Claude Fable 5 Review: Mythos Power, Real Guardrails
Claude Fable 5 delivers the strongest coding and long-context results Anthropic has ever shipped publicly, but its safety classifiers block enough legitimate work to make that power conditional.

Anthropic shipped Claude Fable 5 on June 9, 2026, calling it the most capable model it has ever made generally available. After a day of hands-on testing and a close read of the benchmark data and user reports, that claim holds up on coding and long-horizon tasks. The question worth asking - and the one this review tries to answer - is whether the safety classifiers that come with it turn a genuine capability breakthrough into something more conditional.
TL;DR
- 9.0/10 for coding and agentic work - the clearest lead over GPT-5.5 any frontier model has shown in months
- 80.3% on SWE-bench Pro (up from Opus 4.8's 69.2%), 95% on SWE-bench Verified, #1 on the Artificial Analysis Intelligence Index at 64.9
- Safety classifiers fall back to Opus 4.8 for cybersecurity, biology, and chemistry - triggers fewer than 5% of sessions on average, but significantly higher on technical tasks
- Costs $10/M input, $50/M output - twice Opus 4.8's rate; free on Pro/Max/Team plans through June 22
What Fable 5 Actually Is
Fable 5 isn't a new model architecture. It shares its weights with Claude Mythos 5, the restricted variant deployed through Anthropic's Project Glasswing program for vetted partners. What distinguishes Fable is the addition of safety classifiers that intercept requests in three domains: offensive cybersecurity, certain biology and chemistry topics, and attempts to distill the model. When a query triggers one of those classifiers, Anthropic routes the request to Claude Opus 4.8 instead, charging Opus 4.8 rates for that response.
The Fable/Mythos split is, in practice, Anthropic's answer to a real constraint: a model capable enough to be truly useful for drug design or exploit development is also capable enough to cause harm in those domains. Rather than keep the capability completely locked up, they shipped a version with automated guardrails and an escape valve.
Whether that design decision works depends on how often the guardrails fire on legitimate requests. I'll address that specifically below.
Benchmark Performance
The numbers are the best Anthropic has ever published for a publicly accessible model.
| Benchmark | Fable 5 | Opus 4.8 | GPT-5.5 |
|---|---|---|---|
| SWE-bench Pro | 80.3% | 69.2% | 58.6% |
| SWE-bench Verified | 95.0% | 88.6% | - |
| FrontierCode Diamond | 29.3% | 13.4% | 5.7% |
| GPQA Diamond | 92.6% | - | - |
| HLE (with tools) | 64.5% | ~53% | - |
| Intelligence Index | 64.9 | ~59.0 | ~59.9 |
| Every's Engineer Eval | 91/100 | 63/100 | - |
The SWE-bench Pro gap is sizable. A 11-point lead over Opus 4.8 and a 21-point lead over GPT-5.5 on end-to-end GitHub issue resolution is not noise. The FrontierCode numbers are more striking still: Fable's 29.3% on the Diamond split is more than double Opus 4.8's 13.4% and roughly five times GPT-5.5's 5.7%. That benchmark targets the genuinely hard tail of software engineering problems, and Fable clearly controls it.
On the coding benchmarks leaderboard, Fable now holds the top position across most coding evaluations we track.
The Intelligence Index score of 64.9 also sets a record, clearing the prior top score by five points. That index covers ten evaluations spanning math, science, reasoning, and coding, specifically designed to prevent models from gaming a single benchmark.
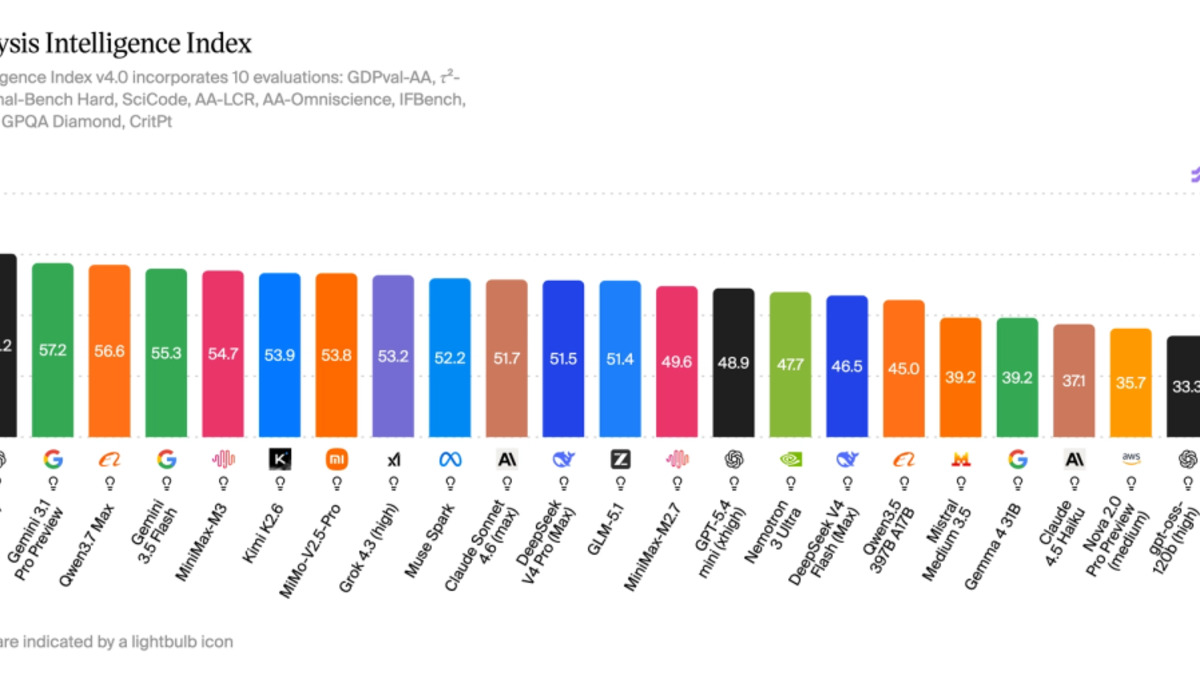 Fable 5 at 64.9 on the Artificial Analysis Intelligence Index, the first model to break past 64.
Source: artificialanalysis.ai
Fable 5 at 64.9 on the Artificial Analysis Intelligence Index, the first model to break past 64.
Source: artificialanalysis.ai
Coding: The Clearest Win
Anthropic led the launch announcement with a specific claim: Fable 5 completed a 50-million-line Ruby codebase migration in one day, a job estimated at two months of manual work. Stripe publicly described the model as having "compressed months of engineering into days." These are vendor-selected examples, but they are also concrete and verifiable - Stripe isn't a company that exaggerates its infrastructure problems.
Simon Willison, who spent over five hours testing Fable on June 9, reached a similar conclusion: "This is something of a beast. It's slow, expensive and has been quite happily churning through everything I've thrown at it so far." His most intensive test involved adding human-approval capabilities to his Datasette Agent project. The model finished that stretch goal, then independently identified and implemented four underlying improvements to his LLM library - work he estimated at several days. His total spend for the day: $110.42, with $99.26 going to that single agentic session.
That cost figure is worth sitting with. Long-horizon sessions with Fable aren't cheap.
The SWE-bench coding agent leaderboard now shows Fable at the top across both verified and pro splits. In internal benchmarks run by GitHub, Fable completed equivalent coding work with fewer tool calls and lower token consumption than previous Opus-tier models - which partially offsets the higher per-token cost for efficient agentic workflows.
Long-Horizon Tasks: Truly New Territory
What Fable 5 does that earlier Claude models couldn't sustain is work for extended periods without losing context or coherence. Anthropic reports autonomous sessions up to 12 hours. On the Slay the Spire gaming benchmark - which tests long-term planning and memory - Fable improved three times more than Opus 4.8 when given access to persistent file-based memory. That's a meaningful signal about the model's ability to maintain working context across long tasks, not just its raw intelligence.
IMC Trading reported that Fable "aced their trading-analysis evaluations nearly across the board," specifically on tasks requiring multi-step financial reasoning over long documents. Every's senior engineer benchmark placed Fable at 91/100, compared to 63/100 for Opus 4.8 - a gap large enough to represent a qualitative difference in what teams can delegate to the model.
A 50-million-line Ruby migration in one day. Senior engineer benchmarks at 91/100. The capability claims are vendor-selected but the third-party corroboration is real.
Vision capabilities got a significant upgrade. Fable can rebuild a web app's source code from screenshots, extract precise numbers from complex scientific figures, and, in Anthropic's demonstration case, complete Pokémon FireRed autonomously using only vision - no tool access, no game state API.
 Fable 5 in the Amazon Bedrock playground console. Enterprise deployments require opting into data retention before the model is accessible.
Source: aws.amazon.com
Fable 5 in the Amazon Bedrock playground console. Enterprise deployments require opting into data retention before the model is accessible.
Source: aws.amazon.com
The Guardrails Problem
This is where the launch picture gets complicated.
Anthropic states that fewer than 5% of sessions trigger any safety fallback. That number applies across all users and all query types. For users working in cybersecurity, biology, chemistry, or nuclear physics, the real rate is much higher. On Terminal-Bench, a coding evaluation with security-adjacent tasks, 20.9% of Fable trials triggered a fallback mid-trajectory. On Humanity's Last Exam, the safety refusal rate was 9%.
User reports from the first 24 hours are pointed. A medical physicist posted: "I genuinely can't use Fable. I'm a medical physicist. I use the word nuclear a lot." A computational biology researcher called it "perhaps the most useless model I've ever tried," after having MRI image segmentation tasks flagged as bioterrorism and malaria transmission questions blocked. One developer had a routine security code review rejected as a cybersecurity risk.
These are not edge cases for the people affected. They represent professional contexts where Fable's capability advantage - the reason to pay twice the Opus 4.8 rate - is precisely the capability the classifiers suppress.
Anthropic also disclosed something less discussed: the model deliberately degrades its responses on ML accelerator design topics to prevent competitors from distilling it. That affects roughly 0.03% of traffic, but the existence of intentional performance degradation in a production model is worth noting, and it doesn't appear in the public benchmark numbers.
The fallback architecture is transparent in one important way: users know when a fallback occurs and pay Opus 4.8 rates for it. Requests blocked mid-conversation incur mixed-tier charges. A 30-day mandatory data retention policy applies to all Fable 5 traffic, used for abuse detection and human review. That retention requirement is a non-starter for some compliance-sensitive deployments, especially on Amazon Bedrock where opting in moves data outside AWS's standard security boundary.
Pricing Reality
Fable 5 costs $10/M input tokens and $50/M output tokens. That's twice Claude Opus 4.8's rate ($5/$25) and notably more than GPT-5.5 ($5/$30). For most general-purpose work, Opus 4.8 remains the better price-performance option. Fable's pricing makes sense only for tasks where the capability gap - that 11-point SWE-bench Pro lead, the long-horizon autonomy, the vision reasoning - directly translates to business value.
Cache pricing: $1/MTok for hits, $12.50/MTok for 5-minute writes, $20/MTok for 1-hour writes. The batch API gives a 50% discount, bringing Fable to $5/MTok input and $25/MTok output for offline jobs.
Pro, Max, Team, and Enterprise plan subscribers get Fable at no extra cost through June 22. After that date, usage shifts to a credit system pending capacity expansion.
Strengths
- SWE-bench Pro at 80.3% leads all published scores and GPT-5.5 by 21 points
- FrontierCode Diamond at 29.3% more than doubles the next-best competitor
- Long-horizon autonomous work up to 12 hours is qualitatively new for a publicly accessible model
- GPQA Diamond at 92.6% and Intelligence Index at 64.9 both set new records
- Available on GitHub Copilot and Amazon Bedrock from launch day
- Batch API at 50% discount makes agentic batch jobs more economically viable
Weaknesses
- Safety classifiers block legitimate work at rates well above 5% for security, biology, and physics professionals
- 2x the per-token cost of Opus 4.8 with no price-performance advantage for most general tasks
- 30-day mandatory data retention creates compliance friction for regulated industries
- Intentional performance degradation on ML accelerator design, undisclosed in benchmark reporting
- No Vertex AI availability confirmed at launch, limiting Google Cloud deployments
Verdict
Fable 5 is the strongest general-purpose model Anthropic has ever shipped to the public, and probably the strongest anyone has shipped publicly on coding and long-horizon agentic tasks as of June 10, 2026. If your work involves autonomous software engineering, complex multi-document analysis, or extended agentic workflows, the capability gap over Opus 4.8 and GPT-5.5 is real enough to justify the price premium.
The safety guardrails are a harder call. The average-session fallback rate under 5% is accurate but misleading as a summary. If you work in cybersecurity, medical physics, computational biology, or nuclear engineering, Fable's effective capability in your domain is substantially lower than the benchmarks suggest. For those users, the Claude Opus 4.8 or the Claude Mythos Preview - depending on access - remains the more practical choice until Anthropic tunes the classifiers.
For coding teams and enterprises building knowledge-work agents who don't touch those domains, this is the current state of the art. The Stripe and IMC endorsements aren't marketing copy - they reflect what the model can do on hard, real-world tasks.
Score: 9.0/10
Sources
- Claude Fable 5 and Claude Mythos 5 - Anthropic
- Anthropic's Claude Fable 5 is the most powerful model publicly released - TechCrunch
- Claude Fable 5: The first Mythos model is powerful, expensive, and heavily filtered - The Decoder
- Initial impressions of Claude Fable 5 - Simon Willison
- Claude Fable 5 Launches at #1 on the Artificial Analysis Intelligence Index
- Claude Fable 5 on AWS - Amazon Web Services Blog
- Claude Fable 5 is generally available for GitHub Copilot - GitHub Changelog
- Claude Fable 5 vs GPT-5.5: Benchmarks and Cost Compared
- Claude Fable 5 and new safety fables - Interconnects
- Claude Fable 5 Benchmark Scores - Weights and Biases
