Transformers.js v4 Ships WebGPU Runtime for Browser ML
HuggingFace's Transformers.js v4 rewrites its WebGPU runtime in C++, supports 200+ architectures, and delivers up to 4x faster inference in browsers and server-side JS runtimes.

HuggingFace released Transformers.js v4 on February 9, 2026, after roughly a year of development. The headline changes: a WebGPU runtime rewritten from scratch in C++, support for over 200 model architectures, BERT embedding speedups of up to 4x, and a build system that went from 2 seconds to 200 milliseconds. The library runs the same code across browsers, Node.js, Bun, and Deno with hardware-accelerated inference.
TL;DR
- New WebGPU runtime rewritten in C++ with ONNX Runtime team delivers up to 4x faster BERT embeddings
- Over 200 architectures supported, including Mamba state-space models and Mixture of Experts
- Build system migrated from Webpack to esbuild - 10x faster builds, 53% smaller web bundle
- Standalone
@huggingface/tokenizerspackage extracted at 8.8kB gzipped with zero dependencies - Works across browsers, Node.js, Bun, and Deno with GPU acceleration
The WebGPU Rewrite
The biggest change in v4 is the WebGPU execution provider. The HuggingFace team collaborated directly with the ONNX Runtime team to rewrite the WebGPU runtime in C++, replacing the previous JavaScript-based WebGPU path. This isn't a thin wrapper - it's a from-scratch implementation that uses ONNX Runtime contrib operators like com.microsoft.GroupQueryAttention, com.microsoft.MatMulNBits, and com.microsoft.QMoE for hardware-accelerated attention and quantized matrix operations.
The practical result for BERT-based embedding models is a roughly 4x speedup over the v3 WebGPU path, thanks in part to a new com.microsoft.MultiHeadAttention operator. For larger models, the team demonstrated GPT-OSS 20B running at approximately 60 tokens per second on a M4 Pro Max using q4f16 quantization.
 The v4 WebGPU runtime sits between Transformers.js and the GPU, handling operator dispatch through ONNX Runtime's C++ backend.
Source: huggingface.co
The v4 WebGPU runtime sits between Transformers.js and the GPU, handling operator dispatch through ONNX Runtime's C++ backend.
Source: huggingface.co
Browser Compatibility
WebGPU support has reached a tipping point. Chrome and Edge ship it on Windows, macOS, and ChromeOS. Firefox 141 added Windows support, with Firefox 145 covering macOS on Apple Silicon. Safari 26.0 brought WebGPU to macOS Tahoe, iOS 26, iPadOS 26, and visionOS 26. Coverage sits at roughly 85-90% of global browser traffic, though mobile remains fragmented - Chrome on Android requires recent hardware, and Firefox on Android still keeps WebGPU behind a flag.
For browsers without WebGPU, Transformers.js falls back to WASM on CPU. The gap between the two paths is significant enough that developers should detect WebGPU availability and adjust their UX accordingly.
What's Inside the 200+ Architectures
The v4 release added several architecture families that weren't possible before. State-space models via Mamba, Multi-head Latent Attention, and Mixture of Experts all ship as first-class citizens. New named models include GPT-OSS, Chatterbox, GraniteMoeHybrid, LFM2-MoE, HunYuanDenseV1, Apertus, Olmo3, FalconH1, and Youtu-LLM.
Models passing 8B parameters are now supported, which was a hard ceiling in v3. Combined with quantization options (fp32, fp16, q8, q4), this means developers can run meaningfully large models client-side for the first time - assuming the user's GPU has enough VRAM.
| Feature | v3 | v4 |
|---|---|---|
| WebGPU runtime | JavaScript-based | C++ rewrite with ONNX Runtime |
| Architectures | ~100 | 200+ |
| Max model size | ~8B parameters | 20B+ demonstrated |
| Build tool | Webpack | esbuild |
| Build time | ~2 seconds | ~200ms |
| Web bundle size | Baseline | 53% smaller |
| Tokenizer | Bundled | Standalone 8.8kB package |
The Codebase Refactor
The internal restructuring is significant. The old models.js file passed 8,000 lines - a single file handling every architecture. In v4, model implementations split into focused modules with clear separation between utility functions, core logic, and model-specific code.
The repository converted to a PNPM monorepo with workspaces, enabling sub-packages that depend on the core library without maintaining separate repositories. Examples moved to a dedicated repo, and the team migrated code formatting to Prettier for automated style enforcement.
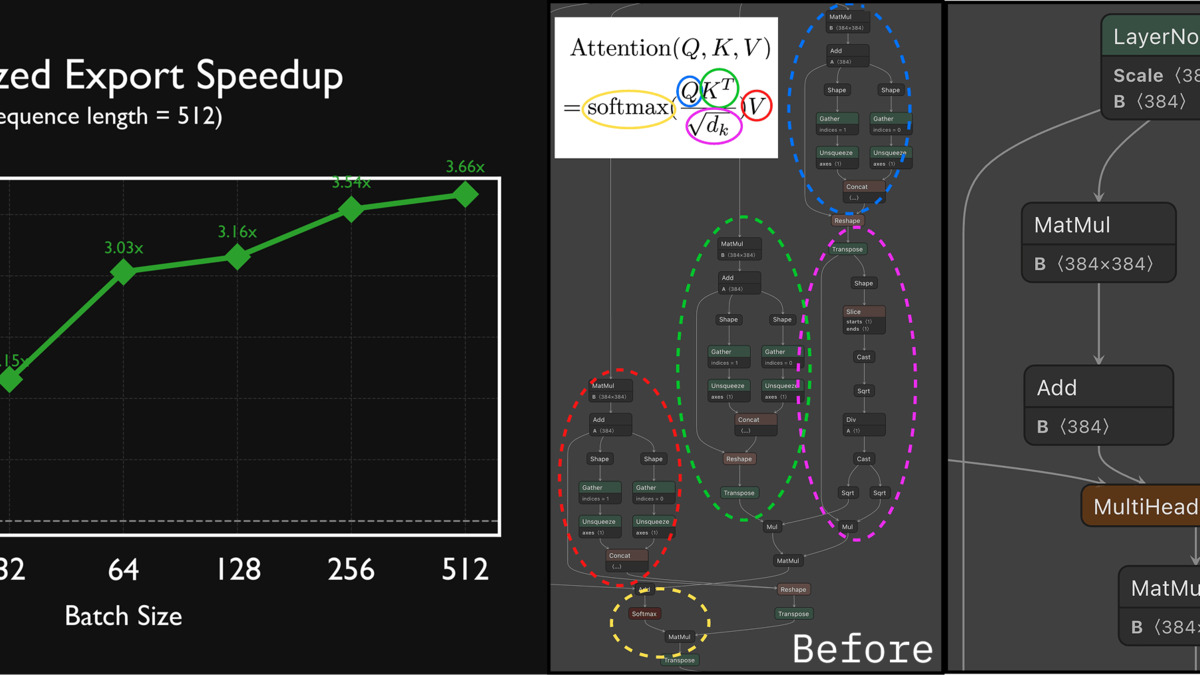 Optimized ONNX exports in v4 show consistent performance gains across model families.
Source: huggingface.co
Optimized ONNX exports in v4 show consistent performance gains across model families.
Source: huggingface.co
The ModelRegistry API
One addition that production developers will appreciate is ModelRegistry. It lets you inspect pipeline assets before downloading anything:
import { ModelRegistry, pipeline } from "@huggingface/transformers";
const modelId = "onnx-community/all-MiniLM-L6-v2-ONNX";
const files = await ModelRegistry.get_pipeline_files(
"feature-extraction", modelId, { dtype: "fp32" }
);
// Check total download size before committing
const metadata = await Promise.all(
files.map(file => ModelRegistry.get_file_metadata(modelId, file))
);
const downloadSize = metadata.reduce((t, item) => t + item.size, 0);
// Check if already cached
const cached = await ModelRegistry.is_pipeline_cached(
"feature-extraction", modelId, { dtype: "fp32" }
);
This solves a real pain point. In v3, calling pipeline() would start downloading model files right away with no way to check sizes or cache status upfront. For applications where users are on metered connections, that visibility matters.
Getting Started
Installation is straightforward:
npm i @huggingface/transformers
Or via CDN for quick prototyping:
<script type="module">
import { pipeline } from
'https://cdn.jsdelivr.net/npm/@huggingface/[email protected]';
</script>
A minimal sentiment analysis pipeline in five lines:
import { pipeline } from "@huggingface/transformers";
const classifier = await pipeline(
"sentiment-analysis"
);
const result = await classifier("Transformers.js v4 is fast.");
console.log(result);
// [{ label: 'POSITIVE', score: 0.9998 }]
The @huggingface/tokenizers package also ships independently at 8.8kB gzipped with zero dependencies - useful if you only need tokenization without the full inference stack.
Where It Falls Short
The v4 release is a preview, not a stable release. It published under the @next npm tag, meaning npm i @huggingface/transformers pulls v3 by default unless you specify @next. The team hasn't announced a timeline for the stable v4 release.
Mobile Is Still Rough
WebGPU on mobile browsers remains inconsistent. Chrome on Android needs recent hardware running Android 12+. Firefox on Android hasn't shipped WebGPU outside of a flag. Safari on iOS 26 works, but that requires the latest OS version. For apps targeting broad mobile audiences, WASM fallback is the realistic path - and running models locally on mobile remains constrained by thermal throttling and memory limits.
The ONNX Conversion Step
Every model needs ONNX conversion before it works with Transformers.js. HuggingFace's Optimum handles this, and the onnx-community org on the Hub hosts pre-converted models, but if you need a model that hasn't been converted yet, you're adding a step to your pipeline. This is the same limitation that has existed since v1 - it just matters more now that the runtime can handle larger models.
No Training
Unlike TensorFlow.js, Transformers.js is inference-only. You can't fine-tune a model in the browser. For the on-device use cases where personalization matters - adapting a model to a user's writing style, for example - you still need a server-side training step.
Transformers.js v4 is the most sizable update to browser-based ML tooling since WebGPU itself shipped. The C++ runtime rewrite, 200+ architecture support, and the ModelRegistry API collectively move the library from "neat demo" territory toward production viability. The open-source ecosystem for on-device inference keeps closing the gap with server-side APIs - and at zero per-request cost, the economics make it worth the integration effort for latency-sensitive, privacy-conscious applications.
Sources:
- Transformers.js v4 Preview: Now Available on NPM - HuggingFace Blog
- Transformers.js GitHub Repository
- Transformers.js V4 Pull Request #1382
- Transformers.js v4 Released: Run AI Models Locally in Browsers - AdwaitX
- Transformers.js v4: WebGPU-Powered AI Runs Locally - RoboAI Digest
- WebGPU Supported in Major Browsers - web.dev

