SubQ Launches: 12M-Token Context on Sub-Quadratic AI
Subquadratic exits stealth with SubQ, the first frontier model built on a sparse-attention architecture, a $29M seed round, and a 12M-token context window that costs a fraction of Opus.

TL;DR
- Subquadratic exits stealth with a $29M seed round and its first model, SubQ - built on a sub-quadratic sparse-attention architecture
- 12M-token context window, 52x faster than FlashAttention at 1M tokens, under 5% the cost of Claude Opus 4.6
- SWE-Bench Verified: 81.8% - comparable to Claude Opus 4.6 at 80.8% - with RULER 128K accuracy of 95% at $8 vs $2,600 for Opus
- The company claims its architecture reduces compute by nearly 1,000x at the full 12M-token context, which it says breaks the transformer scaling ceiling
A startup called Subquadratic emerged from stealth Tuesday with a claim that gets louder every time someone runs out of context mid-project: it has built the first frontier language model that doesn't scale quadratically with input length.
The model is called SubQ. The seed round is $29 million. The context window is 12 million tokens - roughly nine million words, or the full source of a major software project - and the company says it can hold that window at a fraction of what comparable models cost.
The investors include Javier Villamizar, formerly of SoftBank Vision Fund, and Justin Mateen, the Tinder co-founder and founder of JAM Fund, along with backers who were early in Anthropic, OpenAI, Stripe, and Brex. The founding team - CEO Justin Dangel and CTO Alexander Whedon - previously worked at Meta.
 Subquadratic's product page, launched Tuesday alongside the $29M seed announcement.
Source: subq.ai
Subquadratic's product page, launched Tuesday alongside the $29M seed announcement.
Source: subq.ai
The Architecture Argument
Standard transformer attention computes a relationship score between every pair of tokens in a sequence. That's O(n²) complexity: double the input, quadruple the compute. The industry has worked around this with tricks - chunked attention, sliding windows, FlashAttention's memory-efficient implementation - but none of them change the underlying exponent.
Subquadratic says it did. SubQ is built on what the company calls a Sparse Sparse Attention architecture. Rather than scoring every possible token pair, the model identifies which relationships actually matter and ignores the rest. The result, according to the company, is O(n) complexity - linear, not quadratic.
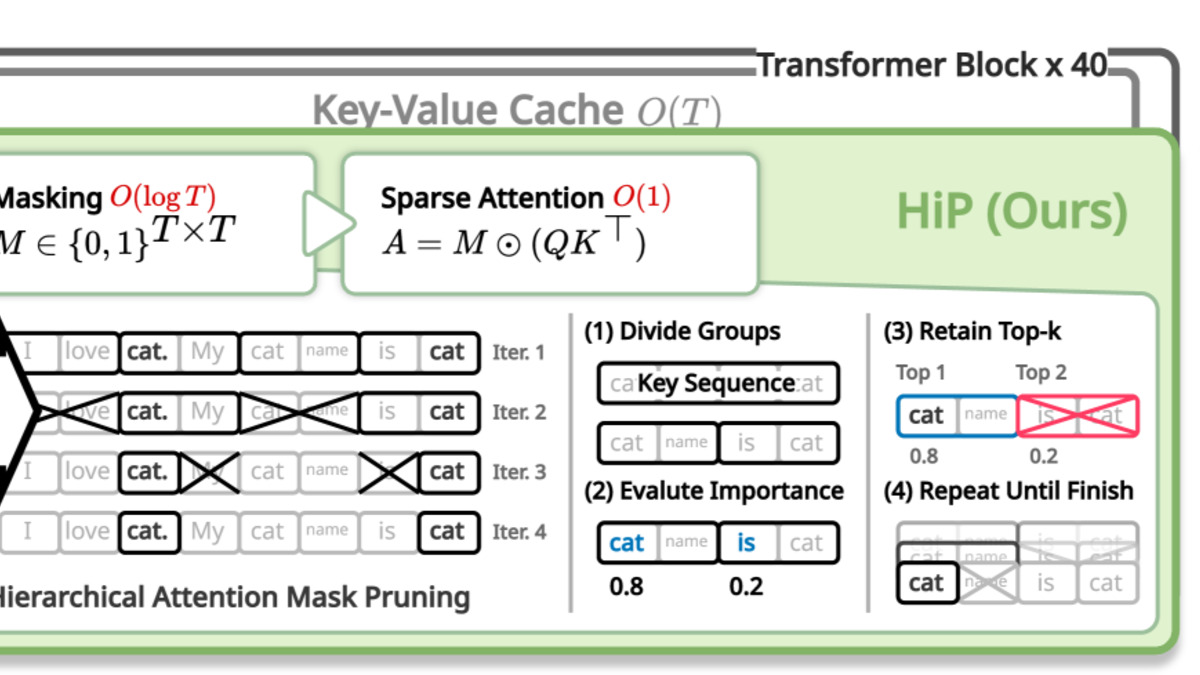 How sparse attention selects only the most relevant token relationships, discarding the rest - reducing computation from O(n²) to O(n) at scale.
Source: arxiv.org
How sparse attention selects only the most relevant token relationships, discarding the rest - reducing computation from O(n²) to O(n) at scale.
Source: arxiv.org
If you double the input size with quadratic scaling laws, you need four times the compute. With linear scaling laws, you need just twice.
That's CTO Alexander Whedon's framing. The practical claim: at 12 million tokens, SubQ uses roughly 1,000x less compute than a comparable transformer-based frontier model would at the same context length. At one million tokens - a size where most frontier models are either unavailable or prohibitively expensive - the company says SubQ is 52x faster than FlashAttention.
What the Benchmarks Say
The numbers Subquadratic is publishing are competitive enough to take seriously.
| Benchmark | SubQ | Claude Opus 4.6 |
|---|---|---|
| SWE-Bench Verified | 81.8% | 80.8% |
| RULER 128K accuracy | 95.0% | 94.0% |
| MRCR v2 | 65.9% | - |
| RULER cost | $8 | ~$2,600 |
The RULER result is the one that makes the cost argument concrete: SubQ hits higher long-context accuracy at $8 a run. A comparable Claude Opus run at that length costs around $2,600. That's not a rounding error; it's a different order of magnitude.
Claude's 1M context window launched without a pricing premium a few months ago, which lowered the bar for long-context inference across the industry. SubQ is positioning itself several steps past that threshold.
What Subquadratic Is Selling
The company is launching two products:
- SubQ API - OpenAI-compatible endpoints with the full 12M-token context, streaming, and tool use
- SubQ Code - a command-line coding agent that loads an entire codebase into a single context window without chunking or multi-agent coordination
The second product is the cleaner pitch. Most coding agents today chunk large codebases across multiple context windows and coordinate between them, which creates consistency problems and adds latency. SubQ Code aims to eliminate that coordination layer by holding everything at once.
The model is proprietary, not open-source - though Subquadratic says it can train customer-specific versions. The search product the company is building is initially free, which Dangel framed as a land-and-expand move.
The Skeptic's Take
"subquadratic" has become a crowded marketing category, and not all the claims in it hold up.
A LessWrong analysis published around the same time as the SubQ launch argues that most models sold as subquadratic - Kimi Linear, Mamba, RWKV, various diffusion approaches - either preserve quadratic attention in some layers, underperform at scale, or multiply inference FLOPs rather than reducing them. The pattern is: theoretical complexity claims that don't survive contact with real hardware constraints.
Subquadratic doesn't yet have an independent third-party verification of its complexity claims or a public technical paper describing the architecture in enough detail to copy. The benchmark numbers are self-reported. The architectural description on the website and in the launch coverage is high-level.
That doesn't mean the claims are false. The investor profile - people who backed Anthropic and OpenAI at early stages - suggests someone with technical credibility did enough diligence to write a check. The SWE-Bench number in particular isn't a number you can fake with clever prompting. But the architectural proof isn't yet public.
Why the Money Went Here
DeepSeek's pricing pressure on frontier models earlier this year showed that there is real demand for frontier-quality performance at clearly lower cost. The context window arms race that followed - from Gemini's 4M token window to Anthropic's 1M GA - showed that long context is a real differentiator, not a benchmark checkbox.
Subquadratic is making a bet that the transformer architecture itself is the bottleneck, not the training infrastructure or the data or the post-training stack. If the architecture claim holds at scale, the addressable market is large: any enterprise use case that requires processing long documents, large codebases, or extended conversational history, at a cost that makes it actually deployable in production.
The company's previous name was Aldea. It changed to Subquadratic sometime before launch, which is a fairly direct signal of how central the architectural claim is to the pitch.
The broader question is whether the efficiency gains hold at the scale of a full deployment, not just benchmark runs. That answer will come from early customers, and the company is taking access requests now.
Sources:
