Qwen 3.6 Ships a 35B MoE That Codes Like Models 10x Its Size
Alibaba's Qwen 3.6-35B-A3B activates only 3B of its 35B parameters per token, scores 73.4% on SWE-bench Verified, handles video and images, and ships under Apache 2.0.
TL;DR
- Qwen 3.6-35B-A3B is a 35B total / 3B active sparse MoE with vision and video understanding, released under Apache 2.0
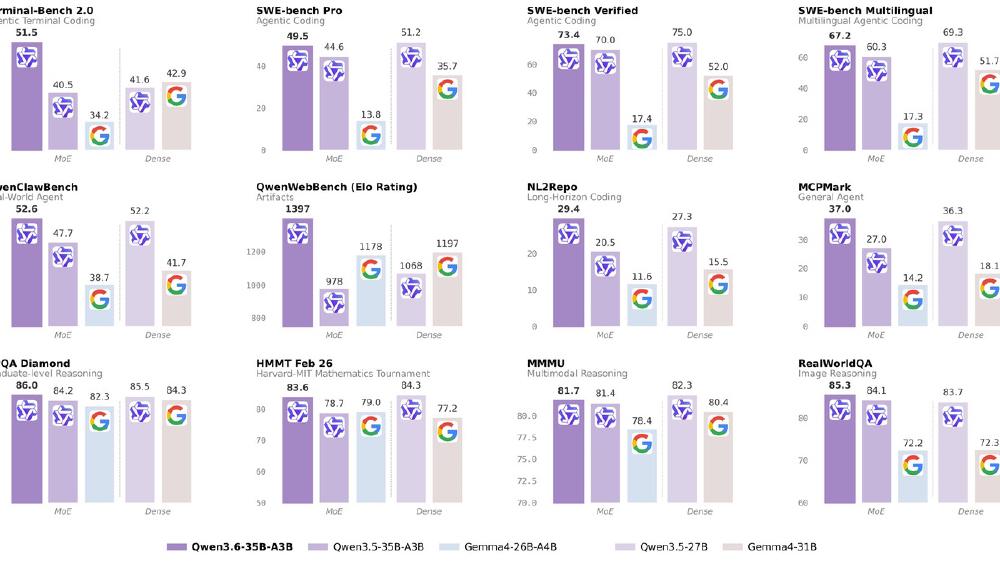
- 73.4% SWE-bench Verified and 51.5% Terminal-Bench 2.0 - matching models with 10x the active parameters on coding benchmarks
- 256K native context (extensible to 1M), 256 experts with 8 routed + 1 shared, Gated DeltaNet hybrid architecture
- Beats its predecessor Qwen 3.5-35B-A3B by +3.4 on SWE-bench, +11 on Terminal-Bench, and +3.3 on video understanding
Alibaba's Qwen team continues to compress frontier-level coding ability into models you can actually run on consumer hardware. Qwen 3.6-35B-A3B activates just 3 billion parameters per token out of its 35 billion total, yet posts 73.4% on SWE-bench Verified - a score that would have led our coding benchmarks leaderboard six months ago.
What's new in 3.6
The improvements over Qwen 3.5-35B-A3B concentrate on agentic coding and multimodal perception:
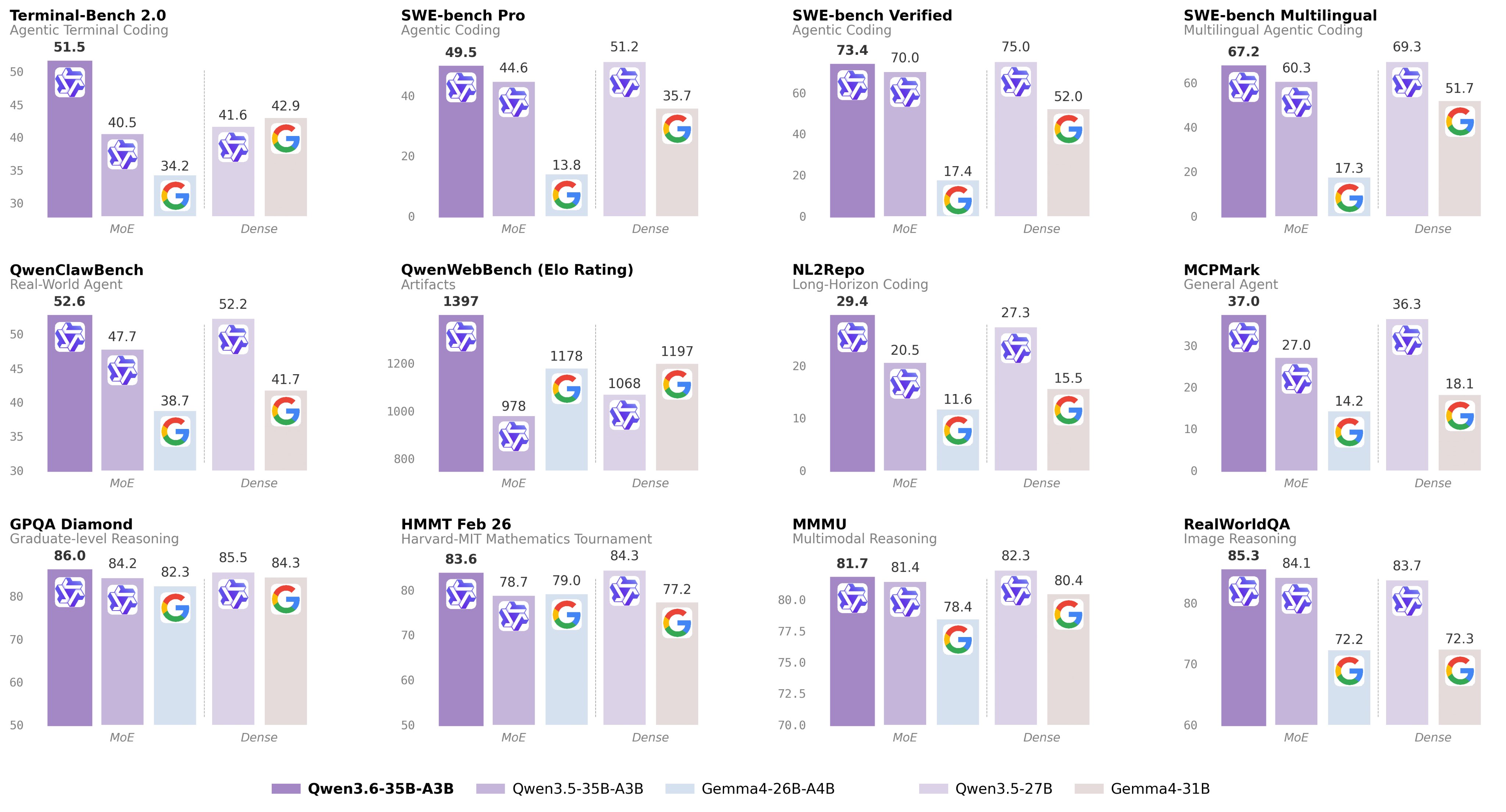 Qwen 3.6-35B-A3B benchmark improvements across coding, reasoning, and vision tasks.
Qwen 3.6-35B-A3B benchmark improvements across coding, reasoning, and vision tasks.
| Benchmark | Qwen 3.5 | Qwen 3.6 | Delta |
|---|---|---|---|
| SWE-bench Verified | 70.0 | 73.4 | +3.4 |
| Terminal-Bench 2.0 | 40.5 | 51.5 | +11.0 |
| QwenWebBench | 978 | 1,397 | +43% |
| MCPMark | 27.0 | 37.0 | +10.0 |
| GPQA Diamond | 84.2 | 86.0 | +1.8 |
| AIME 2026 | 91.0 | 92.7 | +1.7 |
| RefCOCO (spatial) | 89.2 | 92.0 | +2.8 |
| VideoMMU | 80.4 | 83.7 | +3.3 |
| ODInW13 | - | 50.8 | new |
The Terminal-Bench jump (+11 points) is the most significant. This benchmark measures agentic coding in terminal environments - the kind of autonomous repo-level work that matters for tools like Claude Code and Cursor. Going from 40.5 to 51.5 pushes a 3B-active model into territory that previously required 10x the compute.
Architecture
The model uses Qwen's hybrid Gated DeltaNet + attention architecture:
- 40 layers organized as: 10 blocks of (3 DeltaNet layers + 1 attention layer), each paired with MoE routing
- 256 total experts, 8 routed + 1 shared active per token
- Gated DeltaNet: linear attention with learned recurrence (same architecture that the Luce megakernel research optimized for)
- 256K native context extensible to 1M via YaRN scaling
- Multimodal: text, images, and video with configurable frame sampling
The DeltaNet layers scale linearly with context length instead of quadratically - critical for the long-context agentic work the model targets.
Vision and video
This isn't a text-only model with vision bolted on. The vision benchmarks are competitive:
| Benchmark | Score |
|---|---|
| MMMU | 81.7 |
| MMMU-Pro | 75.3 |
| MMBench EN-DEV | 92.8 |
| RefCOCO (spatial avg) | 92.0 |
| ODInW13 (object detection) | 50.8 |
| VideoMMU | 83.7 |
| MLVU | 86.2 |
RefCOCO at 92.0 means the model handles spatial reasoning and object grounding well. VideoMMU at 83.7 puts it ahead of many proprietary models for video understanding tasks.
Running it locally
The Q4_K_XL quantization fits in 22.4 GB - runnable on a single RTX 4090 or dual RTX 3090s. At the extreme end, the UD-IQ2_XXS quantization compresses to 10.8 GB for single-GPU inference on a 12GB card, though with quality trade-offs.
# SGLang (recommended)
python -m sglang.launch_server --model-path Qwen/Qwen3.6-35B-A3B \
--port 8000 --tp-size 1 --mem-fraction-static 0.8 \
--context-length 262144 --reasoning-parser qwen3
Thinking and non-thinking modes are both supported. The model supports preserve_thinking for iterative development - carrying reasoning context across turns without re-generating it.
The competitive picture
At 3B active parameters and Apache 2.0 licensing, Qwen 3.6-35B-A3B occupies a unique position. Gemma 4 is the closest open-weight competitor at 26B total (also Apache 2.0), but Gemma's 31B Dense model activates all parameters while Qwen's MoE activates 3B. For inference cost and latency, Qwen wins. For raw benchmark scores on academic evals, Gemma is competitive. For agentic coding specifically, Qwen 3.6's Terminal-Bench and SWE-bench scores pull ahead.
Against proprietary models, 73.4% SWE-bench Verified puts Qwen 3.6 ahead of GPT-5.4 (77.2% but at $2.50/$15 per M tokens) in effective value, though behind Opus 4.7 and Gemini 3.1 Pro in absolute scores.
Sources:
