Embedding Models Pricing - June 2026
Embedding API cost comparison: voyage-4-lite, OpenAI 3-small, Jina v3, and Amazon Titan V2 tie at $0.02/MTok. Gemini Embedding 2 now GA, Cohere Embed 4 dimensions corrected to 1,536 default.

TL;DR
- Four models now tie at the $0.02/MTok floor: voyage-4-lite, OpenAI text-embedding-3-small, Jina embeddings-v3, and Amazon Titan Text Embeddings V2
- Best value pick remains voyage-4-lite - same price as the others but with 32K context and a shared embedding space that lets you mix models per query type
- Correction: Cohere Embed 4 defaults to 1,536 dimensions, not 1,024 - update any storage estimates using the old number
- Google Gemini Embedding 2 went GA in April 2026, dropping the "-preview" suffix - pricing unchanged at $0.20/MTok for text
Quick Verdict
The $0.02/MTok floor now has four occupants. Jina embeddings-v3 joins OpenAI text-embedding-3-small, voyage-4-lite, and Amazon Titan Text Embeddings V2 at the same price point, giving budget-conscious teams one more option to benchmark before committing. For most RAG workloads, voyage-4-lite still has the edge at that tier - its 32K token context window and shared embedding space with voyage-4-large are concrete advantages over the 8K alternatives.
At the top of the commercial leaderboard, Google gemini-embedding-001 holds at $0.15/MTok with a 68.32 MTEB score, while the newly GA Gemini Embedding 2 at $0.20/MTok adds multimodal support (images, audio, video) for teams that need cross-modal search. Neither price changed at GA - the main update is that the model is now production-stable and out of preview.
Cross-links: the MTEB leaderboard from April 2026 has updated benchmark scores, and the RAG tools roundup covers the vector databases that store these vectors. New to embeddings? What are AI embeddings is worth reading first.
Normalized Pricing Table
All prices per million tokens (MTok). Embeddings are input-only - there are no output token costs. MTEB English scores from the latest available data; N/A means the model isn't listed on the public leaderboard. Sorted by price.
| Model | Provider | Price (/1M tokens) | Dimensions | Max Tokens | MTEB Score | Notes |
|---|---|---|---|---|---|---|
| voyage-4-lite | Voyage AI | $0.02 | 1,024 | 32,000 | ~65 | Batch: $0.013. 200M free |
| text-embedding-3-small | OpenAI | $0.02 | 1,536 | 8,191 | 62.26 | Batch: $0.01 |
| Amazon Titan Embed V2 | AWS Bedrock | $0.02 | 1,024 | 8,192 | N/A | Batch: $0.01. AWS ecosystem only |
| jina-embeddings-v3 | Jina AI | $0.02 | 1,024 | 8,192 | N/A | Commercial license. See note below |
| voyage-4 | Voyage AI | $0.06 | 1,024 | 32,000 | ~67 | Batch: $0.04. 200M free |
| Cohere Embed 3 English | Cohere | $0.10 | 1,024 | 512 | 64.5 | Short context only |
| Cohere Embed 3 Multilingual | Cohere | $0.10 | 1,024 | 512 | ~64 | 100+ languages |
| Mistral Embed | Mistral | $0.10 | 1,024 | 8,192 | ~63 | Batch: $0.05 |
| Cohere Embed 4 | Cohere | $0.12 | 1,536 | 128,000 | 65.20 | Multimodal, 128K context. Dimensions: 256/512/1024/1536 |
| voyage-4-large | Voyage AI | $0.12 | 1,024 | 32,000 | N/A | MoE flagship. 200M free |
| text-embedding-3-large | OpenAI | $0.13 | 3,072 | 8,191 | 64.60 | Batch: $0.065 |
| gemini-embedding-001 | $0.15 | 3,072 | 8,192 | 68.32 | Free tier, batch: $0.075 | |
| Codestral Embed | Mistral | $0.15 | 1,536 | 32,768 | N/A | Code-specialized, batch 50% off |
| voyage-code-3 | Voyage AI | $0.18 | 1,024 | 32,000 | N/A | Code retrieval. 200M free |
| voyage-context-3 | Voyage AI | $0.18 | 1,024 | 32,000 | N/A | Long-context specialist. 200M free |
| gemini-embedding-2 | $0.20 | 3,072 | 8,192 | N/A | Now GA. Multimodal: text/image/audio/video | |
| Jina Embeddings v4 | Jina AI | Free (non-comm) | 4,096 | 32,768 | ~71.7 | Qwen Research License only. Use v3 commercially |
Jina v3 vs v4: Jina AI recommends
jina-embeddings-v3for commercial production workloads at $0.02/MTok. The v4 model is built on Qwen2.5-VL, which carries a research-only license - Jina can't commercialize it, so the API is rate-limited to 100 RPM and intentionally throttled. Don't build a production indexing pipeline on v4.
Cohere Embed 4 dimensions correction: Previous versions of this page listed Cohere Embed 4 at 1,024 dimensions. The correct default is 1,536. The model supports configurable dimensions - 256, 512, 1,024, or 1,536 - via the
output_dimensionparameter. If you used the 1,024 figure to estimate vector storage, your actual storage at default settings is 50% larger.
Open-Source Alternatives (Self-Hosted)
Free to download, you pay only for compute.
| Model | Parameters | Dimensions | MTEB Score | Notes |
|---|---|---|---|---|
| Microsoft Harrier-OSS-v1 | 27B | N/A | 74.3 (MTEB v2) | MIT license, 32K context |
| NV-Embed-v2 | 7B | 4,096 | 72.31 (MTEB v1) | NVIDIA, tops English MTEB v1 |
| Qwen3-Embedding-8B | 8B | 2,048 | 70.58 (MTEB v1) | Apache 2.0, strong multilingual |
| Jina Embeddings v4 | 3.8B | 4,096 | ~71.7 | Research license; deploy locally for production |
| BGE-M3 | 568M | 1,024 | 63.0 | Lightweight, multilingual |
A note on benchmark versions: Harrier-OSS-v1 reports against MTEB v2, while NV-Embed-v2 and Qwen3-Embedding are measured on MTEB v1. The two benchmarks use different task compositions, so scores across versions aren't directly comparable. Harrier's 74.3 on MTEB v2 is impressive but you can't stack-rank it against NV-Embed-v2's 72.31 on v1 as if they're the same test.
At typical throughput on a single A100, self-hosted NV-Embed-v2 runs around $0.001 per million tokens - roughly 20x cheaper than any commercial API. The tradeoff is everything that comes with running inference infrastructure. If your team already has GPUs, the math is easy. If not, managed API cost is usually worth avoiding the ops burden.
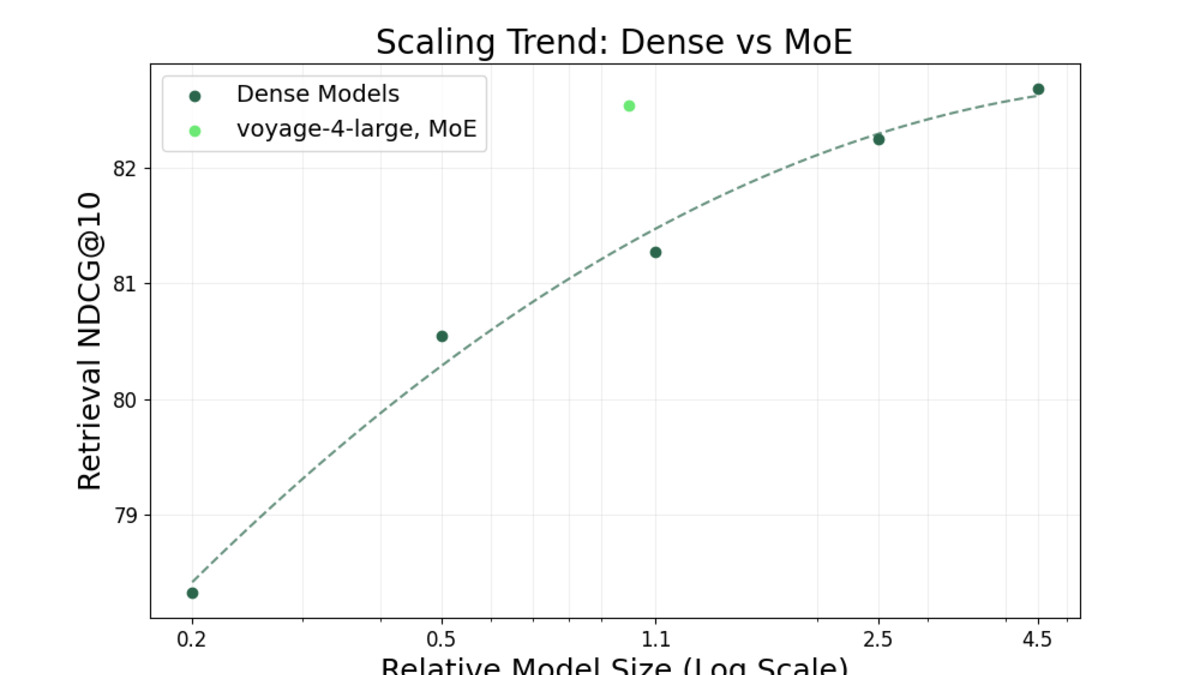 Voyage AI's internal RTEB benchmark shows voyage-4-large's retrieval lead over comparable models. Vendor-reported data - third-party MTEB submissions pending.
Source: blog.voyageai.com
Voyage AI's internal RTEB benchmark shows voyage-4-large's retrieval lead over comparable models. Vendor-reported data - third-party MTEB submissions pending.
Source: blog.voyageai.com
The Voyage 4 Shift
Voyage AI's January 2026 release of the Voyage 4 family is still the most consequential pricing-architecture change this space has seen. All four models - voyage-4-large, voyage-4, voyage-4-lite, and voyage-4-nano (open-weight, Apache 2.0) - share a single embedding space.
In most RAG systems, documents get embedded once and queries run thousands of times per day. With the Voyage 4 shared space, you can use voyage-4-large ($0.12/MTok) for the offline batch document indexing pass and voyage-4-lite ($0.02/MTok) for every live query - getting flagship-quality document representations at budget query costs. Voyage AI claims the asymmetric setup narrows the retrieval gap between the large and lite tiers.
Voyage 4 uses a mixture-of-experts architecture - the first production embedding model to do so. Voyage AI says serving costs are 40% lower than comparable dense models at the same quality tier.
The pricing tiers are unchanged from voyage-3.5: $0.02, $0.06, and $0.12/MTok from lite to large. What improved is quality at every tier. On Voyage AI's internal RTEB retrieval benchmark (29 datasets), voyage-4-large outperforms Gemini Embedding 001 by 8.2% and Cohere Embed 4 by 3.9%. Third-party MTEB submissions for voyage-4-large haven't appeared yet, so those figures remain vendor-reported.
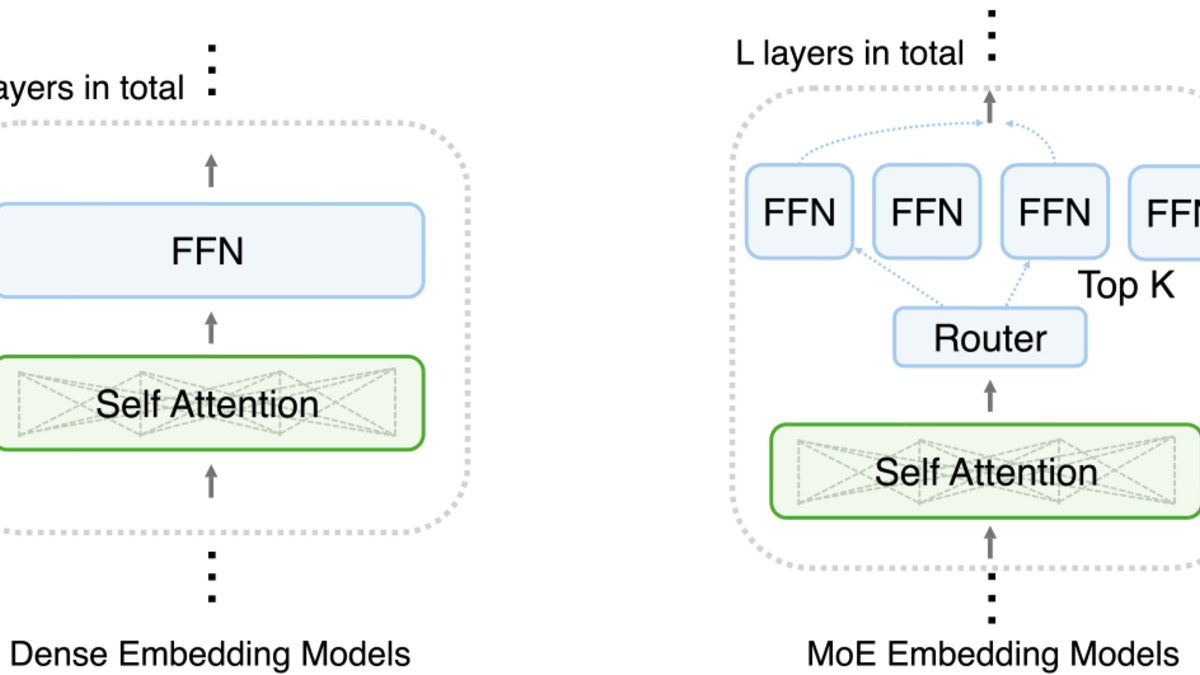 Voyage AI's MoE architecture routes tokens through specialized expert FFN layers rather than a single dense network, cutting inference cost without degrading retrieval accuracy.
Source: blog.voyageai.com
Voyage AI's MoE architecture routes tokens through specialized expert FFN layers rather than a single dense network, cutting inference cost without degrading retrieval accuracy.
Source: blog.voyageai.com
Hidden Costs
Context Limits Still Matter at the Low End
Cohere Embed 3 English and Multilingual cap at 512 tokens per chunk - roughly 380 words. At anything resembling a full paragraph, you're chunking aggressively and multiplying your API call count. Cohere Embed 4 jumps to 128K tokens, which changes the architecture: one call per document instead of 10-50. If you're assessing Cohere, skip v3 and go straight to v4 for anything beyond very short text.
OpenAI's 8,191-token limit covers most use cases. Voyage 4's 32K limit helps when dealing with long legal or technical documents where chunking degrades retrieval quality.
Dimension Count and Storage Costs
Cohere Embed 4 at its default 1,536 dimensions takes 50% more storage than the 1,024 you may have planned for. A 3,072-dimension embedding (OpenAI large, Google Gemini) takes 3x the vector storage of a 1,024-dimension model. At 100 million documents in Pinecone or Qdrant, that's roughly 1.2 TB versus 400 GB. At scale, storage costs can exceed the embedding API cost difference between tiers.
Cohere Embed 4 does offer configurable output dimensions - you can request 256, 512, 1,024, or 1,536 - so you can trade off storage against retrieval quality at the API level without re-embedding.
Batch Discounts Vary Widely
OpenAI gives 50% off through the Batch API ($0.01/MTok for text-embedding-3-small). Voyage AI gives 33% off via their Files API. Amazon Titan Text Embeddings V2 offers 50% batch discount ($0.01/MTok). Mistral gives 50% off on both Mistral Embed ($0.05/MTok batch) and Codestral Embed. Google's batch pricing for gemini-embedding-001 cuts cost to $0.075/MTok, and gemini-embedding-2 batch runs at $0.10/MTok. Cohere doesn't offer batch embedding discounts on its token-priced tier.
For any offline indexing pipeline, batch pricing is worth modeling before you commit to a provider. The difference compounds quickly at scale.
Re-embedding Costs
When you switch embedding models, you re-embed your entire corpus. At 1 billion tokens, that's $20 with text-embedding-3-small or $120 with Cohere Embed 4. The shared embedding space in Voyage 4 reduces this risk - you can migrate between voyage-4 tiers without re-embedding documents. Cross-provider migration still requires a full re-index.
AWS Ecosystem Lock-In
Amazon Titan Text Embeddings V2 at $0.02/MTok is competitive on price, but the model is only available through AWS Bedrock. It doesn't benchmark publicly on MTEB, and latency depends on your AWS region. If your inference stack already lives in AWS, worth testing. Otherwise, a provider with broader ecosystem support makes more sense.
Free Tier Comparison
| Provider | Free Offering | Tokens Included | Expiration |
|---|---|---|---|
| Voyage AI | Free credits | 200M tokens (all voyage-4 models) | None |
| Google (Gemini) | Free tier for both embedding models | 1,500 RPD | None |
| Jina AI (v4) | Non-commercial API | Rate-limited (100 RPM) | None |
| Jina AI (v3) | Paid API | $0.02/MTok, no free tier | N/A |
| OpenAI | $5 trial credits | ~250M tokens (3-small) | 3 months |
| Mistral | Free tier (rate-limited) | Limited RPM | None |
| Cohere | Trial API key | 1,000 calls/month | None |
| AWS Bedrock | 1M free tokens (12 months) | 1M tokens | 12 months |
Voyage AI's 200M token free tier is the most useful for prototyping. You can index a meaningful corpus before any billing starts. Google's free tier for gemini-embedding-001 is also generous for development, though rate-limited to 1,500 requests per day.
Price History
Apr 2026 - Google Gemini Embedding 2 went generally available, dropping the "-preview" suffix. The model ID is now
gemini-embedding-2. Pricing unchanged at $0.20/MTok for text, $0.45/MTok for images, $6.50/MTok for audio, $12.00/MTok for video.Mar 2026 - Google released Gemini Embedding 2 in preview, adding multimodal support across text, image, audio, and video. Gemini Embedding 001 remains the text-only option at $0.15/MTok.
Jan 2026 - Voyage AI released the Voyage 4 family. Shared embedding space enables asymmetric retrieval (large for docs, lite for queries). Pricing unchanged from voyage-3.5 tiers.
Jan 2026 - Cohere Embed 4 context window confirmed at 128K tokens. Default output dimensions set to 1,536 with configurable lower options.
Jan 2026 - Jina Embeddings v4 released under Qwen Research License - free via API for non-commercial use, throttled by design. Jina v3 remains the commercial API option at $0.02/MTok.
May 2025 - Mistral launched Codestral Embed at $0.15/MTok, specialized for code retrieval tasks with 32K context window.
Embedding prices have stayed remarkably stable compared to LLM API prices, where cuts of 50-80% over 18 months have been common. The main competition is on capability - multimodal support, longer context windows, shared embedding spaces - rather than cost reduction. Open-source models are where the real pressure is building, with Microsoft Harrier-OSS-v1 and Qwen3-Embedding-8B both surpassing commercial APIs on benchmark tasks at zero marginal cost.
FAQ
Which embedding model is cheapest per million tokens?
Four models tie at $0.02/MTok: voyage-4-lite, OpenAI text-embedding-3-small, Jina embeddings-v3, and Amazon Titan Text Embeddings V2. voyage-4-lite has the best additional specs at that price (32K context vs 8K for the others).
What's the best embedding model for RAG in 2026?
For most RAG pipelines, voyage-4-lite ($0.02/MTok) or OpenAI text-embedding-3-small ($0.02/MTok) cover 80% of use cases. For highest retrieval accuracy in a commercial API, Google gemini-embedding-001 ($0.15/MTok) leads the commercial MTEB at 68.32.
Are open-source embedding models good enough?
Yes. NV-Embed-v2 scores 72.31 on English MTEB v1, higher than every commercial API. Microsoft Harrier-OSS-v1 reaches 74.3 on MTEB v2. The catch is GPU infrastructure. For teams with existing compute, open-source wins on quality and cost.
How much does it cost to embed 1 million documents?
Assuming 500 tokens per document (about 375 words): 500M total tokens. At $0.02/MTok (OpenAI small, voyage-4-lite, or Jina v3), that's $10. At $0.15/MTok (Gemini Embedding 001), that's $75. Self-hosted NV-Embed-v2 comes in around $0.50 in compute.
Can I mix voyage-4-large for documents and voyage-4-lite for queries?
Yes. The Voyage 4 family uses a shared embedding space, so vectors from different tiers are compatible. You embed documents once with the large model and run queries through the cheaper lite model. Voyage AI reports this narrows the retrieval gap between the two tiers.
Why is Cohere Embed 4 listed at 1,536 dimensions now instead of 1,024?
The earlier figure was wrong. Cohere Embed 4 defaults to 1,536 dimensions. It supports 256, 512, 1,024, or 1,536 via the output_dimension API parameter, so you can reduce storage at the cost of some retrieval quality. The 1,024 figure appeared in some early documentation and was incorrect.
Sources:
- Voyage AI Pricing Documentation
- Voyage 4 Launch Blog Post
- OpenAI API Pricing
- Cohere Pricing Page
- Cohere Embed 4 Announcement
- Google Gemini API Pricing
- Gemini Embedding 2 GA Announcement
- Mistral AI Pricing
- Codestral Embed on OpenRouter
- Amazon Bedrock Pricing
- Amazon Titan Text Embeddings V2 Documentation
- Jina Embeddings API
- Microsoft Harrier-OSS-v1 Announcement
✓ Last verified June 29, 2026
