Stanford 2026 AI Index - Cash In, Transparency Out
Stanford's 2026 AI Index shows global investment hitting $581B in 2025, while foundation model transparency scores fell by a third as capabilities raced ahead of governance.

Global corporate AI investment hit $581.7 billion in 2025, more than doubling the prior year's $253 billion. In the same period, the Foundation Model Transparency Index fell from 58 to 40. That combination - record spending, shrinking accountability - sits at the center of Stanford HAI's 2026 AI Index Report, published April 13.
The report is Stanford's annual attempt to hold a mirror to the field. Over 400 pages, it tracks capabilities, investment, public sentiment, employment, and environmental costs. This year the mirror isn't flattering.
TL;DR
- Global AI investment doubled to $581.7B in 2025, with US private investment alone at $285.9B
- The US-China model performance gap narrowed to just 2.7% on top benchmarks
- Foundation Model Transparency Index dropped from 58 to 40 - the most capable models disclose the least
- Entry-level software developer employment (ages 22-25) fell nearly 20% since 2024
- SWE-bench coding scores jumped from 60% to nearly 100% in a single year
| Metric | 2024 | 2025/2026 |
|---|---|---|
| Global AI investment | $253B | $581.7B (+130%) |
| US private investment | $125B | $285.9B (+128%) |
| Foundation Model Transparency Index | 58 | 40 |
| US-China performance gap | ~15% | 2.7% |
| SWE-bench Verified (best model) | ~60% | ~100% |
| Terminal-Bench task success | 20% | 77.3% |
| GenAI global adoption | ~35% | 53% |
| Entry-level dev jobs (ages 22-25) | baseline | -20% |
Capabilities Hit a New Ceiling
Coding and Reasoning
The jump in benchmark performance over the past year is real and measurable. On SWE-bench Verified, which tests AI models on real GitHub issues, scores climbed from around 60% to near 100% - matching or exceeding what human developers achieve. Terminal-Bench, a newer test measuring success on real-world agentic tasks, went from 20% in 2025 to 77.3% in 2026. Cybersecurity problem-solving on standardized challenges reached 93%, up from 15% a year earlier.
Frontier models now meet or exceed human performance on PhD-level science questions, competition mathematics, and multimodal reasoning. Google's Gemini Deep Think earned a gold medal at the 2025 International Mathematical Olympiad. These aren't incremental gains on contrived tests.
Where Models Still Fail
The report is careful not to let benchmark stories obscure the gaps. Robots still succeed on only 12% of standard household tasks. Top models read analog clocks correctly around 50% of the time. Multi-step planning, coherent long-form video generation, and spatial reasoning all remain weak. The gap between impressive narrow performance and general capability is wider than headlines suggest.
Stanford's James Zou, who contributed to the report, found that AI excels at spotting gaps in research literature but still struggles with judgment calls. Capability on known tests hasn't translated into reliable general-purpose reasoning.
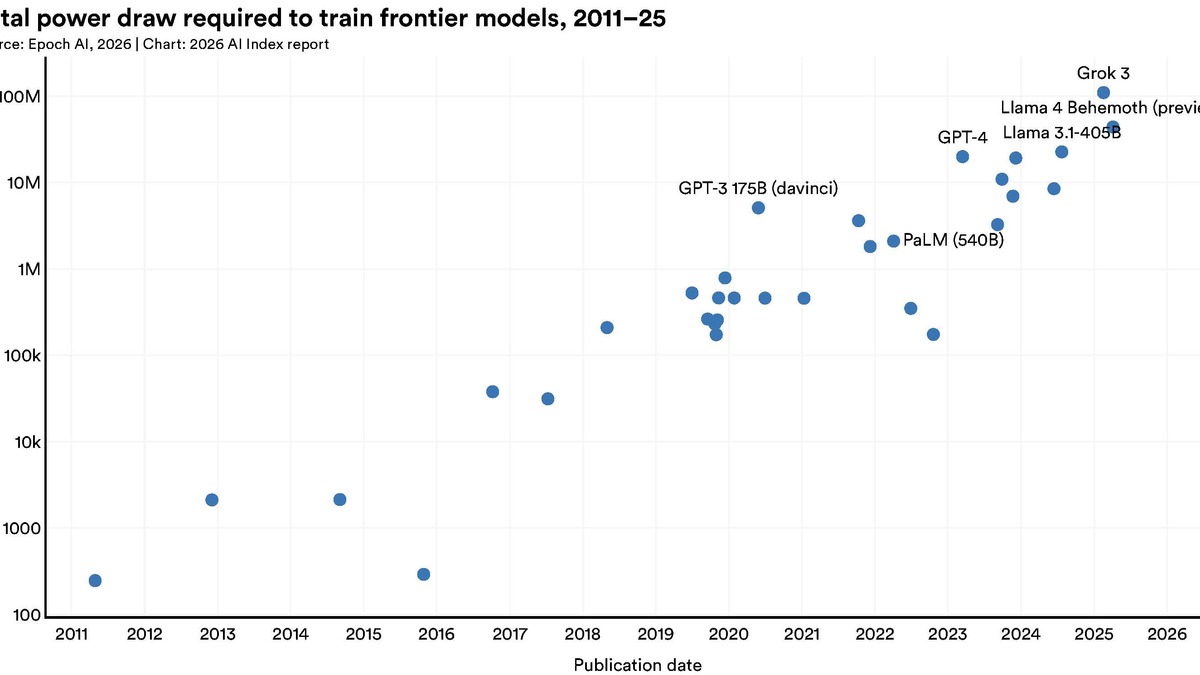 Global corporate AI investment reached $581.7B in 2025, up 130% from the prior year, with generative AI accounting for nearly half of all private funding.
Source: hai.stanford.edu
Global corporate AI investment reached $581.7B in 2025, up 130% from the prior year, with generative AI accounting for nearly half of all private funding.
Source: hai.stanford.edu
The Investment Surge
US vs China: Money vs Models
The US still leads on capital. Private US AI investment ($285.9 billion) was 23 times China's ($12.4 billion). Generative AI alone captured nearly half of all private AI funding globally, growing over 200% from 2024. By early 2026, Stanford estimates the annual consumer value of generative AI tools in the US alone at $172 billion, with the median value per user tripling between 2025 and 2026.
The Performance Gap Is Closing
Money doesn't buy a performance lead the way it used to. As of March 2026, Anthropic's leading model - Claude Mythos - holds a 2.7% edge over the top Chinese model on aggregate benchmarks. A year earlier that gap was closer to 15%. US and Chinese models swapped the top leaderboard position multiple times through early 2025.
The talent picture reinforces the concern. The number of AI researchers moving to the United States dropped 89% since 2017 and 80% in the past year alone. The US still trains and retains the most frontier researchers, but the inflow from abroad has nearly stopped. That matters for a sector where talent concentration has historically driven breakthrough results.
Transparency Is Going the Wrong Way
"Today's most capable modern models are now among the least transparent," the report notes, summarizing a pattern that cuts across all major AI labs.
The Foundation Model Transparency Index - a third-party measure of how much labs disclose about training data, compute, architecture, and risks - dropped from 58 to 40 out of 100. The decline wasn't uniform. Smaller, newer models from open-source projects tend to score higher. The largest proprietary frontier models, built by the labs with the most resources and the highest public visibility, consistently disclose the least.
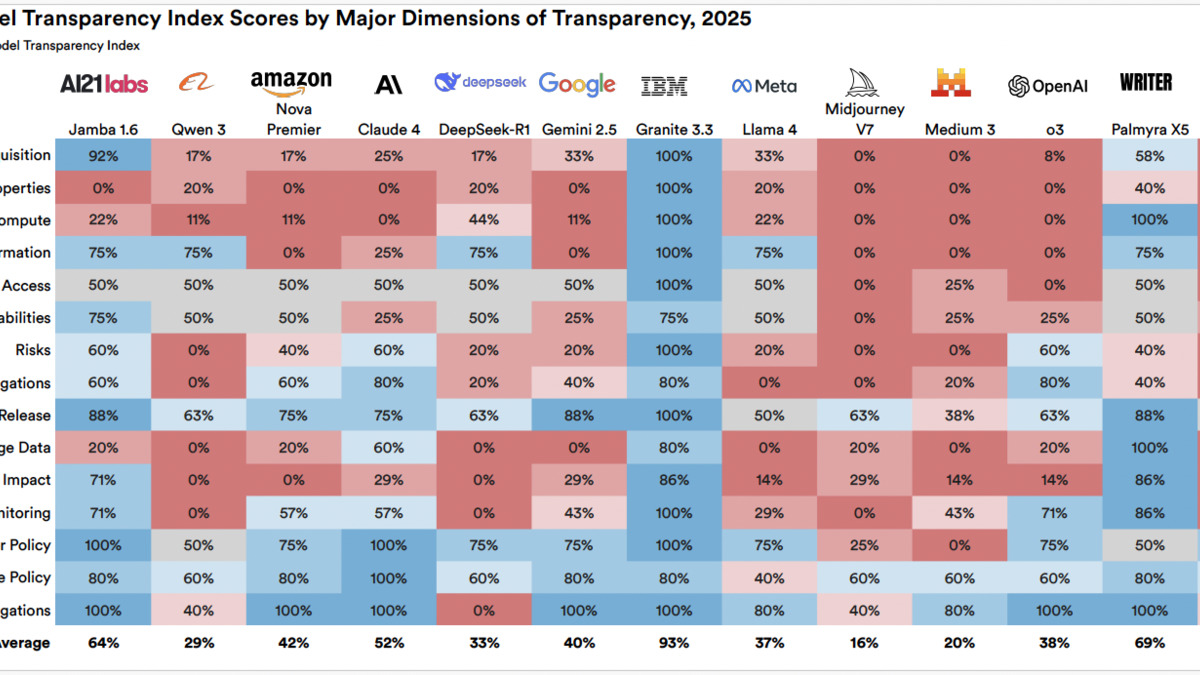 Transparency scores fell across major labs between 2024 and 2026, with the highest-capability models showing the steepest drops in disclosure.
Source: hai.stanford.edu
Transparency scores fell across major labs between 2024 and 2026, with the highest-capability models showing the steepest drops in disclosure.
Source: hai.stanford.edu
What Labs Are Hiding
The index measures specific disclosures: whether labs publish training data sources, compute costs, evaluation methodology, safety testing protocols, and model limitations. On most of these dimensions, disclosure worsened in 2025. Labs that once published model cards with detailed capability and limitation breakdowns have shifted toward marketing language. System prompt details, fine-tuning recipes, and RLHF methodology are rarely disclosed anymore.
This connects directly to the open source vs proprietary tension that has defined the last two years of AI development. Open-source projects are increasingly filling the transparency gap that proprietary labs have vacated, but they don't operate at the capability frontier. The models researchers and policymakers most need to understand are the ones least willing to be understood.
Jobs and the Trust Crisis
Entry-Level Workers Hit First
The report's employment numbers are concrete where many economic analyses of AI and jobs remain vague. Software developer employment among workers aged 22 to 25 fell nearly 20% since 2024. That's not a trend projection - it's measured headcount. Entry-level software roles, customer support, and routine data analysis positions show the earliest and sharpest displacement.
The productivity data offers context. AI use led to productivity gains of 14-26% in software development tasks and up to 72% in some marketing workflows. Higher output per worker, combined with cautious hiring, produces exactly the pattern the data shows: fewer entry-level positions, not fewer experienced ones. The AI and job loss debate has moved from theoretical to empirical.
Public Trust Is Falling
Generative AI reached 53% of the global population within three years - faster than personal computers or the internet. Four of five US students use AI for schoolwork. But adoption and trust are moving in opposite directions.
Only 23% of the US general public views AI's job market impact positively. Among AI experts surveyed, that number is 73%. The 50-point gap between what practitioners believe and what workers experience isn't a communication problem. It reflects a real divergence in who bears the costs and who captures the benefits.
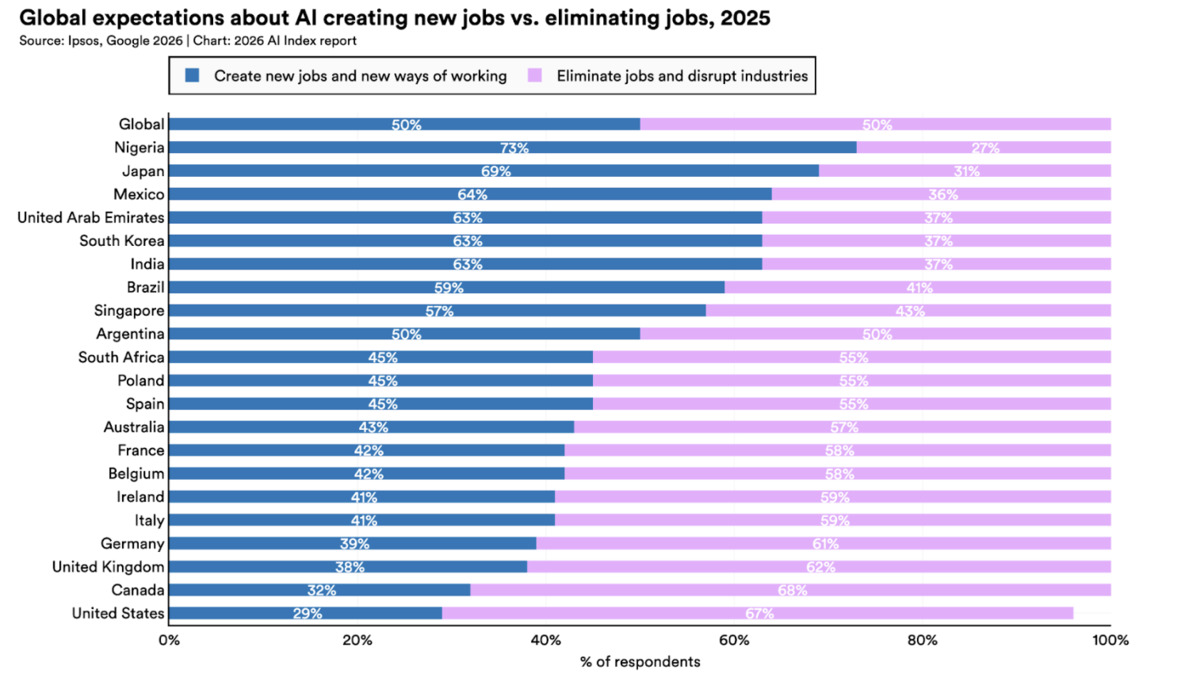 Public trust in AI's benefits varies sharply by country, with Singapore at 81% and the US trailing at 59% overall - but only 31% trusting government to regulate AI responsibly.
Source: hai.stanford.edu
Public trust in AI's benefits varies sharply by country, with Singapore at 81% and the US trailing at 59% overall - but only 31% trusting government to regulate AI responsibly.
Source: hai.stanford.edu
The US ranks last globally in public trust of government AI regulation, at 31%. Singapore leads at 81%. Only 33% of Americans expect AI to improve their own jobs. These numbers don't move with product launches or benchmark announcements.
What It Does Not Tell You
The report's methodology has limits worth naming. Investment figures come from corporate disclosures and VC databases, not audited accounts - the real numbers may differ. Benchmark scores reflect what labs choose to test and report; the Foundation Model Transparency Index decline makes it harder, not easier, to independently verify capability claims.
The employment data captures broad sectors but can't distinguish AI-driven displacement from macroeconomic shifts or post-pandemic labor market normalization. The 20% drop in entry-level developer jobs is real, but attributing it completely to AI requires more granular analysis than the report provides.
The US-China performance gap figure (2.7%) depends on which benchmarks you weight and when you measure. By the time the report published in April, both labs and the competitive situation had likely shifted.
None of this invalidates the report's core findings. But a 400-page document should be read as a data collection, not a verdict.
The Stanford AI Index is one of the few credible attempts to track the AI field methodically across multiple dimensions. This year's edition documents a field that's becoming measurably more capable, dramatically better funded, and meaningfully less transparent - all at the same time. A Transparency Index score of 40 out of 100 is the lowest the report has ever recorded. Labs spent $581 billion last year; they apparently couldn't spare the effort to explain what they built.
Sources:
- 2026 AI Index Report - Stanford HAI
- Inside the AI Index: 12 Takeaways from the 2026 Report
- Stanford AI Index 2026 - The Decoder
- Stanford AI Index 2026 Reveals a Field Racing Ahead of Its Guardrails - Unite.AI
- Stanford AI Index 2026 Report Details - Digital Information World
- Stanford's AI Index for 2026 Shows the State of AI - IEEE Spectrum
