OpenAI Launches GPT-5.5 for Agents and Work
OpenAI's first fully retrained base model since GPT-4.5 ships today to ChatGPT and Codex, leading on Terminal-Bench 2.0 at 82.7% with a doubled per-token price.
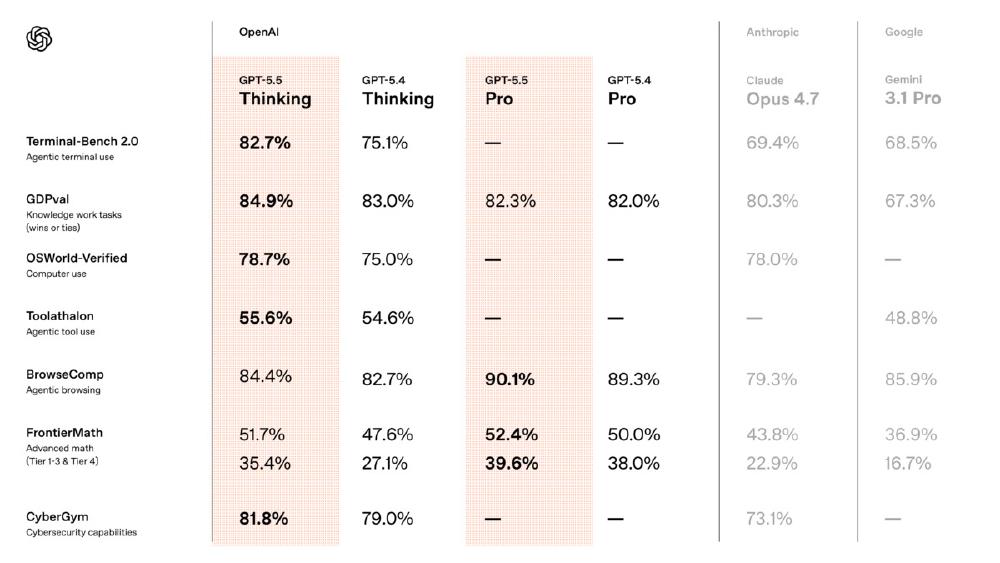
GPT-5.5, codenamed Spud internally, shipped today across ChatGPT and Codex. It's OpenAI's first completely retrained base model since GPT-4.5 - not a fine-tune, not a variant of a prior checkpoint. Rolling out right now to Plus, Pro, Business, and Enterprise subscribers with no waitlist. The API comes later, pending a separate safety review. Greg Brockman, OpenAI President, called it "a new class of intelligence." The benchmark data is specific enough to check that claim against.
TL;DR
- First complete retraining since GPT-4.5; natively omnimodal from the base (text, image, audio, video)
- Leads Terminal-Bench 2.0 at 82.7%, ahead of Claude Mythos Preview; 73.1% on Expert-SWE (internal coding eval)
- $5/$30 per million input/output tokens - double GPT-5.4's price, but OpenAI says fewer tokens per task offset the increase for agentic work
- No API access at launch; no MMLU-Pro or Chatbot Arena scores; architecture undisclosed
GPT-5.5 vs GPT-5.4: The Core Numbers
| Benchmark | GPT-5.5 | GPT-5.4 | Change |
|---|---|---|---|
| Terminal-Bench 2.0 | 82.7% | 75.1% | +7.6 pts |
| Expert-SWE (internal) | 73.1% | 68.5% | +4.6 pts |
| SWE-Bench Pro | 58.6% | ~55% est. | ~+3.6 pts |
| GDPval (44 occupations) | 84.9% | Not reported | - |
| OSWorld-Verified | 78.7% | Not reported | - |
| GeneBench | 25.0% | 19.0% | +6 pts |
| BixBench | 80.5% | Not reported | - |
| Input price | $5.00/M | $2.50/M | 2x |
| Output price | $30.00/M | $15.00/M | 2x |
Cross-reference: the coding benchmarks leaderboard and SWE-Bench coding agent leaderboard will reflect these scores as third-party evaluations build up.
What Changed in the Retraining
A new base, not a better fine-tune
GPT-5.1 through 5.4 were variants of existing checkpoints. GPT-5.5 was trained from scratch on NVIDIA GB200 and GB300 NVL72 rack-scale systems - the same hardware class running at the data-center scale OpenAI has been building out over the past year. That matters because the model's behavior in long agentic sessions reflects decisions made at the base training level, not patch-applied later.
OpenAI says the result is a model that "plans independently, selects and uses tools, checks its own work, and navigates ambiguity without constant human re-direction." These aren't novel capabilities, but the quality on the benchmarks they've published is measurably better.
Native omnimodality
The natively omnimodal architecture - text, image, audio, and video baked in from training rather than stitched together afterward - follows OpenAI's reported shift away from the multi-model composition approach that characterized earlier ChatGPT releases. In practice, this means the model processes different input types through the same unified learned representations, which tends to improve coherence on tasks that mix modalities.
Token efficiency as the pricing argument
OpenAI's pricing logic rests on one claim: GPT-5.5 uses significantly fewer tokens to complete the same Codex tasks as GPT-5.4. At double the per-token price, they need roughly 50% fewer tokens per task to break even on cost. Whether that holds at scale is the part that needs independent verification - the efficiency data comes completely from OpenAI's internal evals, and no methodology was published with the announcement.
Benchmark Breakdown
The coding results
Terminal-Bench 2.0 is the number that carries the most weight here. The benchmark tests complex command-line workflows: planning sequences of shell commands, coordinating multiple tools, debugging iteratively. At 82.7%, GPT-5.5 leads the field, narrowly ahead of Anthropic's Claude Mythos Preview. The Expert-SWE jump (68.5% to 73.1%) and SWE-Bench Pro result (58.6%) reinforce that coding is where the retraining made concrete gains.
OpenAI demonstrated a math professor using GPT-5.5 and Codex to build an algebraic geometry app from a single prompt in 11 minutes. That's a controlled demo, not a reproducible benchmark - but it gives a rough intuition for the task scale the model handles without hand-holding.
The GDPval question
GDPval is the number OpenAI will use in enterprise conversations. At 84.9%, it claims the model beats or matches human workers on roughly 85% of benchmarked tasks across 44 occupations in the top 9 U.S. GDP industries: finance, healthcare, law, engineering, and others. Bank of New York CIO Leigh-Ann Russell's quote about "hallucination resistance" appeared in OpenAI's press materials - meaning it was solicited, not independently obtained.
The benchmark is purpose-built and hasn't been independently replicated. Whether it translates to actual productivity gains in production deployments is a different question from whether a model scores well on a structured evaluation.
 GPT-5.5 and GPT-5.5 Pro appeared in Codex's model picker before the official announcement, confirming the launch timing.
Source: piunikaweb.com
GPT-5.5 and GPT-5.5 Pro appeared in Codex's model picker before the official announcement, confirming the launch timing.
Source: piunikaweb.com
Scientific research - early and limited
GeneBench at 25.0% is the headline for research applications, up from 19.0% on GPT-5.4. That's a 31% relative improvement. The benchmark involves multi-stage data analysis pipelines in genetics where models must reason about ambiguous or errorful experimental data. A 25% absolute score means GPT-5.5 still fails on three-quarters of the tasks. OpenAI's framing is "early scientific research support" - that word early is accurate.
BixBench at 80.5% covers real-world bioinformatics and data analysis tasks, which is much more tractable territory than the genetics benchmark.
Pricing and What the API Delay Means
| Tier | Input | Cached Input | Output |
|---|---|---|---|
| GPT-5.5 | $5.00/M | $0.50/M | $30.00/M |
| GPT-5.5 Pro | $30.00/M | - | $180.00/M |
| GPT-5.4 (reference) | $2.50/M | $0.25/M | $15.00/M |
The token efficiency argument matters only for agentic workloads where the model's ability to complete tasks in fewer tokens actually kicks in. For short, discrete prompts - summarization, classification, retrieval - the per-token price increase doesn't get offset. GPT-5.4 stays cheaper there.
GPT-5.5 Pro at $30/$180 per million tokens is a high-accuracy variant for the cases where Pro subscribers need maximum reliability. The cost efficiency leaderboard will track how these pricing tiers perform against alternatives as more data comes in.
The API delay is remarkable. OpenAI said: "API deployments require different safeguards" and that they're "working closely with partners and customers on the safety and security requirements for serving it at scale." No date was given. For teams that rely on direct API integration - not ChatGPT or Codex - GPT-5.5 isn't actually available yet.
 Codex with GPT-5.5 creating a website from a natural-language description - one of the demos OpenAI showcased at launch.
Source: piunikaweb.com
Codex with GPT-5.5 creating a website from a natural-language description - one of the demos OpenAI showcased at launch.
Source: piunikaweb.com
What It Does Not Tell You
Standard academic benchmarks are absent. No MMLU-Pro, no GPQA Diamond, no Chatbot Arena ranking. OpenAI's stated rationale is that those tests don't reflect what GPT-5.5 is built for. That's partially right - a model optimized for multi-step agentic work shouldn't be judged completely on static QA benchmarks. But the absence also means there's no third-party positioning yet.
Architecture is undisclosed. Parameter count, training data composition, and the specific token efficiency figures - how many tokens fewer GPT-5.5 uses per completed task versus GPT-5.4 - weren't published. The cost argument depends on that last number, and right now it's unverifiable.
The context window in Codex is 400K tokens, not the 1M available through the Chat API. For GPT-5.5, that's a step back from what GPT-5.4 supported in Codex. Very long sessions - large codebase analysis, extended research tasks - hit the ceiling sooner.
"GPT-5.5's capabilities feel like they're setting the foundation for how we're going to do computer work going forward, or how agent computing at scale will work." - Greg Brockman, OpenAI President
GPT-5.5 is a real step forward on the benchmarks OpenAI cares about. The Terminal-Bench 2.0 lead and the SWE-Bench Pro result are specific numbers on specific evaluations, not vendor narrative. The missing data - no API access date, no academic benchmarks, no token efficiency methodology - fills in as third-party evals arrive over the coming weeks. The model card at /models/gpt-5-5/ has the full specification breakdown.
Sources:
