash 3.5 drops to 26.6%. That's not a graceful degradation - it's a cliff.
For tasks that load entire codebases, legal document sets, or research corpora into context and expect reliable retrieval, the 1M context window is more of a capacity claim than a reliability guarantee. At practical 128K lengths the model works well. Push into the hundreds of thousands and retrieval starts failing unpredictably.
This matters more than it might initially appear. The 1M context window is a headline feature. Customers building document analysis pipelines on the assumption that the model reliably reads all of it'll need to implement chunking and retrieval strategies anyway - which reduces the value of the large context window considerably.
 For single-file code generation and prototyping, Flash 3.5 is fast and capable. Multi-file engineering tasks are where Claude holds its lead.
Source: pexels.com
For single-file code generation and prototyping, Flash 3.5 is fast and capable. Multi-file engineering tasks are where Claude holds its lead.
Source: pexels.com
Pricing: The Real Numbers
"Gemini 3.5 Flash delivers frontier-level intelligence with exceptional speed, occupying the top-right quadrant of the Artificial Analysis Intelligence Index - the only model combining top-tier intelligence with industry-leading throughput." - Koray Kavukcuoglu, Google DeepMind, May 2026
Standard API pricing: $1.50 per million input tokens, $9.00 per million output tokens, $0.15 per million cached input tokens.
Against the flagship competitors, this is truly cheap. Claude Opus 4.7 runs $5.00/$25.00. GPT-5.5 runs $5.00/$30.00. Flash 3.5 costs 3.3x less on input and 2.8x to 3.3x less on output. For high-volume API workloads, that's a significant cost structure difference - VentureBeat reported Google's estimate that enterprises switching from competing flagships could save over $1 billion annually across large deployments.
Against the previous Flash generation, the picture shifts. Gemini 3 Flash ran at $0.50/$3.00 per million tokens. Flash 3.5 is 3x more expensive on both dimensions. Simon Willison benchmarked Flash 3.5 at high thinking mode and found the Artificial Analysis benchmark run cost $1,551.60 - notably more than running Gemini 3.1 Pro at $892.28. The "Flash is cheaper" framing is true relative to Claude and GPT-5.5. Relative to its own predecessor, Flash 3.5 is a major price increase.
Batch pricing halves the cost: $0.75 input/$4.50 output. Priority tier adds 80% for guaranteed capacity. Context caching stores at $1.00 per million token-hours. For the free tier, Google AI Studio provides daily request limits with no credit card required - it's the fastest way to evaluate the model before committing to API spend.
| Model | Input ($/M) | Output ($/M) | Speed (tok/s) |
|---|---|---|---|
| Gemini 3.5 Flash | $1.50 | $9.00 | 289 |
| Gemini 3.1 Pro | $2.50 | $15.00 | ~75 |
| Claude Opus 4.7 | $5.00 | $25.00 | 67 |
| GPT-5.5 | $5.00 | $30.00 | 71 |
| Gemini 3 Flash (prev) | $0.50 | $3.00 | ~200 |
Strengths
- Speed: 289 tok/s - four times Claude Opus 4.7 and GPT-5.5, no other frontier model is close
- Agentic tool-use: 83.6% on MCP Atlas leads the field by at least 4.5 points
- Price vs frontier: 3.3x cheaper than Claude Opus 4.7 and GPT-5.5 on input tokens
- Multimodal breadth: Native text, image, audio, video, and PDF inputs in one model
- Thinking flexibility: Four levels let you tune latency-quality tradeoff per request
- Production validation: Live at Shopify, Macquarie, Salesforce, Databricks, Xero, and in Google Search for 1B+ monthly users
Weaknesses
- SWE-Bench Pro at 55.1%: Nine points behind Claude Opus 4.7 on multi-file software engineering
- Long-context retrieval: MRCR v2 drops from 77.3% at 128K to 26.6% at 1M tokens
- No computer use: Desktop and browser automation isn't supported - use gemini-3-flash-preview if needed
- TTFT of 18.55s: Nearly 19 seconds to first token can feel slow in interactive applications
- 3x pricier than predecessor: Gemini 3 Flash was $0.50/$3.00 - this is a meaningful cost increase for existing users
- 5th on Intelligence Index: Scores 55 vs GPT-5.5's 60 and Claude/Gemini 3.1 Pro's 57 on general capability
Verdict
Gemini 3.5 Flash earns an 8.5/10 for what it's designed to do. It's the fastest frontier model by a wide margin, leads on agentic benchmarks that actually reflect production workloads, and undercuts its closest competitors on price. For teams running orchestration-heavy agent pipelines, high-volume document analysis, or workloads where throughput directly affects user experience, it's the right choice right now.
The caveats are real. Long-context retrieval at 1M tokens is unreliable enough that you should plan your architecture assuming it won't work. For intensive software engineering, Claude Opus 4.7 remains the more capable tool despite costing more. And if your existing workloads ran on Gemini 3 Flash, budget for a 3x price increase before switching.
The broader picture from Google I/O is a deliberate architectural bet: put the fastest, cheapest-per-frontier-quality model central to every agent deployment, and let speed and cost efficiency compound across billions of requests. For most agentic use cases, that bet holds. For the edge cases where it doesn't - deep coding, reliable 1M-token retrieval, computer use - Google's own lineup has alternatives, and competitors have leads.
For the full specifications, see the Gemini 3.5 Flash model card. For reasoning-heavy tasks where latency is acceptable, Gemini 3 Deep Think remains the strongest option in the Google family.
Sources
- Gemini 3.5: frontier intelligence with action - Google Blog
- Gemini 3.5 Flash Model Card - Google DeepMind
- Gemini 3.5 Flash: The new leader in intelligence versus speed - Artificial Analysis
- Gemini 3.5 Flash: API Provider Performance - Artificial Analysis
- Gemini 3.5 Flash: more expensive, but Google plan to use it for everything - Simon Willison
- Google Introduces Gemini 3.5 Flash at I/O 2026 - MarkTechPost
- Gemini 3.5 Flash vs Claude Opus 4.7 vs GPT-5.5 - Lushbinary
- Google introduces Gemini Spark, a 24/7 agentic assistant at I/O 2026 - TechCrunch
- Gemini 3.5 Flash places fifth on Artificial Analysis Intelligence Index - OfficeChai
- I/O 2026 developer highlights: Antigravity, Gemini API, AI Studio - Google Blog
