xAI Opens Grok 4.3 API: 83% Price Cut, Video Input
xAI opened Grok 4.3 to all API developers on May 6 with an 83% output price cut, 1M-token context, native video input, and document generation - plus five legacy models retiring May 15.

xAI opened its Grok 4.3 model to all API developers on May 6, weeks after a quiet beta launch restricted to SuperGrok Heavy subscribers paying $300 per month. The headline number: output tokens dropped from $15.00 to $2.50 per million - an 83% reduction. Input tokens fell from $3.00 to $1.25, down 58%. For teams running agentic pipelines that chew through output at scale, this changes the unit economics considerably.
Key Specs
| Specification | Value |
|---|---|
| Input Price | $1.25 / 1M tokens |
| Output Price | $2.50 / 1M tokens |
| Cache Hit Price | $0.20 / 1M tokens |
| Context Window | 1,000,000 tokens |
| Video Input | Up to 5 min (mp4, mov, webm) |
| Document Output | PDF, XLSX, PPTX |
| Knowledge Cutoff | November 2024 |
| Release Date (API) | May 6, 2026 |
The model itself has been live since April 17 in beta - xAI shipped it without a press release directly into the grok.com model selector. What changed on May 6 is access: the model is now available in the xAI API for any developer, with public pricing posted for the first time. The beta was functionally a closed preview locked behind the Heavy subscriber tier, which meant no independent benchmarking and no API integrations.
What Shipped
Video and Document Output
Grok 4.3 accepts video natively. The limits are practical rather than generous: clips up to five minutes, maximum 1080p, in mp4, mov, or webm. xAI samples frames at 1 to 4 frames per second automatically and bills on the resulting image tokens rather than video duration. For moderation pipelines, video QA, or content summarization, this removes a preprocessing step. Whether the quality holds up against purpose-built video models isn't yet independently verified.
Document generation is the other addition: the model produces downloadable PDFs, spreadsheets, and PowerPoint files directly from a conversation. xAI calls the output "fully populated in real-time" - meaning file assembly happens during generation rather than as a separate rendering pass. For teams creating formatted reports programmatically, that is one fewer service in the pipeline.
Voice APIs and Image Agent Mode
xAI launched speech-to-text and text-to-speech APIs with the model, both priced at $4.20 per million characters. That sits roughly 86 to 92% below OpenAI's equivalent voice endpoints. xAI has not published independent quality benchmarks for the voice stack yet, so the comparison is on price alone.
There is also a new image agent mode, which xAI describes as allowing the model to plan and execute multi-step image generation and editing tasks without manual prompting of each step. Details on the underlying image model and resolution limits are not yet in the public documentation.
 xAI's API page updated to feature Grok 4.3 as the recommended model for enterprise and developer use.
Source: x.ai
xAI's API page updated to feature Grok 4.3 as the recommended model for enterprise and developer use.
Source: x.ai
Pricing in Context
The output price cut is the operationally significant number. At $2.50 per million output tokens, Grok 4.3 undercuts most frontier-class models on output cost. The blended rate assuming a 3:1 input-to-output token ratio lands at about $1.56 per million - competitive for agentic workloads where the model creates long responses.
| Model | Input $/1M | Output $/1M | Context |
|---|---|---|---|
| Grok 4.3 | $1.25 | $2.50 | 1M tokens |
| GPT-5.5 Instant | $0.75 | $3.00 | 256K tokens |
| Claude Opus 4.7 | $15.00 | $75.00 | 200K tokens |
| Gemini 3.1 Flash-Lite | $0.25 | $1.50 | 1M tokens |
The most relevant competitive comparison for day-to-day agentic use is GPT-5.5 Instant and Gemini 3.1 Flash-Lite. Gemini Flash-Lite wins on raw cost but trades off on reasoning depth. Grok 4.3's 1M context at this price is notable - that combination hasn't previously been available from Western providers at this tier. A Batch API is available with 20 to 50% discounts for non-image, non-video tasks.
One pricing wrinkle worth flagging: server-side tools (web search, X/Twitter search, code execution) are billed separately at $5 per 1,000 calls. For pipelines that rely heavily on live search, that adds up and needs to be modeled separately from token costs.
Benchmarks
Where It Leads
xAI's strongest verified number is the GDPval-AA agentic benchmark, where Grok 4.3 scored an ELO of 1,500 - up 321 points from Grok 4.20 at 1,179. That gain puts it above Gemini 3.1 Pro Preview and Meta's Muse Spark on the same evaluation. Grok 4.3 also holds the top position on CaseLaw v2 and CorpFin, which are legal research and corporate finance benchmarks. For domain-specific workflows in those verticals, the model appears meaningfully ahead of the current field.
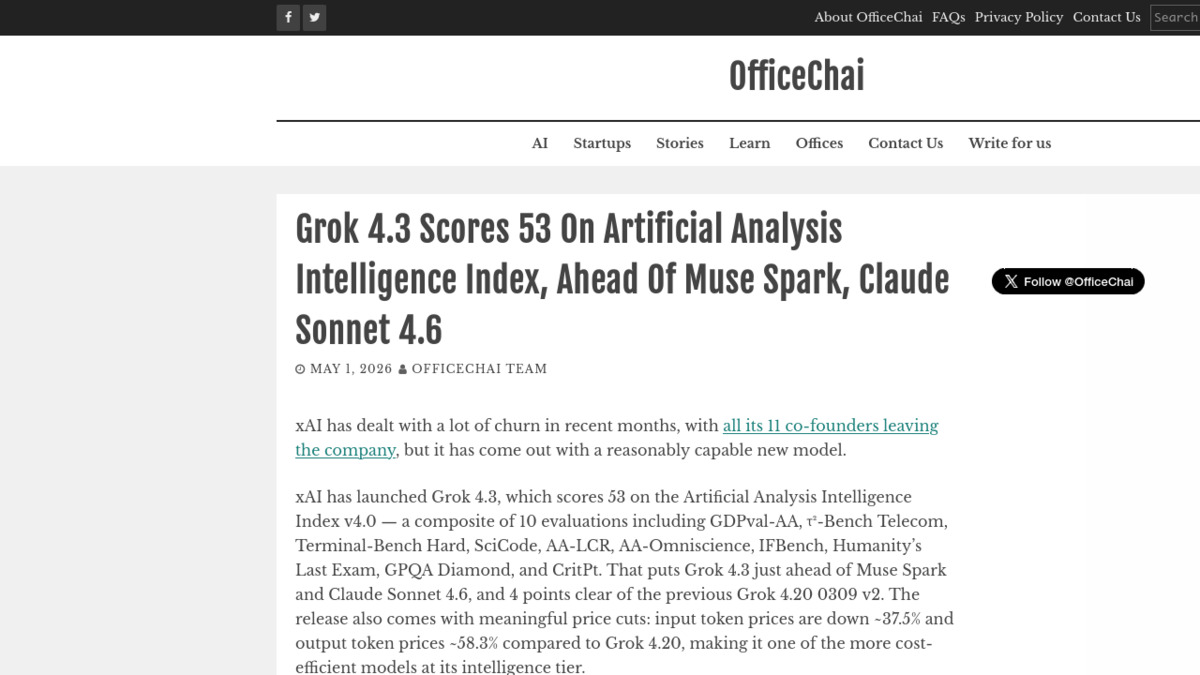 Grok 4.3 scores 53 on the Artificial Analysis Intelligence Index, placing it just ahead of Muse Spark and Claude Sonnet 4.6.
Source: officechai.com
Grok 4.3 scores 53 on the Artificial Analysis Intelligence Index, placing it just ahead of Muse Spark and Claude Sonnet 4.6.
Source: officechai.com
Where It Lags
Artificial Analysis's independent evaluation places the overall intelligence index score at 53, behind Claude Opus 4.7 (56) and GPT-5 (55). The more pointed gap is on SWE-bench Verified: Grok 4.3 at roughly 73% compared to Opus 4.7's 87.6% and GPT-5's 82.1%. If your use case is software engineering agents or code generation at scale, that 14-point gap isn't small.
The model is also notably verbose. Artificial Analysis recorded 88 million output tokens during its intelligence index evaluation - well above the median of 36 million for comparable models. Verbose outputs inflate effective cost beyond the headline per-token rates. Teams running high-volume inference should benchmark output length on their own workloads before assuming the $2.50 rate is representative.
Speed is another area where xAI's claims and independent measurements diverge. xAI has described Grok 4.3 as the "fastest reasoning model" at 207 tokens per second. Artificial Analysis measured 71.1 tokens per second at the time of evaluation - a significant gap that likely reflects different measurement methodologies or infrastructure conditions. Time to first token is 13.70 seconds, consistent with extended reasoning model behavior, and notably higher than the median of 2.77 seconds for non-reasoning models.
Migration: Five Models Die May 15
With Grok 4.3 in general availability, xAI is retiring five legacy models on May 15, 2026 at 12:00 PM Pacific:
grok-4-1-fastgrok-4-fastgrok-4grok-code-fast-1grok-imagine-image-pro
Any integration calling those model IDs hard-coded will fail after that deadline. xAI has published a migration guide in its documentation. Teams running grok-4 or grok-4-fast for cost reasons when the faster variants were the budget option should re-evaluate: at $1.25/$2.50, the main model is now priced closer to what those fast variants were previously charging.
What To Watch
The 1M context window in the API is narrower than the 2M token context available to SuperGrok Heavy subscribers. Whether xAI expands API context to match the subscriber tier is not yet confirmed. The November 2024 knowledge cutoff is a constraint for time-sensitive reasoning tasks - live web search is available as a tool call, but it adds cost and latency.
The voice and image agent features are new and unaudited by independent evaluators. The pricing is aggressive, but quality comparisons with OpenAI's voice stack or with purpose-built image agents do not yet exist from third parties.
The legal and finance benchmark leadership is the most credible signal in the launch. For teams building in those verticals who have been priced out of frontier models, Grok 4.3 is worth a serious evaluation run.
Sources:
