Qwen 3.5 Medium Series Drops Four Models That Make the 235B Flagship Obsolete
Alibaba releases four Qwen 3.5 medium models - Flash, 35B-A3B, 122B-A10B, and 27B - that match or beat the previous 235B flagship at a fraction of the compute. The 35B model activates just 3 billion parameters and still outperforms Qwen3-235B-A22B.
TL;DR
- Alibaba ships four Qwen 3.5 medium models: Flash (hosted API, 1M context), 35B-A3B, 122B-A10B, and 27B - all Apache 2.0 except Flash
- The 35B-A3B model activates only 3B parameters and surpasses both Qwen3-235B-A22B and Qwen3-VL-235B-A22B across benchmarks
- Flash costs $0.10/M input and $0.40/M output - roughly 25x cheaper than GPT-5-mini
- All models use Gated DeltaNet hybrid attention with native multimodal (text, image, video) and 256K-1M context
Ten days after dropping the 397B flagship that trades punches with GPT-5.2, Alibaba's Qwen team is now filling out the rest of the weight class. The Qwen 3.5 Medium Series puts four new models on the table, and the economics are the story here.
🚀 Introducing the Qwen 3.5 Medium Model Series
— Qwen (@Alibaba_Qwen) February 24, 2026
Qwen3.5-Flash · Qwen3.5-35B-A3B · Qwen3.5-122B-A10B · Qwen3.5-27B
✨ More intelligence, less compute.
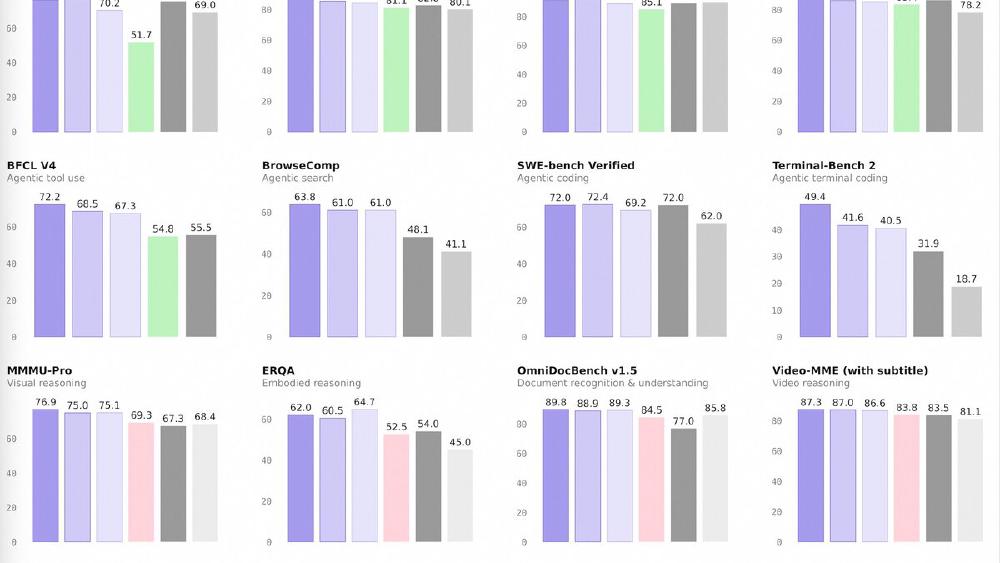
The headline number: a model with 35 billion total parameters and only 3 billion active per forward pass now beats the 235B model that was Qwen's flagship six months ago. That's not a marginal gain on one cherry-picked benchmark. It's a broad improvement across language, vision, coding, and agent tasks.
The lineup
| Model | Type | Total Params | Active Params | Context | License | API Price (Input/Output) |
|---|---|---|---|---|---|---|
| Qwen3.5-Flash | Hosted API | Not disclosed | Not disclosed | 1M tokens | Proprietary | $0.10 / $0.40 per M |
| Qwen3.5-35B-A3B | MoE | 35B | 3B | 262K (1M ext.) | Apache 2.0 | Self-host |
| Qwen3.5-122B-A10B | MoE | 122B | 10B | 262K (1M ext.) | Apache 2.0 | Self-host |
| Qwen3.5-27B | Dense | 27B | 27B (all) | 262K (1M ext.) | Apache 2.0 | Self-host |
All four share the same Gated DeltaNet architecture that powers the 397B flagship: a 3:1 hybrid of linear attention (DeltaNet) and full softmax attention layers, native multimodal training from the ground up, and 256-expert MoE routing for the sparse models. The 27B is the odd one out - a dense model with all parameters active, using standard FFN layers instead of expert routing.
The numbers that matter
The 35B-A3B model is the one that breaks brains. It activates 3 billion parameters - roughly the same compute budget as a small local model - and posts these scores:
| Benchmark | Qwen3.5-35B-A3B | Qwen3-235B-A22B | GPT-5-mini | Claude Sonnet 4.5 |
|---|---|---|---|---|
| MMLU-Pro | 85.3 | 84.4 | 83.7 | - |
| GPQA Diamond | 84.2 | 81.1 | 82.8 | - |
| HMMT Feb 25 | 89.0 | 85.1 | 89.2 | - |
| SWE-bench Verified | 69.2 | - | 72.0 | - |
| LiveCodeBench v6 | 74.6 | 75.1 | 80.5 | - |
| TAU2-Bench (Agent) | 81.2 | 58.5 | 69.8 | - |
| MMMU (Vision) | 81.4 | 80.6 | 79.0 | 79.6 |
| MathVision | 83.9 | 74.6 | 71.9 | 71.1 |
| ScreenSpot Pro | 68.6 | 62.0 | - | 36.2 |
The TAU2-Bench score - an agent task benchmark - is the standout. The 35B model scores 81.2 versus 58.5 for the previous 235B flagship. That's not a gap. That's a generation shift. On vision tasks, the medium models crush the previous vision-language flagship (Qwen3-VL-235B-A22B) across MMMU, MathVision, and ScreenSpot Pro.
The 122B-A10B and 27B dense models push even higher on most benchmarks, with the 27B posting the best SWE-bench Verified score of the trio at 72.4 - matching GPT-5-mini.
Flash: the production play
Qwen3.5-Flash is the commercial wrapper. It gets 1M context by default, built-in tool support, and Alibaba's standard tiered pricing. At $0.10 per million input tokens, it undercuts virtually every frontier API on the market. For comparison, DeepSeek V3.2 charges $0.14/$0.28 per million tokens, and GPT-5-mini runs $2.50/$10.00.
Counter-Argument
The obvious pushback: Alibaba's benchmarks are self-reported, and the AI industry has a well-documented habit of improving for eval suites. The SWE-bench and LiveCodeBench numbers for the 35B model trail GPT-5-mini, and the CodeForces rating of 2028 for the 35B is competitive but not dominant against frontier models scoring 2100+.
There's also the question of real-world deployment quality versus benchmark performance. A model with 256 experts routing to 8 active at inference can be sensitive to quantization, and the memory footprint for self-hosting the 122B model - even with only 10B active - is still sizable because the full weight matrix must remain in memory. The 35B-A3B is friendlier: at 3B active, it truly runs on consumer hardware with aggressive quantization, but how much quality survives 4-bit quant on a model this sparse remains to be confirmed by the community.
The Gated DeltaNet architecture is also new enough that framework support is still catching up. vLLM, SGLang, and TensorRT-LLM compatibility will determine whether these models are production-ready or research curiosities.
What the Market Is Missing
The real signal isn't that Alibaba shipped four decent medium models. It's what the 35B-A3B result implies about the cost curve.
If 3 billion active parameters can match what 22 billion active parameters did six months ago - and do it with native vision, 256K context, and agent capabilities - then the inference cost floor just dropped by roughly an order of magnitude. Every company running Qwen3-235B in production can now get the same or better output from a model that uses 7x less compute per token. Multiply that across millions of API calls and the savings aren't gradual. They're structural.
Alibaba isn't being subtle about what this means. The tagline is "more intelligence, less compute," and the 35B model is the proof point. When better architecture, data quality, and RL can replace raw parameter count, the economics of AI inference change - and every lab charging per-token margins on frontier models needs to recalculate.
Sources:
Last updated

