Claude Opus 4.7 Review: Coding Giant, Mixed Signals
Claude Opus 4.7 leads SWE-bench and agent benchmarks but regresses on web research, inflates token costs by up to 35%, and trades prose quality for literal instruction-following.

Four days after Anthropic announced Claude Opus 4.7, I've run it through coding agents, document analysis, multi-session pipelines, and long-form writing tasks. The headline version - "Anthropic's best generally available model, strongest coder in the field" - is accurate. What the press release skips is that Opus 4.7 is also a more opinionated, more expensive, and in some ways more limited model than 4.6. Both things are true.
TL;DR
- 9.1/10 - The strongest available coding and agent model, but with real trade-offs
- Leads SWE-bench Pro at 64.3%, MCP-Atlas at 77.3%, and CursorBench at 70%
- BrowseComp dropped 4.4 points; prose quality regressed; tokenizer inflates costs up to 35%
- Best for: engineering teams running production code agents, workflows with image-heavy content
- Skip if: your workflows are research-heavy, writing-focused, or budget-sensitive on API spend
What Changed from Opus 4.6
The simplest framing: Anthropic optimized hard for agentic coding and vision, and several other things got worse. This isn't a universal upgrade. Developers running software agents should see clear improvement. Writers and researchers may want to hold off or keep 4.6 in their stack for non-coding tasks.
The three structural changes that matter most:
New tokenizer. Opus 4.7 processes the same input text using 1.0-1.35x more tokens depending on content type. The rate card stays at $5/$25 per million tokens, but your actual spend rises 10-35% for identical prompts. For high-volume API users, this is a meaningful cost increase hidden behind an unchanged pricing page.
More literal instruction-following. The model follows prompts more exactly than 4.6. That's good for agents where ambiguity causes problems. It's bad for creative and writing tasks where 4.6 used to interpret instructions generously. Writers report that long-form prose has become more mechanical - the model now reaches for bullet points and headers where earlier versions held a flowing narrative.
Adaptive thinking only. Fixed budget_tokens is gone. Opus 4.7 uses adaptive thinking exclusively, where it judges reasoning depth based on perceived task complexity. The model decides when to think. You can influence this through effort levels but can no longer specify exact token budgets for reasoning.
April 16, 2026 - Claude Opus 4.7 ships on claude.ai, the API, Amazon Bedrock, Vertex AI, and Microsoft Foundry.
April 16, 2026 - New tokenizer goes live;
budget_tokensparameter deprecated;xhigheffort level added.April 18, 2026 - Partner benchmark results published by Cursor (70% CursorBench) and Rakuten (3x more tasks resolved on SWE-Bench variant).
Coding and Agentic Performance
On the benchmarks that matter for software development, Opus 4.7 is truly ahead. SWE-bench Pro - the harder, less-contaminated successor to SWE-bench Verified - shows the clearest gap: 64.3% for Opus 4.7 versus 57.7% for GPT-5.4 and 54.2% for Gemini 3.1 Pro. The 7-point lead over the nearest competitor is significant.
| Benchmark | Opus 4.7 | GPT-5.4 | Gemini 3.1 Pro |
|---|---|---|---|
| SWE-bench Pro | 64.3% | 57.7% | 54.2% |
| SWE-bench Verified | 87.6% | 84.1% | 80.6% |
| CursorBench | 70% | - | - |
| MCP-Atlas | 77.3% | 68.1% | 73.9% |
| Finance Agent | 64.4% | 61.5% | 59.7% |
| BigLaw Bench | 90.9% | - | - |
| Terminal-Bench | 69.4% | 75.1% | - |
| BrowseComp | 79.3% | 89.3% | 85.9% |
| GPQA Diamond | 94.2% | 94.4% | 94.3% |
| HLE (with tools) | 54.7% | 58.7% | - |
The partner results are worth taking seriously. Cursor's 70% on CursorBench (up from 58% on 4.6) and Rakuten's report of three times more tasks resolved on their SWE-Bench variant are third-party measurements under real production conditions, which carries more weight than internal evaluations.
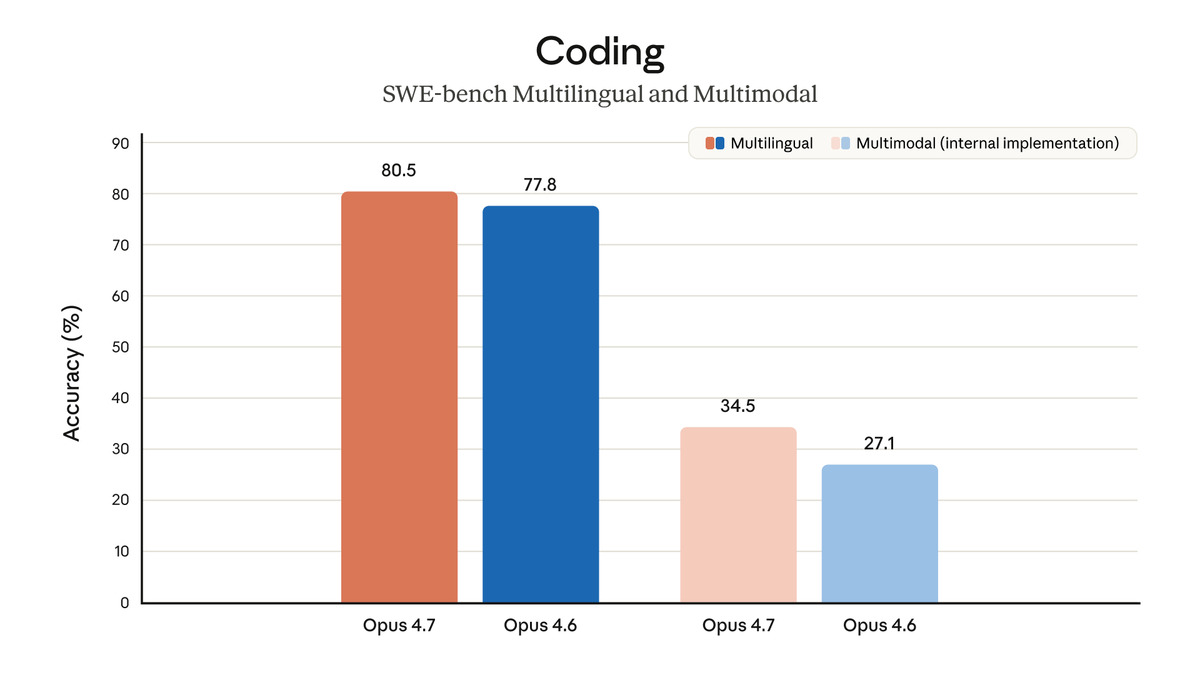 Official coding evaluation results from Anthropic's announcement, showing Opus 4.7's performance gains across SWE-bench and partner benchmarks.
Source: anthropic.com
Official coding evaluation results from Anthropic's announcement, showing Opus 4.7's performance gains across SWE-bench and partner benchmarks.
Source: anthropic.com
The MCP-Atlas lead is the one I find most compelling. At 77.3% - more than 9 points ahead of GPT-5.4 - Opus 4.7 is the clear choice for multi-tool orchestration. If your agents use a rich set of tools and need to coordinate across them, that gap is real and meaningful.
At 77.3% on MCP-Atlas, 9 points ahead of GPT-5.4, Opus 4.7 is the only serious choice for production multi-tool agents right now.
Vision at 3.75 Megapixels
The vision upgrade is larger than the headline number suggests. Opus 4.7 accepts images up to 2,576 pixels on the long edge, producing roughly 3.75 megapixels of visual capacity versus 1.15 megapixels in 4.6. On the visual navigation benchmark (without tools), the model jumps from 57.7% to 79.5% - a 22-point improvement that's hard to attribute to anything but the resolution increase.
In practice this matters for:
- UI and design review: Reading smaller text in screenshots, identifying alignment issues in mockups
- Document analysis: Processing dense PDFs and scanned reports without loss of fine detail
- Code screenshots: Catching variable names and line numbers that were previously unreadable
For teams processing images as part of their workflow, this is a genuine quality upgrade. It's also one place where Opus 4.7 creates clear daylight over GPT-5.4 and Gemini 3.1 Pro, neither of which matches this resolution tier.
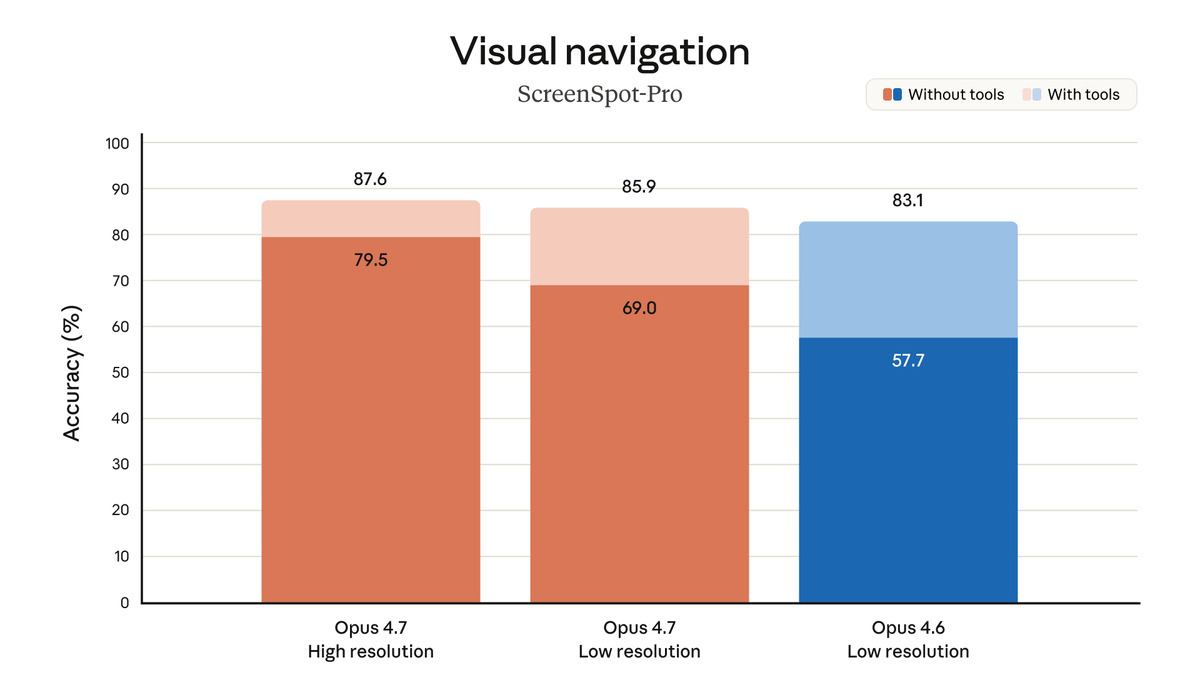 Vision benchmark results from Anthropic showing the visual navigation improvement from 57.7% to 79.5% with the higher-resolution input support.
Source: anthropic.com
Vision benchmark results from Anthropic showing the visual navigation improvement from 57.7% to 79.5% with the higher-resolution input support.
Source: anthropic.com
The New API Features
Task Budgets
Task budgets let you give Claude a rough token estimate for a full agentic loop - thinking, tool calls, tool results, and final output. The model sees a running countdown and adjusts its work accordingly, prioritizing tasks and finishing gracefully as the budget runs low. This is a soft suggestion, not a hard cap.
The practical value: Claude Code users who've burned through quota on runaway tasks now have a mechanism to bound long-running sessions. Combined with auto mode for all Max users, the risk of a single session consuming your entire daily allocation drops far.
xhigh Effort
Opus 4.7 adds a xhigh effort level that sits between high and max. The full ladder is now: low > medium > high > xhigh > max. Claude Code defaults to xhigh for all plans.
The intent is to give most of max's reasoning depth at lower latency and cost. Anthropic recommends xhigh for coding and agentic tasks and high as a minimum for intelligence-sensitive work. For API users running high-volume pipelines, this new rung on the ladder is a useful calibration point.
File-System Memory Across Sessions
Opus 4.7 is measurably better at reading, writing, and reusing notes stored in persistent files across multiple agent sessions. Agents that maintain scratchpads or structured memory stores should see improvement without prompt changes. For engineering teams building agents that work over days rather than minutes, this removes some of the context reconstruction overhead at the start of each session.
Regressions and Rough Edges
The regressions are real and worth stating plainly.
BrowseComp dropped from 83.7% to 79.3%. This is a nearly 5-point regression on web research tasks. GPT-5.4 Pro scores 89.3% on the same benchmark. If your agents do major web browsing and synthesis, Opus 4.7 is a step backward from 4.6 for this specific workload.
Humanity's Last Exam with tools: 54.7%, trailing GPT-5.4 at 58.7%. On the hardest knowledge and reasoning questions, where tool use provides an advantage, Opus 4.7 isn't leading. The gap is modest but consistent with a pattern: where tasks require broad knowledge retrieval across many domains, GPT-5.4 currently edges ahead.
Visible reasoning is gone. Developers who built workflows around watching Claude's thinking process will find it missing. Opus 4.7 changed default handling of reasoning summaries - the model pauses, then produces an answer, with no visible chain of thought. This breaks pipelines that expected 4.6-style reasoning output and provides less signal for debugging agent failures.
Prose quality degraded. This is subjective but consistent across multiple user reports. Long-form writing tasks produce more structured, more mechanical output. The model reaches for bullet points. Paragraphs feel chopped. Writers who used 4.6 for drafts should test before switching.
Terminal-Bench at 69.4%, behind GPT-5.4's 75.1%. On terminal emulation tasks, Opus 4.7 trails the competition by nearly 6 points.
Pricing: Same Rate Card, Higher Bills
The $5/$25 pricing is unchanged. The new tokenizer isn't.
For identical input text, Opus 4.7 may create up to 35% more tokens. A prompt that consumed 10,000 tokens in 4.6 could consume 13,500 in 4.7. The math on output costs is similar. For teams spending $10,000/month on Opus 4.6 API calls, migrating to 4.7 without prompt optimization could mean $11,000-$13,500 for the same work.
Anthropic acknowledges the tokenizer change but frames it as favorable for coding evaluations. That framing is accurate for pure coding tasks where the new tokenizer encodes code more efficiently. It does not apply uniformly across natural language inputs.
Practical recommendation: before switching production workloads, run a sample of your actual prompts through the 4.7 tokenizer and measure the difference. Anthropic's migration guide suggests a 1x-1.35x range; your real-world number will be content-dependent.
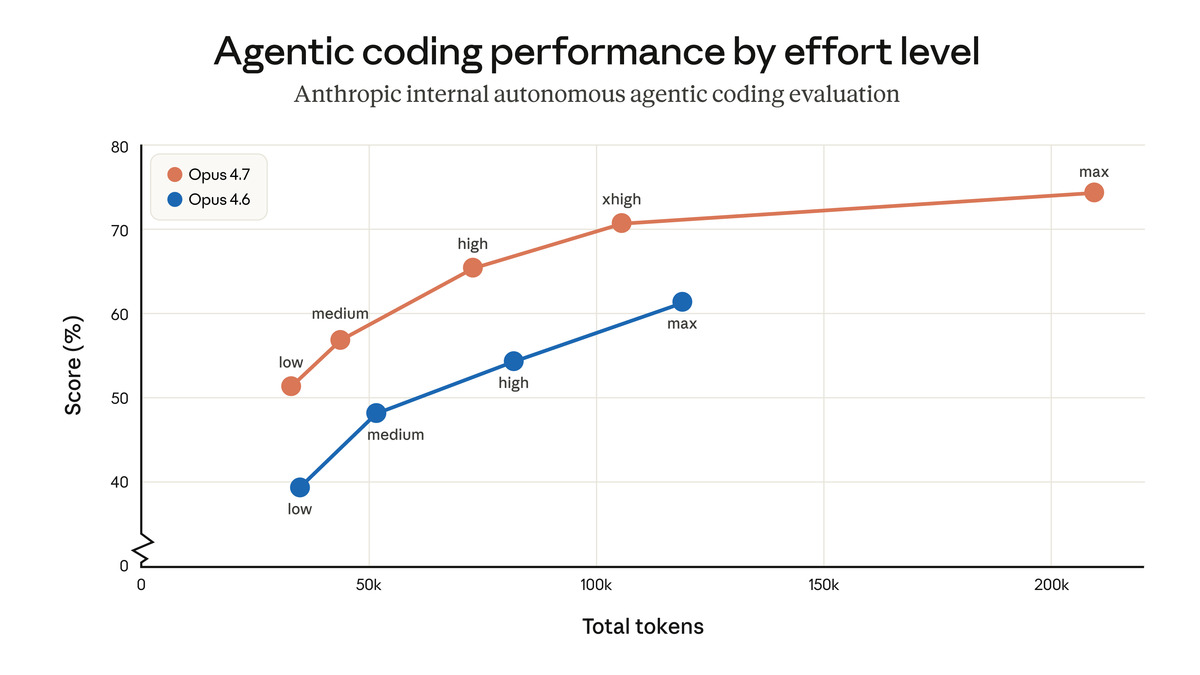 Token usage comparison from Anthropic showing how the new tokenizer affects input costs across different content types.
Source: anthropic.com
Token usage comparison from Anthropic showing how the new tokenizer affects input costs across different content types.
Source: anthropic.com
Strengths
- Leads SWE-bench Pro, SWE-bench Verified, MCP-Atlas, and Finance Agent benchmarks
- 3.75 megapixel vision is the strongest in the current flagship tier
- Task budgets and
xhigheffort give meaningful control over long-running agents - File-system memory improvements are practical and don't require prompt changes
- Partner evaluations from Cursor and Rakuten verify the coding gains with real production data
- Prompt caching and batch pricing unchanged - up to 90% savings still apply
Weaknesses
- BrowseComp regressed nearly 5 points; not the model for research-heavy agents
- Tokenizer inflates real costs 10-35% despite unchanged rate card
- Prose and long-form writing quality declined noticeably
- Visible reasoning removed; breaks pipelines that depended on 4.6 reasoning output
- Trailing GPT-5.4 on Terminal-Bench and Humanity's Last Exam with tools
- Adaptive thinking misreads some tasks that look simple but aren't
Verdict
Claude Opus 4.7 is the right model if you're running production code agents and your billing tolerance for a 35% token increase is manageable. The SWE-bench and MCP-Atlas leads are not marginal - they represent real improvement on the tasks that define modern software engineering agents. The vision upgrade is sizable and opens use cases that weren't viable at 1.15 megapixels.
The Opus 4.6 review gave that model a 9.3/10 largely for its combination of breadth and safety. Opus 4.7 is a narrower model - sharper where it shines, worse where it regresses. For an agent engineering team, that trade is probably worth making. For a solo developer using Claude for a mix of coding, research, and writing, the calculus is less clear, and Opus 4.6 remains the safer default while the rough edges get smoothed out.
Score: 9.1/10
Sources
- Anthropic - Claude Opus 4.7 Announcement
- Anthropic - What's New in Claude Opus 4.7 (Docs)
- Anthropic - Effort Levels Documentation
- Anthropic - Adaptive Thinking Documentation
- VentureBeat - Anthropic releases Claude Opus 4.7
- The Next Web - Claude Opus 4.7 leads on SWE-bench and agentic reasoning
- Vellum AI - Claude Opus 4.7 Benchmarks Explained
- Finout - Claude Opus 4.7 Pricing: The Real Cost Story
- Artificial Analysis - Claude Opus 4.7 Intelligence and Performance
- Caylent - Claude Opus 4.7 Deep Dive: Migration and the New Economics of Agents
- The AI Corner - Claude Opus 4.7: benchmarks, features, and migration guide
- TokenDock - Claude Opus 4.7: What Users Are Saying After the Launch
Last updated
