Augment Code Intent Review: Orchestration Over Code
Augment Code Intent takes a spec-first, multi-agent approach to coding that challenges whether we still need IDEs at all.

The premise behind Augment Code's Intent is deceptively simple: the bottleneck in software development is no longer writing code, it's coordinating agents that write it for you. That shift in framing leads to a product unlike anything else in the agentic coding space - a macOS desktop app that isn't an IDE, isn't a chatbot plugin, and doesn't pretend the single-agent-in-a-terminal model is enough for serious engineering work.
TL;DR
- 7.8/10 - a truly novel architecture that outperforms Claude Code and Cursor on SWE-bench Pro, hamstrung by macOS-only availability and beta instability
- Spec-driven, parallel multi-agent execution with git worktree isolation is a real advancement over single-agent tools
- Windows is on a waitlist with no timeline; Linux doesn't exist on the roadmap at all
- Worth a trial for macOS-using teams on large codebases; skip for now if you're on Windows or Linux
Intent launched in public beta on February 26, 2026. I've spent the past two weeks using it on a real codebase - a mid-sized TypeScript monorepo with 180,000 lines across four services - and what I found is a product that is genuinely ahead on architecture while still catching up on reliability. The distance between those two things matters a lot depending on what you're willing to tolerate.
What Intent Actually Is
It helps to start with what Intent isn't. It's not a Cursor competitor. It's not a smarter Cline. It shares some surface features with Devin - both are agent-first rather than human-coding-first - but the execution model is different in ways that matter.
Intent is an orchestration workspace. You don't write code in it (there's a code editor, but it's there for the agents, not for you). You write a spec - a structured document defining requirements, acceptance criteria, data models, and API contracts - and then Intent fans that spec out to a team of agents that run in parallel, each in its own isolated git worktree on your local machine.
The three-tier architecture works as follows:
- A Coordinator agent reads your codebase via Augment's Context Engine, analyzes your spec, and decomposes it into tasks with explicit dependencies
- Up to six specialist Implementor agents - Investigate, Implement, Verify, Critique, Debug, and Code Review - execute those tasks in parallel, each with their own branch
- A Verifier agent checks results against the original spec before surfacing them for your review
Nothing merges without you approving it. There are three human gates in the workflow: spec approval, task decomposition review, and final diff review before the PR. This is where Intent differs most sharply from the "just let it run" philosophy of cloud-based agents - the assumption is that you want control, not delegation.
The Living Spec - Intent's Core Primitive
The most interesting design choice in Intent isn't the multi-agent architecture; plenty of tools bolt parallel agents together. It's the living spec.
Most agentic coding workflows rely on conversational context that gets stale, compressed, or lost. Intent replaces this with a spec document that both the developer and all agents read from and write to. When an agent completes a task, the spec updates to reflect what was actually built. When you change requirements mid-run, the update propagates to agents that haven't started their tasks yet.
The living spec is what separates coordinated multi-agent work from "four agents arguing in different terminals."
This addresses a real problem I've run into with Claude Code's subagent model (reviewed here): when you spawn multiple concurrent sessions, they work from whatever you gave them at invocation time. If one agent discovers that a shared interface needs changing, communicating that back to sibling sessions requires manual intervention. In Intent, the spec handles that coordination automatically.
In practice, it works well for greenfield features with clear acceptance criteria. It works less well for vague exploratory tasks - which is, honestly, a fair constraint. The spec-first model requires you to know what you want before you start, and that discipline is either a feature or a frustration depending on your working style.
Context Engine: Indexed, Not Guessed
 The Intent workspace showing spec-driven task decomposition and the agent coordination panel.
Source: augmentcode.com
The Intent workspace showing spec-driven task decomposition and the agent coordination panel.
Source: augmentcode.com
The second major differentiator is Augment's Context Engine. Every other tool in this category - Cline, Windsurf, even Claude Code - relies on some combination of file embeddings, keyword search, or session-built up context to figure out what code is relevant to a given task. The Context Engine takes a different approach: it builds a semantic dependency graph of the entire codebase.
This isn't just a better vector search. The engine understands call graphs, indirect dependencies (event systems, queues, pub/sub triggers), deprecated vs. active patterns, and cross-repo relationships. Augment's documentation gives a concrete example: finding a BCrypt utility function buried in a utility module that grep would never locate without knowing the right search terms. The Context Engine surfaces it because it understands the dependency chain from the task to the function, not because a keyword matched.
Indexing is fast. My 180,000-line monorepo finished initial indexing in just under four minutes. Incremental updates after commits took around 40 seconds.
The catch: the Context Engine is Augment's proprietary system. If you use Intent's "bring your own agent" (BYOA) feature - which lets you connect Claude Code, Codex, or OpenCode instead of Augment's own Auggie agents - you get the orchestration layer but not the Context Engine. Third-party agents receive "more limited context" per the documentation. This is where the product's value hierarchy becomes clear: Intent without the Context Engine is a workflow tool; Intent with it's a qualitatively different experience.
Benchmark Numbers
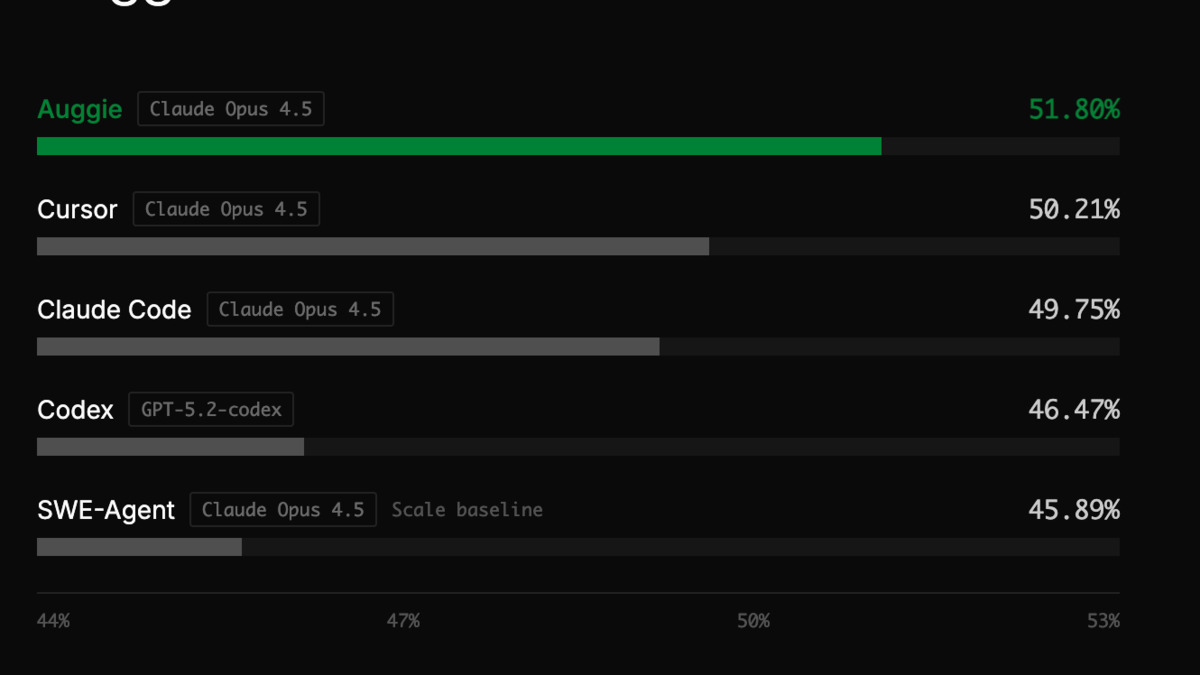 Augment's own benchmark results showing Auggie topping SWE-bench Pro at 51.80% against Claude Code at 49.75% and Cursor at 50.21%.
Source: augmentcode.com
Augment's own benchmark results showing Auggie topping SWE-bench Pro at 51.80% against Claude Code at 49.75% and Cursor at 50.21%.
Source: augmentcode.com
On SWE-bench Pro - Scale AI's harder version of the standard benchmark, using multi-file, multi-language tasks averaging 4.1 files and 107 code changes - Auggie (running on Claude Opus 4.5) scored 51.80%. Cursor on the same model scored 50.21%, and Claude Code scored 49.75%. The gaps are real but narrow: 1.6 percentage points over Cursor, 2.1 over Claude Code.
The appropriate response to these numbers is skepticism. First, this is Augment's own benchmark data. Second, SWE-bench Pro is still an academic proxy, not a measure of how useful a tool is on your actual codebase. Third, the improvements likely come at least partly from the Context Engine's context curation, not from Intent's orchestration model alone.
That said, the direction of the finding matches what I observed in my own testing. On tasks requiring changes across multiple files in different services, Intent consistently surfaced more relevant context than I got from Claude Code alone. Whether the Auggie agents themselves are better than Claude Code is harder to disentangle from the Context Engine advantage.
A relevant data point from Augment's own comparison pages: Claude Code's Claude Opus 4.6 achieves around 80.9% on SWE-bench Verified, which is a different (and arguably easier) benchmark. The two scores aren't directly comparable. Augment doesn't dispute this; their positioning is that SWE-bench Pro's multi-file, multi-service structure is closer to real enterprise work. That's a defensible argument.
Pricing: Credit-Based, With a Free Path In
Augment Code uses a unified credit system across all its products.
| Plan | Price | Credits |
|---|---|---|
| Community | Free | 50 user messages/month |
| Indie | $20/month | 40,000 credits |
| Standard | $60/month | 130,000 pooled (up to 20 users) |
| Max | $200/month | 450,000 pooled (up to 20 users) |
Task cost varies with complexity: small tasks run around 300 credits, complex multi-service features around 4,300. At Indie pricing, that's roughly 9 complex tasks per month before you hit the ceiling, or 133 small ones.
The BYOA path changes the math. Bring your existing Claude Code or Codex subscription, and you get Intent's orchestration, spec management, and git worktree isolation without paying for Augment credits. You lose the Context Engine, but for developers who already pay for frontier model access, this is a reasonable way to trial the workflow without additional subscription cost.
What I Actually Tested
I ran Intent on four real tasks over two weeks:
Feature addition (TypeScript API service, 3 files): The coordinator's task decomposition was clean. It correctly identified a shared type dependency between two implementor agents and serialized those tasks rather than running them in parallel. The final PR needed minor cleanup in test coverage but merged without rework on the core logic.
Cross-service refactoring (4 services, interface change): This is where Intent's architecture earns its pricing. A manual Claude Code session would have required me to manage context carefully across services. Intent's Context Engine found all the call sites automatically. One implementor agent made an incorrect assumption about an event schema, which the Verifier caught before it surfaced to me.
Debug session (production bug, 2 files): Intent is overengineered for single-file or two-file bugs. The coordinator overhead adds friction that a direct Claude Code session doesn't have. I ended up switching to Claude Code for this one.
Documentation generation (README and API docs): Effective, fast, and the spec format translated naturally to documentation structure. Probably not the use case Augment optimized for, but it worked well.
The honest summary: Intent earns its overhead on tasks that span multiple files and services. It's the wrong tool for targeted, scope-limited work.
Strengths
- Parallel git worktrees remove the merge conflict problem that plagues multi-terminal agent workflows
- The living spec is a genuine coordination mechanism, not just a fancy prompt
- Context Engine's semantic dependency graph beats embedding-based context retrieval on large codebases
- Three human approval gates give you real oversight without requiring constant intervention
- BYOA support means you can use existing subscriptions and assess the orchestration model independently of Auggie
- SOC 2 Type II and ISO/IEC 42001 certified - enterprise compliance story is solid
Weaknesses
- macOS only. Windows is on a waitlist with no timeline; Linux has no roadmap mention. This structurally excludes roughly 75% of developer machines
- Still in public beta - early versions had streaming bugs, zombie processes, and application freezes. Most are fixed in v0.2.6, but the changelog is long
- Full VS Code integration only; JetBrains IDEs get completions but not the full workspace experience
- No signed commits support
- No FedRAMP certification (Windsurf has FedRAMP High, which matters for government and federal-adjacent work)
- Hardware-bound: local worktrees work well up to about 4-6 concurrent agents on 16GB RAM before performance degrades
- Independent third-party benchmarks don't exist yet - all performance data comes from Augment
Verdict
Intent is the most architecturally interesting agentic coding tool I've tested since Devin launched. The combination of living specs, git worktree isolation, and the Context Engine's semantic graph isn't just a refinement of existing approaches - it's a different model for how agent-assisted development should work at scale.
Whether it's the right tool for you depends almost entirely on two questions. Do you work on macOS? And do you work on codebases large enough that context management is a real bottleneck?
If both answers are yes, Intent is worth your time now. The beta roughness is real, but the core workflow holds up on serious engineering tasks. The BYOA path makes it low-risk to assess.
If you're on Windows or Linux, there's no version of Intent for you today. Keep watching the waitlist, but don't hold your breath - Augment has $472 million in funding and the incentive to fix this, but they've given no timeline.
Score: 7.8/10 - a category-defining architecture with a platform restriction that limits who can actually benefit from it.
Sources
- Intent: A workspace for agent orchestration - Augment Code blog
- Intent product page - Augment Code
- Augment Code pricing
- Auggie tops SWE-bench Pro - Augment Code blog
- Intent vs Claude Code - Augment Code
- Intent vs Devin - Augment Code
- Intent vs Windsurf - Augment Code
- Context Engine - Augment Code
- Intent 0.2.0 public beta changelog - Augment Code
- Moving beyond the IDE with Intent - augmentedswe.com
- Mac Coding Agent Apps Compared - Ry Walker
- Intent launch event - DEV Community

