USCC: China's Open-Source AI Now Runs 80% of US Startups
A new USCC report finds Chinese open-source models now dominate US AI startup stacks, with Qwen surpassing Llama in global downloads and Chinese models taking 41% of all Hugging Face downloads.

Chinese open-source models now run in roughly four out of five US AI startups, according to a report released Monday by the US-China Economic and Security Review Commission (USCC) - the same body that advises Congress on trade and national security risks involving China.
Claims Examined
| Claim | Source | Verification Level |
|---|---|---|
| ~80% of US AI startups use Chinese open-source models | A16Z's Martin Casado, cited by USCC | VC pitch deck analysis; not a random sample |
| Chinese models = 41% of Hugging Face downloads | HF State of Open Source Spring 2026 | Platform-level data, Feb 2025-Feb 2026 |
| Qwen surpassed Llama in cumulative downloads | HuggingFace platform data | Crossover at ~385M vs 346M (Dec 2025) |
| China leads in embodied AI training data | USCC projection | Inferred from manufacturing scale; unverified |
The timing matters. This report lands four months after Congress extended Nvidia H200 export restrictions to additional countries, and just as the gap between open-source and proprietary model quality has effectively closed. The argument in Washington has been that chip controls limit China's AI capability. The USCC report is pushing back on that assumption hard.
What the USCC Is Claiming
The report's central argument is that China has built a "self-reinforcing competitive advantage" through open-source distribution. Cheap-to-run models drive global adoption. That adoption creates inference data. That data feeds back into model improvement. Repeat.
"Open model proliferation creates alternative pathways to AI leadership. Chinese labs have narrowed performance gaps with top Western large language models."
- USCC report, March 23, 2026
Michael Kuiken, the commission's vice chair, went further in public remarks, warning of a growing "deployment gap in the embodied AI space between the US and China" - a gap he said compounds over time as China's manufacturing dominance creates physical-world AI training data that no benchmark captures. The report names Alibaba (Qwen), Moonshot AI, MiniMax, and DeepSeek as the primary drivers. It also flags Siemens as continuing to adopt Chinese models despite security concerns, citing cost and customization advantages over Western alternatives.
 Michael Kuiken, USCC Vice Chair, who warned of a compounding deployment gap in embodied AI.
Source: uscc.gov
Michael Kuiken, USCC Vice Chair, who warned of a compounding deployment gap in embodied AI.
Source: uscc.gov
What They Measured
Download Velocity and Platform Share
The numbers here are from Hugging Face's own Spring 2026 State of Open Source report, published a week before the USCC paper. Chinese-origin models accounted for 41% of all Hugging Face downloads between February 2025 and February 2026. US-origin models came in at 36.5%.
Alibaba's Qwen crossed Meta's Llama in cumulative downloads around mid-December 2025 - around 385 million for Qwen versus 346 million for Llama. By January 2026, Qwen's total had climbed to 700 million. In a single month (December 2025), Qwen's downloads passed the combined total of the next eight most popular model families.
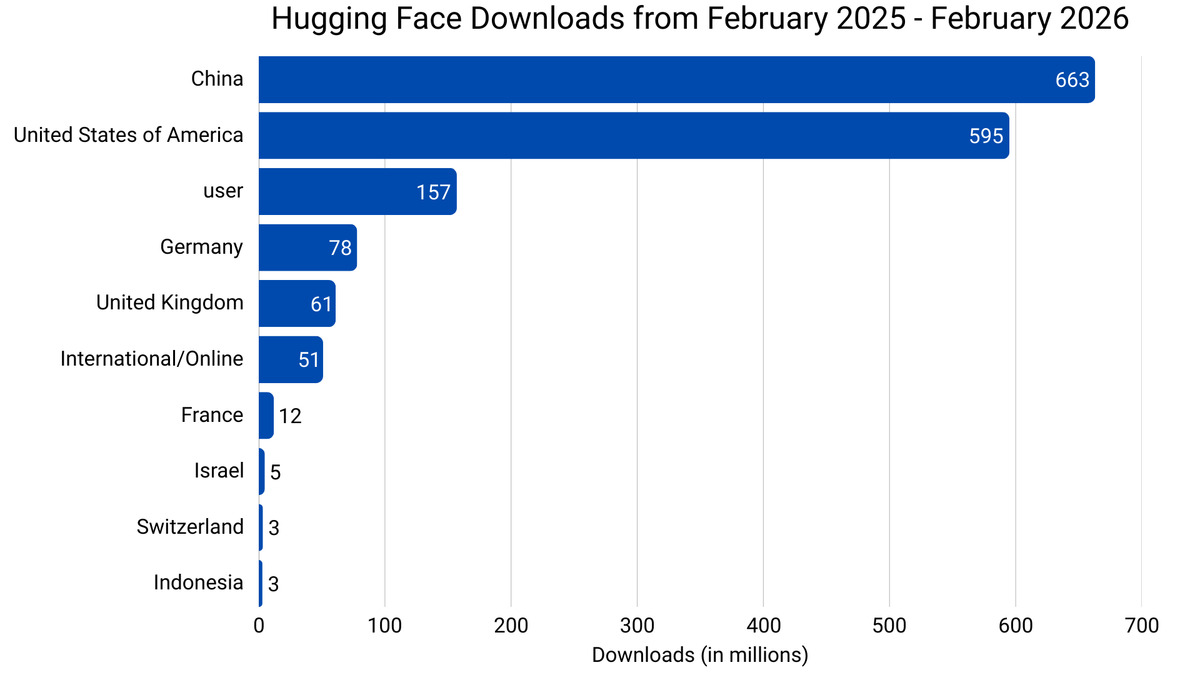 China's share of Hugging Face model downloads (41%) overtook the US (36.5%) in the trailing 12-month period ending February 2026.
Source: huggingface.co
China's share of Hugging Face model downloads (41%) overtook the US (36.5%) in the trailing 12-month period ending February 2026.
Source: huggingface.co
DeepSeek R1 also briefly overtook ChatGPT as the most-downloaded app on the US App Store after its initial release - a milestone that tells you more about novelty than sustained usage. The Qwen 3.5 series launch earlier this year put a finer point on the quality argument: at multiple size ranges, Qwen benchmarks match or beat Western equivalents running on clearly more compute.
The "Two Loops" Framework
The USCC's most meaningful analysis involves what it calls two compounding feedback loops. Loop 1 (digital): Open-source distribution drives global model adoption, which drives API usage and fine-tuning, which generates training signal, which improves the next model generation. Loop 2 (physical): China's dominance in manufacturing and robotics produces real-world interaction data for embodied AI systems - forklifts, assembly robots, autonomous logistics. Beijing has officially designated embodied AI as a core strategic industry, with multiple major robotics companies planning 2026 IPOs. Kuiken calls the intersection of these two loops the "most serious long-term challenge to US AI leadership."
What They Didn't Measure
The 80% figure for US startup adoption isn't an USCC measurement. It comes from Andreessen Horowitz general partner Martin Casado, who estimated that "among startups pitching with open-source stacks, there's about an 80% chance they're running on Chinese open models." That's a VC observing pitch decks, not a systematic industry survey. The USCC cites it as a data point, not a statistic.
Downloads also don't equal production deployments. Researchers download models to experiment. Developers pull weights to fine-tune on private data. A model clocking 700 million downloads is popular; it isn't necessarily running critical business logic at 700 million companies.
The embodied AI gap claim deserves similar scrutiny. The argument is structurally sound - manufacturing-scale robotics deployment does generate training data that pure cloud AI companies can't match. But the report doesn't quantify this gap, measure its growth rate, or compare it against US robotics investment trends. It's a strategic hypothesis, not a measured outcome.
 Qwen's benchmark performance relative to other frontier model families - the technical parity argument underlying the USCC's download statistics.
Source: alibabacloud.com
Qwen's benchmark performance relative to other frontier model families - the technical parity argument underlying the USCC's download statistics.
Source: alibabacloud.com
The methodology behind the Hugging Face download data is more solid, but downloads reflect availability and ease of access as much as deliberate choice. Chinese labs release models on Hugging Face aggressively. A model that's easy to download from a familiar platform will build up more downloads than one hosted elsewhere, regardless of quality differences.
Should You Care?
If you're building on open-source models, you almost certainly already have an opinion on Qwen. The download numbers are a lagging indicator of what engineers already know from running evals: Chinese open-source models punch above their compute budget in a way that wasn't true two years ago.
The policy implications are thornier. The USCC's argument cuts against the assumption that chip export controls are sufficient to maintain US AI leadership. If China can stay near the frontier by open-sourcing aggressively - producing community contributions, adoption data, and fine-tunes from global users - then compute constraints matter less than the chip hawks assumed.
What the report doesn't tell you is what to do about it. Open-source isn't inherently a security risk, and most of the Qwen and DeepSeek usage in US startups is for entirely mundane tasks: text classification, document summarization, code completion. The USCC doesn't distinguish between a startup using Qwen for invoice parsing and one embedding it in critical infrastructure.
The concrete question that the report raises but doesn't answer: should US AI security policy treat Chinese open-source models as a supply chain issue the way it treated Chinese networking hardware? That question is now on the table in a way it wasn't six months ago.
The full USCC report is available at uscc.gov.
Sources:
- China's open-source AI strategy creates self-reinforcing advantage - Taipei Times
- US panel credits China's AI edge to open-source models - South China Morning Post
- State of Open Source on Hugging Face: Spring 2026 - Hugging Face Blog
- Alibaba's Qwen leads global open-source AI community with 700M downloads - Xinhua
- Michael Kuiken, Vice Chair - USCC

