ZAYA1-8B: Open Reasoning Model Rivals Claude on AMD GPUs
Zyphra's ZAYA1-8B matches Claude 4.5 Sonnet on HMMT 2025 math benchmarks at just 760M active parameters, trained entirely on AMD Instinct MI300X GPUs under Apache 2.0.

Zyphra released ZAYA1-8B on May 6 - an 8.4 billion parameter mixture-of-experts model that keeps only 760 million parameters active at inference time. On the HMMT 2025 math competition, it scores 89.6, edging past Claude 4.5 Sonnet at 88.3. It's Apache 2.0, the weights are on Hugging Face, and the entire training stack ran on AMD Instinct MI300X GPUs.
For a model that costs less compute than a typical 1B dense network to run, those numbers are hard to ignore.
Key Specs
| Spec | Value |
|---|---|
| Total parameters | 8.4B |
| Active at inference | 760M |
| Architecture | MoE++ (Compressed Convolutional Attention) |
| Training hardware | 1,024 AMD Instinct MI300X nodes |
| License | Apache 2.0 |
| AIME 2026 (base) | 89.1 |
| HMMT 2025 (with RSA) | 89.6 |
| Model weights | Hugging Face |
The MoE++ Architecture
Zyphra built three custom components into this model. Together they're what the company calls MoE++ - not just a standard MoE on top of a transformer backbone.
Compressed Convolutional Attention
Standard multi-head attention scales quadratically with sequence length and burns memory on the KV cache. Zyphra's Compressed Convolutional Attention (CCA) operates in a compressed latent space instead of the full embedding dimension, hitting 8x KV-cache reduction versus standard attention. That's the reason a 760M active-param model can fit and run efficiently on consumer-grade hardware.
Expert Routing with PID-Controller Balancing
The MoE router uses MLP-based projections rather than the typical linear layers, and a PID controller maintains balanced expert use during training. Expert collapse - where a few experts absorb all the traffic while the rest become useless - is a recurring problem in sparse models. The PID approach keeps load distribution stable through training without manual intervention.
Markovian RSA - Bounded Test-Time Compute
The third component is the most interesting for inference scaling. Markovian Recursive Self-Aggregation (RSA) lets the model produce multiple parallel reasoning traces, then collapses them through iterative aggregation. The "Markovian" part is the key constraint: each aggregation step only sees the last 4,096 tokens from each trace, not the full built up history. Context window stays fixed regardless of how much total compute you throw at a problem.
That's what produces the headline score. At 5.5 million tokens per problem on APEX-shortlist, the model clears benchmarks where context window alone would normally disqualify it.
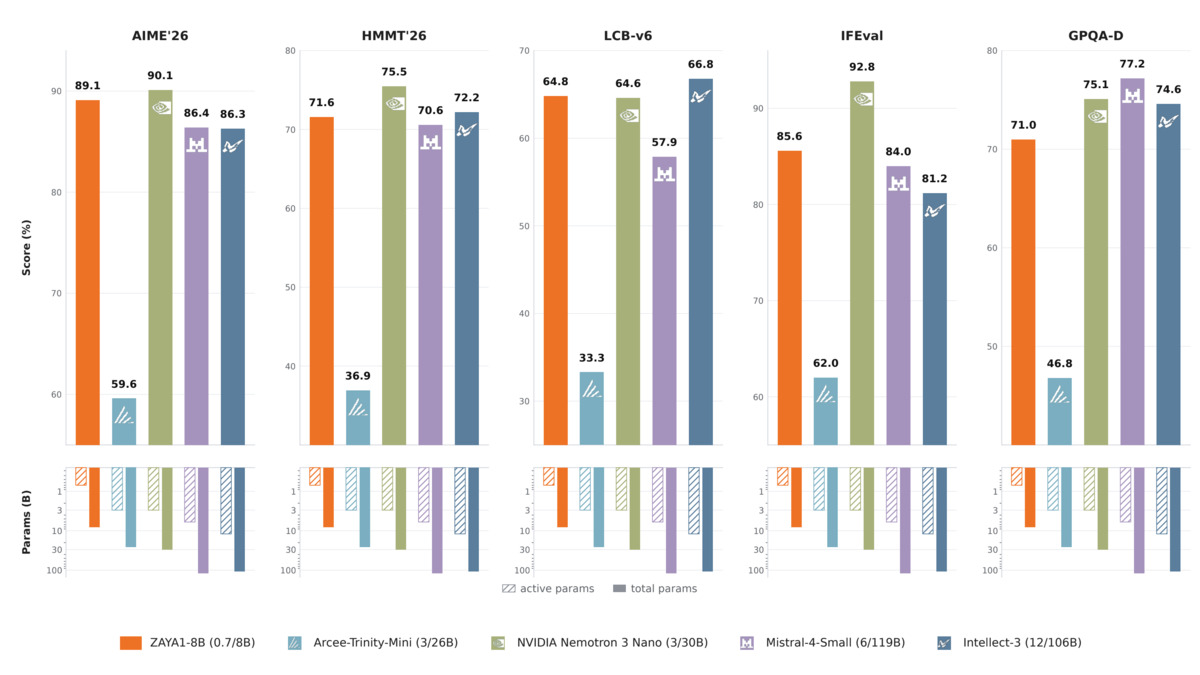 ZAYA1-8B at 760M active parameters vs. models with 3B-12B active parameters on AIME 2026, HMMT, and LiveCodeBench.
Source: huggingface.co
ZAYA1-8B at 760M active parameters vs. models with 3B-12B active parameters on AIME 2026, HMMT, and LiveCodeBench.
Source: huggingface.co
Benchmark Results
The base model numbers are competitive within the sub-1B active-parameter class. Against Qwen3-4B (77.5) and Qwen3.5-4B (84.5) on AIME 2026, ZAYA1-8B scores 89.1.
The more interesting comparison is against models with more total compute. ZAYA1-8B at 0.7B active parameters beats Mistral-Small-4-119B (6B active, 86.4) and Intellect-3 (12B active, 86.3) on AIME 2026. On LiveCodeBench v6, it scores 65.8 - above Mistral-Small-4's 57.9.
| Model | Active Params | AIME 2026 | HMMT 2026 | LiveCodeBench v6 |
|---|---|---|---|---|
| ZAYA1-8B | 0.7B | 89.1 | 71.6 | 65.8 |
| Qwen3-4B | 4B | 77.5 | 60.8 | 54.2 |
| Qwen3.5-4B | 4B | 84.5 | 63.6 | - |
| Mistral-Small-4-119B | 6B | 86.4 | 70.6 | 57.9 |
| Intellect-3 | 12B | 86.3 | 72.2 | 66.8 |
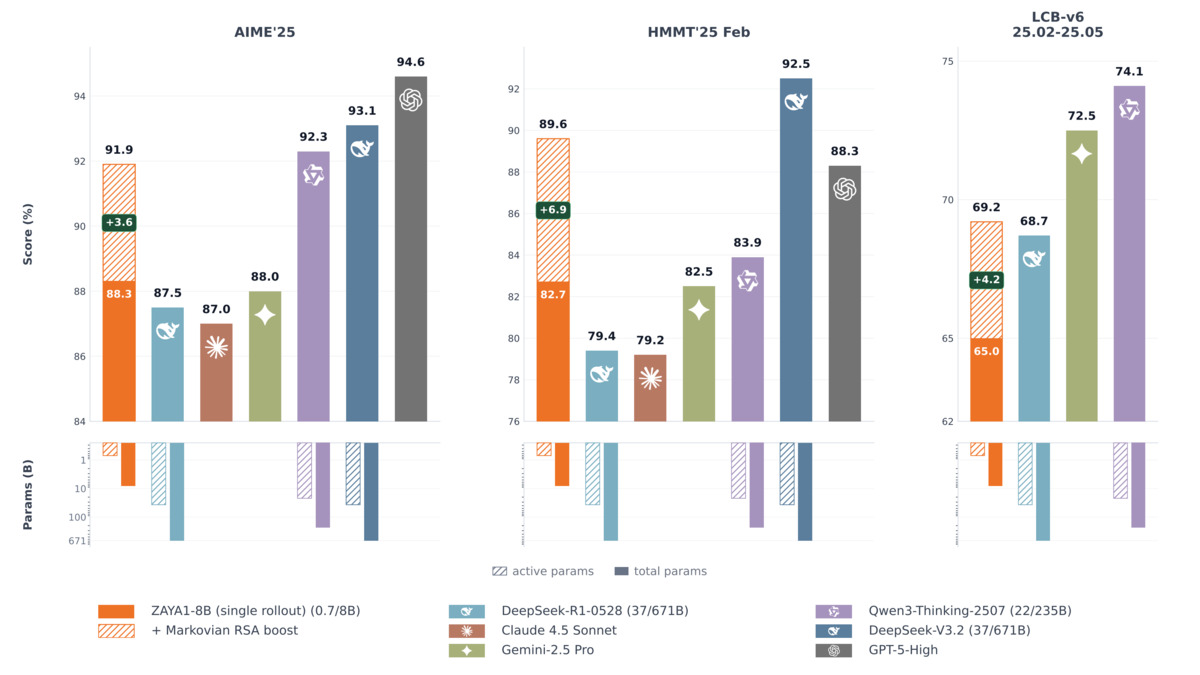
With Markovian RSA enabled, AIME 2025 climbs to 91.9% and HMMT 2025 reaches 89.6, which tops Claude 4.5 Sonnet (88.3) on that benchmark. The catch: at maximum TTC configuration that costs 5.5 million tokens per problem. It's not free compute. Read our reasoning benchmarks leaderboard for context on what these exams actually test.
There are real weak spots. On IFEval (instruction following), ZAYA1-8B scores 85.58 while Qwen3.5-4B hits 89.8. On agentic tasks - BFCL-v4 and tau-squared - Qwen3-4B and Qwen3.5-4B both lead by 10+ points. The model is optimized for math and code reasoning; it's not the best choice for tool-calling workflows.
 Markovian RSA test-time compute scaling - performance keeps climbing with additional token budget.
Source: huggingface.co
Markovian RSA test-time compute scaling - performance keeps climbing with additional token budget.
Source: huggingface.co
The AMD Training Run
This isn't a demo built on rented NVIDIA capacity. All three training stages - pretrain, midtrain, and supervised fine-tune - ran on a 1,024-node AMD Instinct MI300X cluster interconnected with AMD Pensando Pollara, with IBM providing the custom infrastructure.
That matters beyond the marketing story. Zyphra published the architecture details and training procedure in arXiv paper 2605.05365. Other teams can reproduce this on AMD hardware, which is increasingly available at lower cost than equivalent NVIDIA configurations. The fact that CCA reaches 8x KV compression while training stably on MI300X suggests the architecture is more broadly portable than most custom attention variants.
For context on why companies like this are betting on non-NVIDIA chips, our coverage of NVIDIA's $2.1B IREN deal covers the supply dynamics driving the search for alternatives.
 The AMD Instinct MI300X - the hardware Zyphra used for the entire ZAYA1-8B training run.
Source: twave.zone
The AMD Instinct MI300X - the hardware Zyphra used for the entire ZAYA1-8B training run.
Source: twave.zone
Getting It Running
ZAYA1-8B doesn't run on stock Hugging Face inference. It requires Zyphra's fork of both vLLM (github.com/Zyphra/vllm@zaya1-pr) and Transformers (github.com/Zyphra/transformers@zaya1). Six quantized variants are on Hugging Face for lower-VRAM setups. Free serverless access is available at cloud.zyphra.com.
If you want an Apache 2.0 reasoning model that doesn't need forked tooling, the picture is different - but Zyphra says standard framework support is coming. The pretraining base model is also available separately at Zyphra/ZAYA1-reasoning-base for teams that want to fine-tune from scratch.
For background on how this model fits into the broader small language model category, the reasoning model guide covers the tradeoffs.
What To Watch
Three things worth following as this release develops.
Reproducibility. Zyphra published the arXiv paper and the weights. Whether independent teams can copy the benchmark scores - especially the HMMT 2025 results with RSA - is the real test. Vendor-run evals and third-party evals rarely match exactly.
Framework integration. The custom vLLM and Transformers forks are a friction point. Until CCA lands in mainline vLLM, deployment is messier than for standard architectures. Watch the upstream PRs.
The agentic gap. ZAYA1-8B is genuinely strong on math and competitive on code. It falls behind peers on function-calling and multi-step agentic tasks. Whether the team addresses that in a follow-up or leaves it as a known tradeoff will determine where the model fits in production stacks. Full model details are in the ZAYA1-8B model card.
Sources:
