SkillsBench Shows a $1 Model With Expert Guides Beats a $15 Model Without Them
A new benchmark of 84 real-world tasks across 11 domains proves that small AI models armed with human-written step-by-step guides outperform frontier models running blind. The catch: models cannot write these guides themselves.
TL;DR
- SkillsBench tests 7 AI agent configurations on 84 practical tasks across 11 domains - healthcare, cybersecurity, finance, manufacturing, and more
- Human-curated "skills" (step-by-step markdown guides) boost pass rates by 16.2 percentage points on average
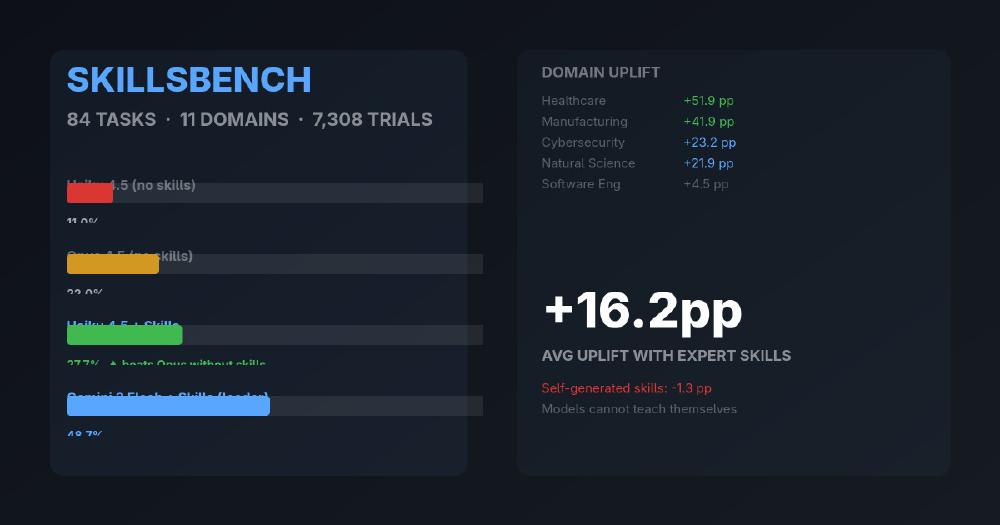
- Claude Haiku 4.5 with skills (27.7%) beats the far more expensive Claude Opus 4.5 without them (22.0%)
- Self-produced skills backfire: models that write their own guides average -1.3 pp versus baseline - they cannot teach themselves
- Gemini CLI with Gemini 3 Flash leads the leaderboard at 48.7% with skills; healthcare saw the biggest uplift at +51.9 pp
- The team also released OpenThoughts-TBLite, a faster coding benchmark designed for smaller models
There's a recurring assumption in AI: bigger models solve harder problems. Throw more parameters, more compute, more money at the problem, and performance goes up. SkillsBench, a new benchmark from BenchFlow with contributions from 105 researchers across academia and industry, just put hard numbers behind why that assumption is wrong - or at least incomplete.
The paper presents a simple experiment: take 84 real-world tasks across 11 professional domains, test 7 frontier AI agent configurations under three conditions (no guidance, human-written skills, and self-created skills), run 7,308 trials with deterministic verification, and measure what actually makes a difference.
The answer is not model size. It's the quality of the instructions you give the model.
What Are Skills?
In SkillsBench's framework, a "skill" is a structured package - a SKILL.md markdown file plus optional code templates, reference resources, and verification logic - that encodes procedural knowledge: standard operating procedures, domain conventions, and task-specific heuristics.
Think of it as the difference between handing someone a medical textbook (the model's training data) and handing them a step-by-step protocol for diagnosing chest pain in an ER (a skill). The textbook contains the information somewhere. The protocol tells you what to do right now, in what order, and what to check.
Skills are injected at inference time. No fine-tuning, no model modification - just better prompts backed by domain expertise.
The Results
Here is the full leaderboard from the paper, testing each model with and without curated skills:
| Agent + Model | No Skills | With Skills | Uplift |
|---|---|---|---|
| Gemini CLI + Gemini 3 Flash | 31.3% | 48.7% | +17.4 pp |
| Claude Code + Opus 4.5 | 22.0% | 45.3% | +23.3 pp |
| Codex CLI + GPT-5.2 | 30.6% | 44.7% | +14.1 pp |
| Claude Code + Opus 4.6 | 30.6% | 44.5% | +13.9 pp |
| Gemini CLI + Gemini 3 Pro | 27.6% | 41.2% | +13.6 pp |
| Claude Code + Sonnet 4.5 | 17.3% | 31.8% | +14.5 pp |
| Claude Code + Haiku 4.5 | 11.0% | 27.7% | +16.7 pp |
Two things jump out right away.
First, skills matter more than model scale. Claude Haiku 4.5 - the cheapest, smallest model in Anthropic's lineup - with curated skills (27.7%) comfortably beats Claude Opus 4.5 without them (22.0%). That's a model costing roughly a fraction of Opus beating the flagship, simply by having better instructions.
Second, the biggest winner is Gemini 3 Flash - not the Pro variant. A lighter, cheaper model with the right guidance topped the entire leaderboard at 48.7%.
The average uplift across all configurations was +16.2 percentage points. For context, that is the kind of improvement that typically takes a full model generation to achieve.
Where Skills Matter Most (and Least)
The domain-level breakdown reveals where procedural knowledge is most valuable:
| Domain | No Skills | With Skills | Uplift |
|---|---|---|---|
| Healthcare | 34.2% | 86.1% | +51.9 pp |
| Manufacturing | 1.0% | 42.9% | +41.9 pp |
| Cybersecurity | 20.8% | 44.0% | +23.2 pp |
| Natural Science | 23.1% | 44.9% | +21.9 pp |
| Energy | 29.5% | 47.5% | +17.9 pp |
| Office & White Collar | 24.7% | 42.5% | +17.8 pp |
| Finance | 12.5% | 27.6% | +15.1 pp |
| Media & Content | 23.8% | 37.6% | +13.9 pp |
| Robotics | 20.0% | 27.0% | +7.0 pp |
| Mathematics | 41.3% | 47.3% | +6.0 pp |
| Software Engineering | 34.4% | 38.9% | +4.5 pp |
The pattern is telling. Healthcare saw the largest gain (+51.9 pp) - a domain built on rigid protocols, checklists, and decision trees that maps perfectly to structured procedural guidance. Manufacturing, another protocol-heavy field where models have minimal training data, jumped from nearly zero (1.0%) to 42.9%.
At the bottom: software engineering (+4.5 pp) and mathematics (+6.0 pp). These are domains where frontier models have seen enormous training data and where reasoning ability matters more than step-by-step protocols. The models already know how to code. They don't already know your hospital's triage workflow.
The implication for enterprise AI is significant: the less your domain looks like the internet, the more skills will help.
The Self-Generation Trap
Here is the finding that should concern anyone building autonomous agent systems: models can't write their own skills.
When prompted to create their own procedural guides before attempting tasks, models averaged -1.3 percentage points compared to working without any skills at all. Only Claude Opus 4.6 showed a marginal positive effect (+1.4 pp). Every other model performed worse with self-produced guidance than with none.
As Hacker News commenters pointed out, the experimental setup is somewhat artificial - models created skills "cold" without iterative refinement or feedback from failed attempts. In practice, a human-in-the-loop workflow where skills are refined after failures works better.
But the core point stands: the procedural knowledge that makes skills effective is precisely the knowledge models lack. They can't distill what they don't have. The textbook can't write the clinical protocol - that requires a clinician who has done the work.
Compact Beats Comprehensive
The paper also tested skill design principles and found a counterintuitive result: less is more.
- 2-3 skills per task produced the optimal uplift (+18.6 pp)
- 4+ skills showed fading returns (+5.9 pp)
- Compact, targeted skills (+17.1 pp) beat comprehensive documentation (-2.9 pp) by a wide margin
Dumping everything you know into a massive reference document actually hurts agent performance. The models get overwhelmed. Focused, opinionated guides that say "do this, then this, use this specific function" beat exhaustive wikis by nearly 4x.
This tracks with what practitioners have reported anecdotally about prompt engineering: specificity beats thoroughness.
A Real Example: Flood Risk Analysis
The paper highlights a concrete case. In a flood-risk analysis task, agents without skills achieved a 2.9% pass rate - basically random guessing. After receiving a curated skill specifying the correct statistical methods and relevant scipy functions, success rates jumped to 80%.
The skill didn't contain the answer. It contained the approach - the domain expert's knowledge of which tools to reach for and in what order. That is the gap between a model that has read every statistics textbook and an analyst who has done flood risk modeling for a decade.
OpenThoughts-TBLite: A Faster Coding Benchmark
With SkillsBench, the team released OpenThoughts-TBLite, a streamlined coding benchmark designed to produce meaningful signal for smaller models. Where existing coding benchmarks like SWE-Bench are calibrated for frontier-class models, TBLite creates a more accessible evaluation that lets researchers test whether lightweight models can perform practical terminal-based tasks.
The motivation is the same philosophy driving SkillsBench: you don't always need the biggest model. You need the right model with the right guidance, assessed on the right tasks.
What This Means for the Industry
SkillsBench formalizes what more AI engineers have been discovering in production: the bottleneck isn't model capability - it's knowledge engineering.
The consequences are practical:
For teams launching AI agents: Invest in building skill libraries. A junior model with good skills beats a senior model without them. The ROI on having domain experts write structured guides is massive - potentially worth more than upgrading to a more expensive model.
For model providers: The leaderboard order changes when you add skills. Gemini 3 Flash beats Opus 4.6. Haiku beats Opus. Raw benchmark scores without skills are an increasingly misleading measure of real-world agent utility.
For the "autonomous agent" narrative: Self-produced skills don't work. The dream of fully autonomous agents that teach themselves new domains isn't supported by this data. Human expertise remains the critical ingredient - it just gets expressed differently, as structured procedural guides instead of manual execution.
For enterprise buyers: The most expensive model isn't automatically the best choice. A smaller model with domain-specific skills can beat at a fraction of the cost. The new moat isn't which model you use - it is the quality of your skill library.
The era of "just use a bigger model" is giving way to something more nuanced: use the right model, give it the right knowledge, and keep the instructions tight. SkillsBench just proved it with 7,308 trials across 84 tasks.
Smart engineering beats brute force. The benchmarks finally show it.
Last updated

