A $900 RTX 3090 Now Beats an M5 Max at LLM Inference
Two researchers fused all 24 layers of Qwen 3.5-0.8B into a single CUDA kernel launch, making a five-year-old RTX 3090 deliver 1.8x the throughput of an M5 Max at equal or better efficiency. The gap was software, not silicon.
TL;DR
- Two researchers (Sandro Puppo and Davide Ciffa) fused all 24 layers of Qwen 3.5-0.8B into a single CUDA kernel launch, eliminating ~100 kernel dispatches per token
- Results on an RTX 3090 power-limited to 220W: 411 tok/s (vs 229 tok/s on M5 Max), 1.87 tok/J matching or exceeding Apple's efficiency
- The same GPU with llama.cpp only manages 267 tok/s - the 1.55x speedup is purely from better software
- This is the first megakernel for DeltaNet, the hybrid linear-attention architecture used by Qwen 3.5, Kimi, and other next-gen models
- Open source: github.com/Luce-Org/luce-megakernel
Everyone accepts the tradeoff: NVIDIA GPUs are fast but power-hungry, Apple Silicon is slower but efficient. Pick one.
Two researchers just proved that tradeoff is an artifact of lazy software, not physics.
The baseline nobody questions
Running Qwen 3.5-0.8B on stock frameworks produces numbers that reinforce the conventional wisdom:
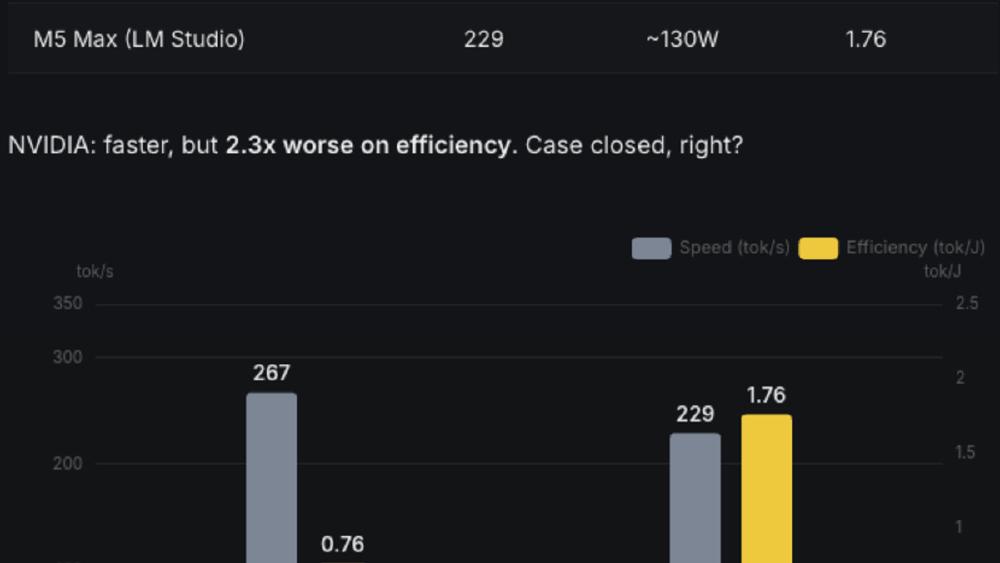
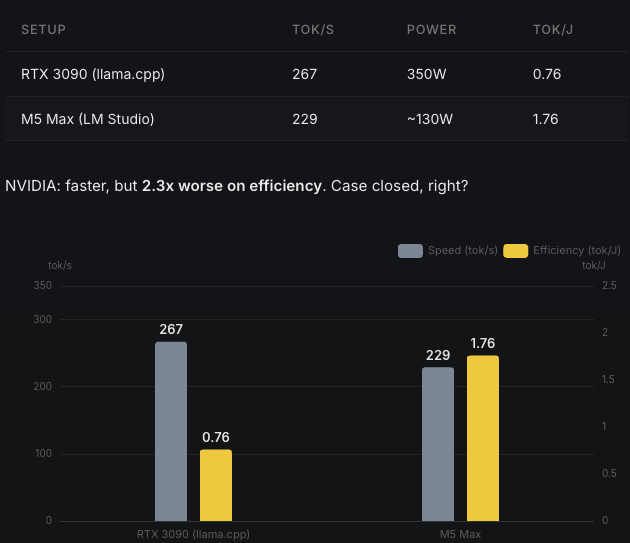 Stock framework performance: the RTX 3090 barely edges out a laptop chip while consuming far more power.
Stock framework performance: the RTX 3090 barely edges out a laptop chip while consuming far more power.
The RTX 3090 with llama.cpp manages 267 tok/s. The M5 Max hits 229 tok/s. The NVIDIA card is marginally faster but draws significantly more power. If you stop here, Apple wins on efficiency and the story is over.
But the RTX 3090 has 936 GB/s of memory bandwidth and 142 TFLOPS of FP16 compute. Getting 267 tok/s from that hardware is like driving a sports car in first gear.
Why frameworks leave performance on the table
Standard inference frameworks run each layer as a separate kernel launch. For a 24-layer model, that means roughly 100 kernel dispatches per token. Each dispatch:
- Returns control to the CPU
- Dispatches the next kernel
- Re-fetches weights from global memory
- Synchronizes threads
Each launch wastes microseconds. Those microseconds burn power doing nothing useful. Multiply by thousands of tokens per second and the overhead becomes the bottleneck.
A new architecture nobody has optimized
Qwen 3.5-0.8B isn't a standard transformer. It alternates between two layer types:
 Qwen 3.5-0.8B's hybrid architecture: 18 DeltaNet layers (linear attention with learned recurrence) and 6 full attention layers.
Qwen 3.5-0.8B's hybrid architecture: 18 DeltaNet layers (linear attention with learned recurrence) and 6 full attention layers.
- 18 DeltaNet layers: linear attention with a learned recurrence that scales linearly with context length
- 6 full attention layers: standard multi-head attention
This hybrid pattern is where LLMs are heading. Qwen3-Next, Kimi Linear, and others use it because linear attention avoids the quadratic scaling problem. But nobody has written a fused kernel for it. MLX doesn't have DeltaNet kernels. llama.cpp supports it generically. The 267 tok/s on the RTX 3090 isn't a hardware limit. It's a software one.
One kernel launch
Sandro Puppo and Davide Ciffa wrote a single CUDA kernel that processes all 24 layers in one dispatch. No CPU round-trips between layers. No redundant memory fetches. Data stays in registers and shared memory as it flows through the entire network.
The technical specifics:
- 82 blocks, 512 threads: all SMs on the RTX 3090 stay occupied
- BF16 weights, BF16 activations, FP32 accumulation
- DeltaNet recurrence runs natively: warp-cooperative state updates in F32 registers
- Full attention with online softmax: fused QKV, RoPE, causal attention, output projection
- Zero inter-layer overhead: cooperative grid sync replaces kernel launches
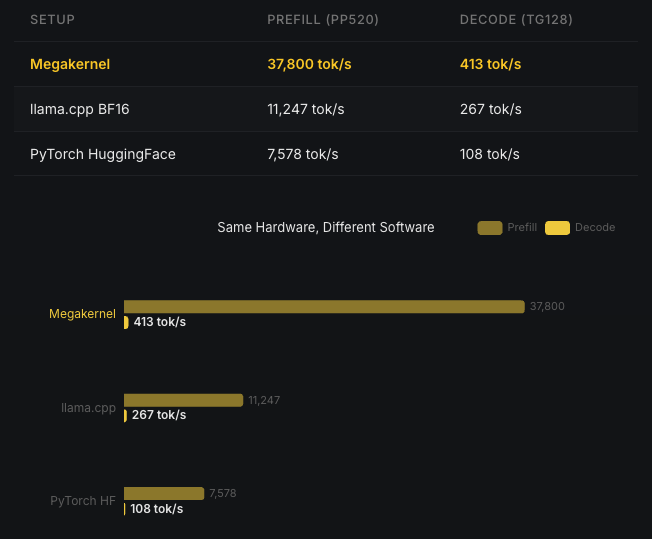
 Megakernel results: 3.4x faster prefill, 1.55x faster decode. Same hardware, same model, same weights.
Megakernel results: 3.4x faster prefill, 1.55x faster decode. Same hardware, same model, same weights.
3.4x faster prefill. 1.55x faster decode. Same GPU, same model, same weights.
Turn down the power
Fewer wasted cycles means less heat. So cutting power should cost less speed than it normally would.
 Power limit sweep: at 220W (30% below stock 350W), the RTX 3090 retains 95% of its megakernel throughput. The efficiency sweet spot is where tighter execution converts directly into saved watts.
Power limit sweep: at 220W (30% below stock 350W), the RTX 3090 retains 95% of its megakernel throughput. The efficiency sweet spot is where tighter execution converts directly into saved watts.
At 220W - 30% below the RTX 3090's stock 350W TDP - the card retains 95% of its speed. The curve is nonlinear: there's a sweet spot where tighter execution converts directly into saved watts because the GPU isn't wasting energy on kernel launch overhead and memory re-fetches.
The comparison that matters
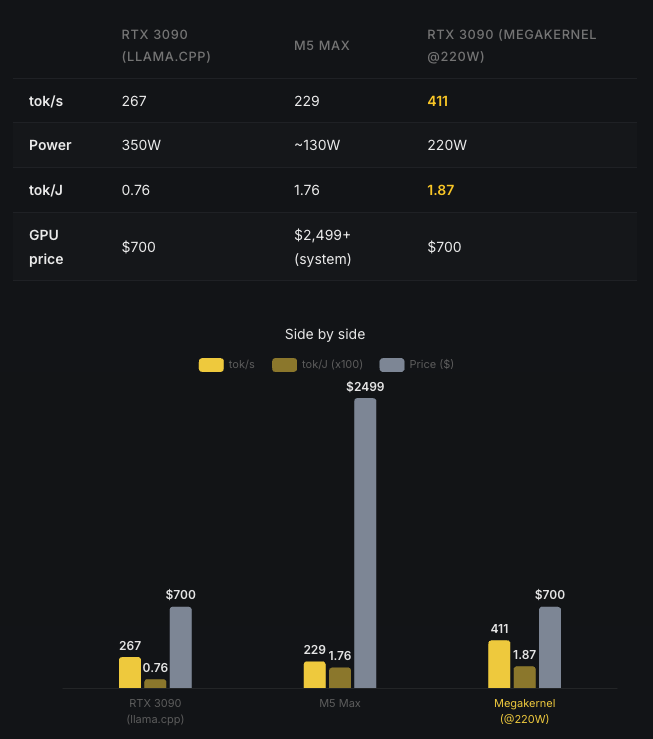 The full picture: without the megakernel, the RTX 3090 barely edges out Apple. With it, the same 2020 GPU delivers 1.8x the throughput at equal or better efficiency.
The full picture: without the megakernel, the RTX 3090 barely edges out Apple. With it, the same 2020 GPU delivers 1.8x the throughput at equal or better efficiency.
| Configuration | Throughput | Efficiency |
|---|---|---|
| RTX 3090 + llama.cpp (350W) | 267 tok/s | ~0.76 tok/J |
| Apple M5 Max + MLX | 229 tok/s | ~1.87 tok/J |
| RTX 3090 + megakernel (220W) | 411 tok/s | 1.87 tok/J |
The RTX 3090 with the megakernel delivers 1.8x the throughput of an M5 Max while matching its efficiency. On a chip from 2020. At roughly one-sixth the system cost.
What broke along the way
The researchers documented their failures, which is more useful than the results:
grid.sync() inside a loop = instant deadlock. Their first attempt synchronized all blocks inside the per-token DeltaNet recurrence loop. Every block waited for every other block. No error message, just silence. The fix: synchronize between layers, not within them.
Register pressure is the real enemy. They tried tiling the 128x128 DeltaNet state matrix with S_TILE=16 for better instruction-level parallelism. Silent crash. No CUDA error. The compiler spilled registers to local memory, performance collapsed, and eventually the kernel stopped. S_TILE=8 was the sweet spot.
Why this matters beyond benchmarks
This is the first megakernel for DeltaNet, the hybrid recurrent-attention architecture that's replacing pure transformers in production. As more models adopt this pattern (Qwen 3.5 already ships with it), the inference stack matters more than the spec sheet.
The efficiency gap between NVIDIA and Apple wasn't a hardware gap. It was a software gap. When someone writes a kernel that actually uses what the GPU offers - tensor cores, shared memory, cooperative grid launches, register-resident state - a five-year-old consumer GPU matches Apple's latest chip on power efficiency while delivering nearly twice the speed.
The megakernel is open source. Requirements: any Ampere+ NVIDIA GPU, CUDA 12+, PyTorch 2.0+, ~1.5GB VRAM for BF16 weights.
Sources:
