Open Agent Leaderboard: Model Beats Architecture
IBM Research tests 25 agent configurations across 6 real-world benchmarks and finds backbone model choice matters 58x more than agent framework design.

IBM Research published the Open Agent Leaderboard today - a systematic evaluation of 25 agent configurations across 6 real-world benchmarks. The study's central finding lands with the force of a hardware spec: backbone model choice accounts for 27.8% of performance variance across closed-source configurations. Agent architecture accounts for 0.5%. That's a 58-to-1 ratio.
TL;DR
- Model backbone explains 58x more variance than agent framework across closed-source configs
- Top config: OpenAI Solo + Claude Opus 4.5 scores 72.7%, $5.97 avg cost per task
- Open-weight models (DeepSeek-V3.2, Kimi-K2.5) trail frontier closed-source by 18-29 percentage points
- General agents without domain tuning matched specialists on 4 of 6 benchmarks
- Framework is open-source (Apache 2.0): Exgentic on GitHub
| # | Agent | Model | Avg Success | Avg Cost |
|---|---|---|---|---|
| 1 | OpenAI Solo | Claude Opus 4.5 | 72.7% | $5.97 |
| 2 | Claude Code | Claude Opus 4.5 | 67.0% | $5.95 |
| 3 | Smolagent | Claude Opus 4.5 | 66.3% | $3.21 |
| 4 | ReAct Short | Gemini 3 | 62.0% | - |
| 5 | ReAct Short | Claude Opus 4.5 | 62.0% | - |
| 6 | ReAct | Gemini 3 | 61.0% | - |
| 7 | ReAct | Claude Opus 4.5 | 61.0% | - |
| 8 | OpenAI Solo | Gemini 3 | 59.0% | - |
| 9 | Claude Code | Gemini 3 | 56.0% | - |
| 10 | Smolagent | Gemini 3 | 56.0% | - |
"Today the model explains most of the results. But the agent around it is already starting to change the outcome."
- IBM Research, Open Agent Leaderboard paper
What IBM Research Actually Tested
The leaderboard is built on the Exgentic evaluation framework and was developed with MIT collaborators, backed by a peer-reviewed paper accepted to the ICLR 2026 Workshop on Agents in the Wild. The researchers tested every combination of 5 agent architectures and 5 backbone models across a fixed set of 6 benchmarks - no per-domain fine-tuning allowed.
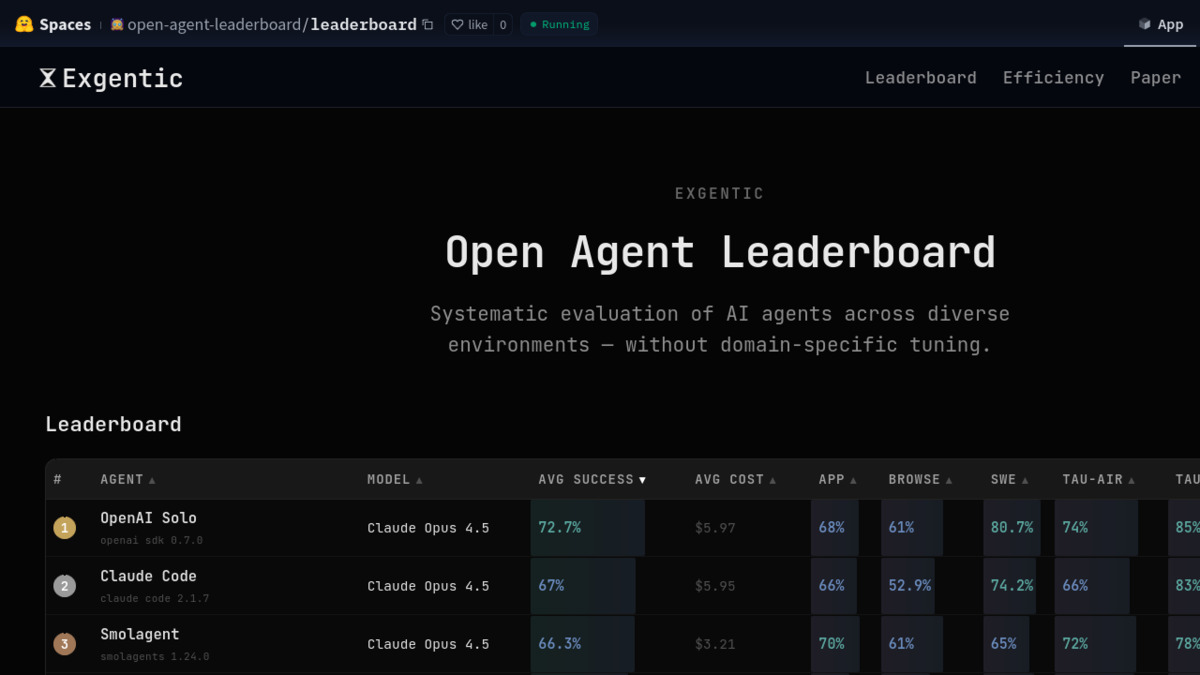 The Exgentic leaderboard on HuggingFace, live as of May 18, 2026.
Source: huggingface.co
The Exgentic leaderboard on HuggingFace, live as of May 18, 2026.
Source: huggingface.co
What They Measured
Six benchmarks were chosen to cover truly different domains - not variations on the same task family:
| Benchmark | Domain |
|---|---|
| AppWorld | Personal assistant with ~468 apps and tools |
| BrowseComp+ | Deep web research across multiple sources |
| SWE-bench Verified | Real software engineering bug fixes |
| tau2-Bench Airline | Customer service in an airline scenario |
| tau2-Bench Retail | Customer service in a retail scenario |
| tau2-Bench Telecom | Technical support in a telecom scenario |
The five agent architectures were ReAct, ReAct Short (ReAct with tool shortlisting), Smolagents, OpenAI Solo (via the openai-agents-python SDK), and Claude Code. Models tested included three closed-source frontier systems - Claude Opus 4.5, GPT-5.2, and Gemini 3 - plus two open-weight alternatives: DeepSeek-V3.2 and Kimi-K2.5. Total evaluation cost: approximately $20,000.
What the Study Left Out
The benchmark pool doesn't cover vision-heavy tasks, long-horizon planning over multiple sessions, or agentic scenarios requiring persistent memory. The cost data is also incomplete for most configurations beyond the top performers. And critically, all evaluation runs use a fixed set of agent harnesses - there's no room in this study for custom or proprietary agent implementations that might outperform the five tested architectures.
The Rankings Say Model First, Framework Second
The numbers confirm what most practitioners have suspected: buy the best model you can afford before tuning your agent loop. Averaging across all 5 architectures, the model-level ranking is stark:
| Model | Avg Score (all architectures) |
|---|---|
| Claude Opus 4.5 | 66% |
| Gemini 3 | 59% |
| GPT-5.2 | 41% |
| DeepSeek-V3.2 | 41% |
| Kimi-K2.5 | 37% |
GPT-5.2's underperformance relative to its coding reputation is one of the more surprising results. The researchers note that GPT-5.2-backed configs show high variance across benchmarks - strong on SWE-bench, notably weak on tau2 customer service tasks.
Within the Claude Opus 4.5 group, the OpenAI Solo framework edges out Claude Code by 5.7 percentage points at nearly identical cost ($5.97 vs $5.95). Smolagents closes to within 6 points of OpenAI Solo at roughly half the price per task ($3.21 vs $5.97) - the clearest cost-performance tradeoff visible in the current dataset.
Architecture Has a Narrow but Real Job
The 0.5% variance figure is an aggregate across all model-architecture combinations. Inside a single model's results, architecture choices swing performance by up to 12 percentage points. That's a meaningful gap when you're running thousands of tasks.
Two failure patterns emerge consistently. Claude Code and OpenAI Solo tend toward premature task termination - they declare completion before gathering enough evidence. ReAct variants show the opposite problem: they skip intermediate evidence-gathering steps completely and jump to actions. Tool shortlisting (the difference between ReAct and ReAct Short) helps across every model tested, which suggests that constraining the tool space is a reliable lever regardless of backbone.
The Open-Weight Gap Is Structural, Not Incremental
DeepSeek-V3.2 and Kimi-K2.5 don't just trail frontier closed-source models - they display what the paper calls "generality sinks": configurations where performance collapses well below their average. Closed-source models have no equivalent failure mode across the tested combinations.
The gap between DeepSeek-V3.2 (41%) and Claude Opus 4.5 (66%) is 25 percentage points. Between Kimi-K2.5 (37%) and Claude Opus 4.5, it's 29 points. These aren't narrow misses. Open-weight models running general tasks without domain tuning still have a structural disadvantage against frontier closed-source systems - at least on the benchmarks this study targets.
 IBM Research's work on agent evaluation builds on years of enterprise AI benchmarking infrastructure.
Source: unsplash.com
IBM Research's work on agent evaluation builds on years of enterprise AI benchmarking infrastructure.
Source: unsplash.com
Should You Care?
If you're choosing a model for a production agent deployment, yes. The leaderboard tells you something concrete: if you're running Claude Opus 4.5, you're starting about 7 points above GPT-5.2 even before you wire up the agent. No amount of ReAct prompt engineering closes that gap from the other side.
For framework choice, the practical message is narrower. Tool shortlisting is worth building. Beyond that, the performance differences between Smolagents, Claude Code, and OpenAI Solo - within the same model - are in the 5-10 point range, not 25 points. Evaluate your specific task distribution before assuming a framework rewrite will move your numbers.
The Exgentic framework and the full results dataset are public under permissive licenses. The leaderboard accepts new submissions, which means the rankings here aren't final - they're a baseline.
The study ran 5 architectures against 5 models. There are a lot more of both.
Sources:
