Tencent's 7B Voice AI Targets OpenAI's Realtime API
Tencent open-sources Covo-Audio, a 7B end-to-end audio language model with native full-duplex conversation that beats larger closed models on key benchmarks.

Tencent today open-sourced Covo-Audio, a 7B-parameter end-to-end audio language model with native full-duplex conversation. The timing is sharp: OpenAI's Realtime API remains proprietary and priced for enterprise workloads, and Covo-Audio is the most capable open-weight alternative anyone has put out so far.
TL;DR
- 7B model processes and creates native audio in a single architecture - no ASR/LLM/TTS pipeline required
- Full-duplex variant handles simultaneous speaking and listening, with 99.7% turn-taking success rate
- Beats Qwen2.5-Omni (71.50%) on MMAU audio benchmark with 75.30% average
- Weights and code on GitHub and HuggingFace, but under a custom Tencent license - not Apache or MIT
The key distinction from most voice AI systems is architectural. OpenAI's Realtime API, and most commercial voice products, work by chaining separate components: a speech recognition module transcribes audio to text, a language model generates a text response, then a text-to-speech engine converts it back. Errors compound at each step. Covo-Audio runs a single model on the raw audio stream from input to output.
Model Variants and Architecture
Tencent released three versions:
| Variant | Purpose | Full-Duplex |
|---|---|---|
| Covo-Audio | Foundation model | No |
| Covo-Audio-Chat | Dialogue-tuned | No |
| Covo-Audio-Chat-FD | Real-time conversation | Yes |
The architecture stacks Qwen2.5-7B as the language backbone, a Whisper-large-v3 audio encoder running at 50 Hz, and a WavLM-large speech tokenizer with a 16,384-entry codebook at 25 Hz. Audio output goes through BigVGAN at 24 kHz. The researchers call their integration approach "Hierarchical Tri-modal Speech-Text Interleaving," which combines continuous acoustic features, discrete speech tokens, and text in a unified sequence at both phrase and sentence level.
Intelligence-Speaker Decoupling
One interesting design choice: the model separates voice identity from conversational capability. You can swap in a target speaker's voice characteristics without retraining the underlying language model. Whether this works well in practice - especially for accented or lower-resource voices - isn't addressed in the materials Tencent published.
Why Full-Duplex Is Hard
Most voice AI forces turn-based interaction. You speak, the model waits, then it responds. Full-duplex means the model can speak while you're speaking, interrupt naturally, and recognize when you've started talking mid-response. Covo-Audio-Chat-FD reports turn-taking success at 99.7%, pause handling at 97.6%, and interruption handling at 96.81%. Backchanneling - brief verbal acknowledgments like "mm-hmm" - comes in at 93.89%.
Those numbers come from Tencent's own evaluation suite (MMSU). Take them with appropriate caution.
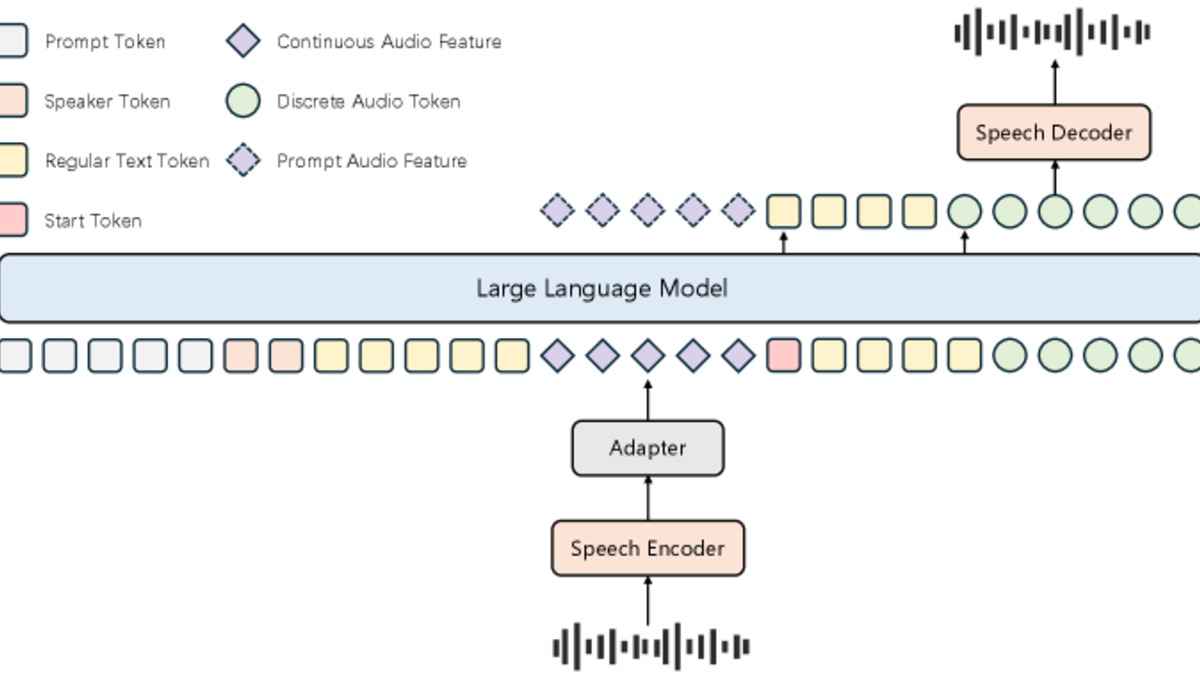 The Covo-Audio architecture integrates audio encoding, discrete speech tokens, and text through a single 7B language model backbone.
Source: arxiv.org
The Covo-Audio architecture integrates audio encoding, discrete speech tokens, and text through a single 7B language model backbone.
Source: arxiv.org
Benchmark Results
On MMAU-v05.15.25, the standard audio understanding benchmark, Covo-Audio hits 75.30% on average across sound comprehension (78.68%), music (76.05%), and speech understanding (71.17%). For context, Qwen2.5-Omni scores 71.50% at the same parameter count. Step-Audio 2 at roughly 32B parameters scores 77.58% - meaning Covo-Audio at 7B comes within 2.3 points of a model more than four times larger.
On speech translation (CoVoST2), English-to-Chinese scores 49.84 BLEU and Chinese-to-English 26.77 BLEU. Automatic speech recognition word error rate averages 4.71, with LibriSpeech clean/other at 1.45/3.21 - competitive with dedicated ASR systems.
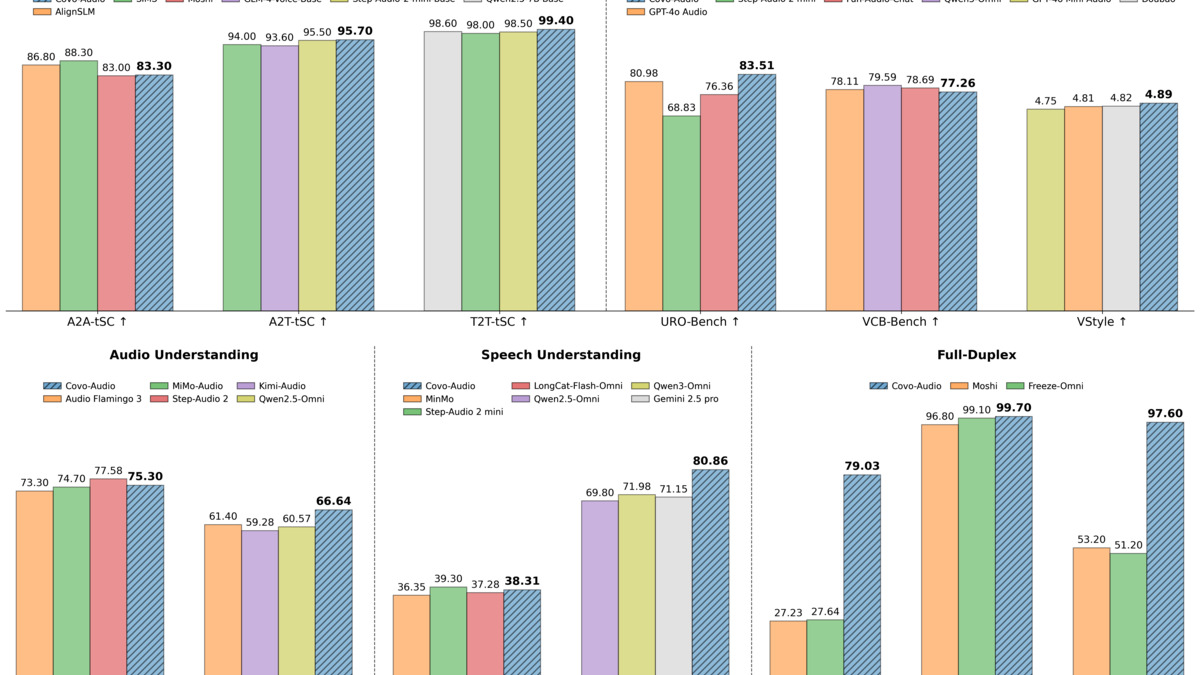 Benchmark results across spoken dialogue, speech understanding, and audio understanding tasks, comparing Covo-Audio against Qwen2.5-Omni, Step-Audio, and closed-source models.
Source: github.com/Tencent/Covo-Audio
Benchmark results across spoken dialogue, speech understanding, and audio understanding tasks, comparing Covo-Audio against Qwen2.5-Omni, Step-Audio, and closed-source models.
Source: github.com/Tencent/Covo-Audio
This follows a pattern that Alibaba set with Qwen and IBM has pursued with Granite: Chinese labs pushing open-weight models to match or exceed proprietary systems at a fraction of the parameter count.
The License Problem
Covo-Audio is released under a custom Tencent research license. The weights are downloadable, the code is on GitHub, but you can't just drop this into a commercial product without reading the terms carefully. It's not Apache 2.0, not MIT, not CC-BY. That puts it in the same category as Meta's Llama licenses: technically available, but with restrictions that matter for enterprise use.
Mistral's recent push toward fully Apache-licensed models shows there's a real competitive advantage in clean, permissive licensing. Tencent hasn't gone that route here.
What It Does Not Tell You
The paper doesn't report end-to-end latency under realistic conditions. Full-duplex conversation depends heavily on latency: a model that responds 800ms after you stop speaking feels natural; one that takes 2 seconds feels broken. Tencent shows quality metrics, not latency benchmarks.
Inference requirements are also underspecified. The model runs in BF16 and the architecture description suggests it demands real hardware - but there's no minimum VRAM figure, no benchmark on consumer GPUs, no reported cost per hour on cloud instances. Researchers can get it running, but it's not yet a drop-in production tool for most teams.
The benchmarks Tencent uses to show full-duplex quality (MMSU) are their own. Independent evaluations don't yet exist. That doesn't mean the results are wrong, but the numbers will need external replication before anyone should build product decisions on them.
Covo-Audio is a genuinely strong open-weight voice model - the full-duplex architecture in particular fills a gap that no open alternative has addressed at this quality level. The missing pieces are deployment clarity (latency, hardware requirements, cost) and licensing that enterprises can actually use. Those are fixable. For researchers and developers willing to work within the Tencent license, this is the most capable open option in real-time voice AI released so far.
Sources:

