Qwen3.5-Omni Does 10-Hour Audio and 4M Video Frames
Alibaba's Qwen3.5-Omni handles audio, video, images, and text in a single model pass - and generates speech in real time. The Plus variant hits SOTA on 215 benchmarks and edges out Gemini 3.1 Pro on audio tasks.

Alibaba's Qwen team shipped Qwen3.5-Omni on March 30 - a natively multimodal model that takes text, images, audio, and video as input and produces both text and streaming speech as output, all in one forward pass. There's no audio adapter bolted onto a language model here. The Thinker and Talker components are trained together from the start, on more than 100 million hours of native multimodal data.
Key Specs
| Spec | Value |
|---|---|
| Release date | March 30, 2026 |
| Variants | Plus (~30B MoE), Flash, Light |
| Context window | 256K tokens |
| Max audio input | 10+ hours continuous |
| Max video input | 400+ seconds of 720p at 1 FPS |
| Speech recognition | 113 languages and dialects |
| Speech generation | 36 languages |
| License | Apache 2.0 |
| Access | DashScope API, WebSocket realtime, self-host via HF |
The predecessor, Qwen3-Omni, handled 19 languages for speech input and 10 for output. The 3.5 generation goes to 113 and 36 respectively - a jump that matters for anything outside the English-Chinese axis.
Architecture: Thinker Meets Talker
The model splits reasoning and speech synthesis into two components that share weights but specialize.
The Thinker
The Thinker handles all input processing - text, images, audio waveforms, video frames - through a Hybrid-Attention Mixture-of-Experts architecture. On each token, only a subset of experts activates, which lets the Plus variant (~30B total parameters, ~3B active per token) run at far lower inference cost than a dense 30B model.
The Talker
The Talker converts the Thinker's representations into streaming speech tokens in real time. Rather than passing a complete text response to a separate TTS system, the Talker runs concurrently with generation, reducing latency for voice applications.
Both components are jointly trained - this is what makes the end-to-end design work. When the Thinker's reasoning changes, the Talker's prosody follows. The model can whisper, shout, narrate, or speak with controlled emotional tone because it understands context at the reasoning level, not just the text level.
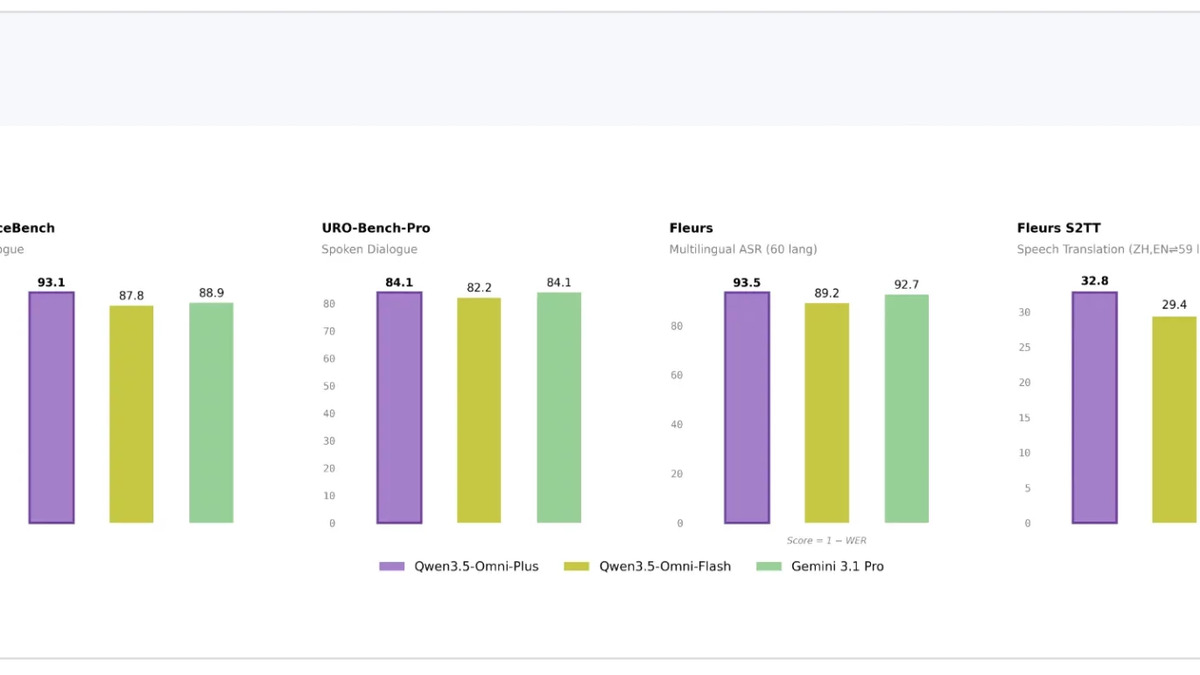 Qwen3.5-Omni-Plus versus Gemini 3.1 Pro on audio understanding benchmarks. Lower is better on LibriSpeech word error rate.
Source: analyticsvidhya.com
Qwen3.5-Omni-Plus versus Gemini 3.1 Pro on audio understanding benchmarks. Lower is better on LibriSpeech word error rate.
Source: analyticsvidhya.com
Benchmark Numbers
The Qwen team claims 215 state-of-the-art results for the Plus variant across audio, audio-video, visual, and text benchmarks. The headline numbers that matter to practitioners:
| Benchmark | Qwen3.5-Omni-Plus | Gemini 3.1 Pro | GPT-Audio |
|---|---|---|---|
| MMAU (audio understanding) | 82.2 | 81.1 | - |
| VoiceBench (dialogue) | 93.1 | 88.9 | - |
| LibriSpeech clean WER | 1.11 | 3.36 | - |
| LibriSpeech other WER | 2.23 | 4.41 | - |
| MMLU-Redux (text) | 94.2 | - | - |
| MMMU-Pro (visual reasoning) | 73.9 | - | - |
On word error rate (lower is better), Qwen3.5-Omni-Plus cuts the Gemini 3.1 Pro error rate by roughly two thirds on both LibriSpeech clean and other test sets. Audio dialogue accuracy on VoiceBench runs four percentage points ahead.
The text performance gap between the Omni variant and the standard Qwen3.5-Plus model is small: MMLU-Redux 94.2 vs 94.3, C-Eval 92.0 vs 92.3. The multimodal architecture doesn't cost much on text tasks.
New Features in 3.5
Audio-Visual Vibe Coding
The most developer-facing addition is Audio-Visual Vibe Coding - a workflow where you point a camera or share a screen and describe what you want built, and the model sees your UI, hears your explanation, and creates code. It's not a separate feature. It falls out naturally from the model seeing and hearing simultaneously, which is the whole premise of native multimodal pretraining.
Semantic Interruption
Earlier voice models struggled to distinguish a user actually wanting to cut in from background noise - a car passing, a coworker talking nearby. Qwen3.5-Omni-Plus adds turn-taking intent recognition that tries to separate meaningful interruptions from ambient signal. How well it holds up in noisy real-world environments is something users will have to test, but the architecture at least accounts for it.
Voice Cloning and Control
The model supports custom voice creation from short audio samples and exposes controls for speed, volume, and emotion. On the Seed-zh custom voice stability benchmark (lower is better), the Plus variant scores 1.07 - ahead of ElevenLabs (13.08), Gemini 2.5 Pro (2.42), GPT-Audio (1.11), and Minimax (1.19).
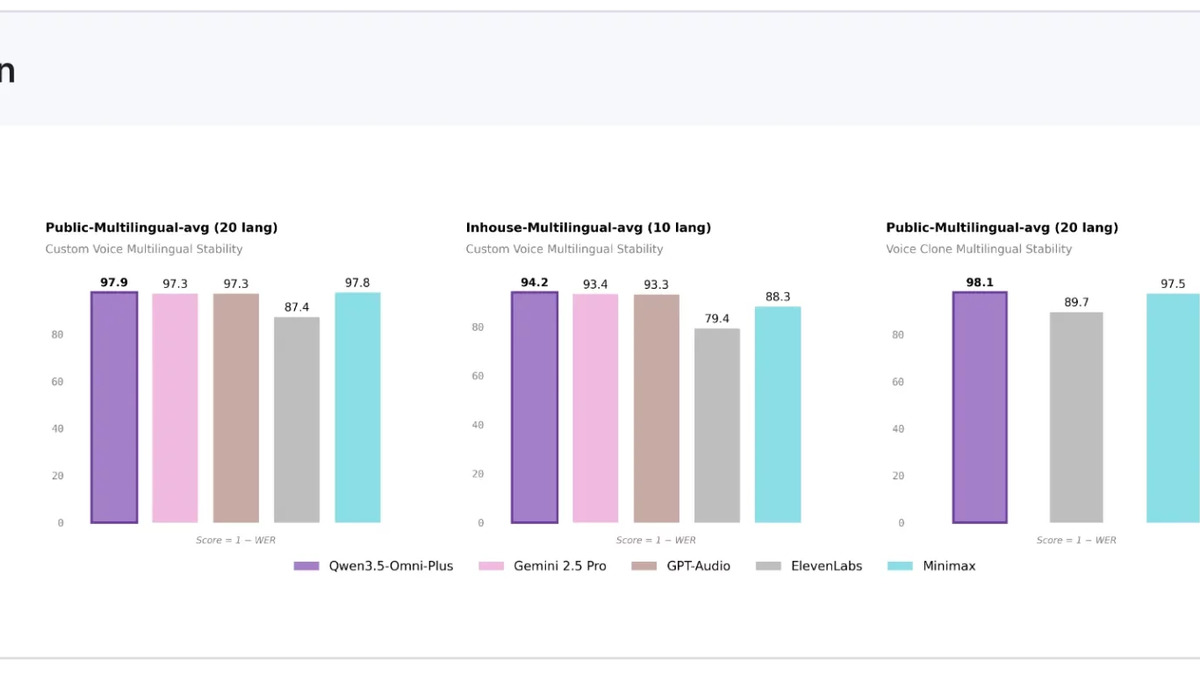 Speech generation benchmark comparisons. Seed-zh voice stability score: lower values point to better stability.
Source: analyticsvidhya.com
Speech generation benchmark comparisons. Seed-zh voice stability score: lower values point to better stability.
Source: analyticsvidhya.com
Three Tiers, Three Use Cases
The family ships in Plus, Flash, and Light configurations.
Plus is the flagship. At roughly 30B parameters with ~3B active, it needs at least 40GB VRAM for comfortable inference. This is your research box, your multi-GPU deployment, your high-quality voice pipeline.
Flash trades some quality for latency - suited for real-time voice chat where the first-token latency matters more than maximum benchmark scores.
Light runs on smaller GPUs and targets mobile or edge scenarios. Based on third-party GGUF quantizations appearing on Hugging Face, the Light tier appears to be in the sub-2B parameter range - comparable to what Qwen3-Omni's predecessor enabled on consumer hardware.
How to Access It
The primary API is DashScope (Alibaba Cloud's model service), with model IDs following the qwen3.5-omni-[variant] pattern. A WebSocket realtime API handles live audio and video streams. Model weights are available for self-hosting on Hugging Face.
 The Qwen Chat interface demonstrating multimodal input and real-time voice response with Qwen3.5-Omni.
Source: analyticsvidhya.com
The Qwen Chat interface demonstrating multimodal input and real-time voice response with Qwen3.5-Omni.
Source: analyticsvidhya.com
What To Watch
The 215 SOTA claim deserves some skepticism. Benchmark scope varies widely - a model can claim hundreds of SOTA results by including niche tasks where competition is thin. The numbers that are directly comparable to Gemini 3.1 Pro and GPT-Audio are more meaningful than the headline count.
Apache 2.0 licensing is confirmed through released weights, but the Plus variant's compute requirements (40GB+ VRAM) put self-hosting out of reach for most individual developers. Flash and Light are where practical on-device deployments will happen, and detailed specs for those tiers aren't published.
The LG EXAONE 4.5 release this week shows how much open-weight vision-language models have moved in 2026. Qwen3.5-Omni extends that competition into audio - a space where open models have historically lagged closed ones. The combination of strong ASR numbers, voice cloning, and native multimodal reasoning in a single Apache 2.0 model is genuinely new territory.
For teams running voice agents, the realtime WebSocket API and semantic interruption handling are worth assessing. Compared to stitching together a separate ASR model, a language model, and a TTS system, the latency savings and context continuity should be real - if the stability holds in production.
Sources:

