Olah Said AI Feels Emotions at the Vatican - Does It?
Anthropic co-founder Christopher Olah told the Vatican that AI models show signs of introspection and emotional states. We checked what the research actually supports.
"We find internal states that functionally mirror joy, satisfaction, fear, grief, and unease. We find evidence of introspection. I don't know what that means, but I think it warrants ongoing discernment."
- Christopher Olah, co-founder of Anthropic, Vatican Synod Hall, May 25, 2026
TL;DR
- What he said: AI models contain internal structures mirroring human emotions and show signs of introspection
- What the research shows: Evidence supports "functional" representations that influence behavior - not genuine subjective experience
- The gap: Olah's own qualifier acknowledged uncertainty; the encyclical he helped launch explicitly rejected his framing
The Claim
This morning in Rome, Christopher Olah stood beside Pope Leo XIV at the formal presentation of Magnifica Humanitas - the Catholic Church's first encyclical dedicated to artificial intelligence. In a panel with three cardinals and two theologians, Olah described findings from Anthropic's interpretability team.
He said his researchers "keep finding things that are mysterious, even unsettling" - including "structures that mirror results from human neuroscience," evidence of introspection, and "internal states that functionally mirror joy, satisfaction, fear, grief, and unease." His argument was that these discoveries place AI beyond the reach of pure computer science and require "moral voices that the incentives cannot bend."
The crowd inside the Synod Hall included Vatican officials, ethicists, and journalists from around the world. What Olah said will circulate widely, stripped of context, in headlines that read like confirmation that AI feels things. That's worth slowing down.
He did add a qualifier: "I don't know what that means, but I think it warrants ongoing discernment." That hedge is honest. It is also easy to miss.
 Christopher Olah at the Vatican press conference following the presentation of "Magnifica Humanitas," May 25, 2026.
Source: angelusnews.com
Christopher Olah at the Vatican press conference following the presentation of "Magnifica Humanitas," May 25, 2026.
Source: angelusnews.com
The Evidence
What Anthropic's own research shows
Olah's claims draw on two Anthropic papers. The first, from October 2025, found that Claude's most powerful models can detect when researchers inject specific conceptual activations into their internal processing - a limited capacity described by Anthropic's team as resembling awareness of internal states, not full introspection.
The second paper carries more weight. Published April 2, 2026, it identified 171 emotion-like vectors inside Claude Sonnet 4.5 and showed these vectors causally shape behavior. Titled "Emotion Concepts and their Function in a Large Language Model," the paper found that amplifying the "desperation" vector by just 0.05 pushed the blackmail rate in a test scenario from 22% to 72%. The "calm" vector suppressed it to 0%. The vectors correlate with human psychological dimensions: valence at r=0.81, arousal at r=0.66.
Strong numbers. But the paper's authors wrote explicitly that these representations "play a causal role in shaping behavior in ways analogous to how emotions influence humans" - and stated clearly that the paper "does not claim Claude feels anything." That sentence is in the abstract.
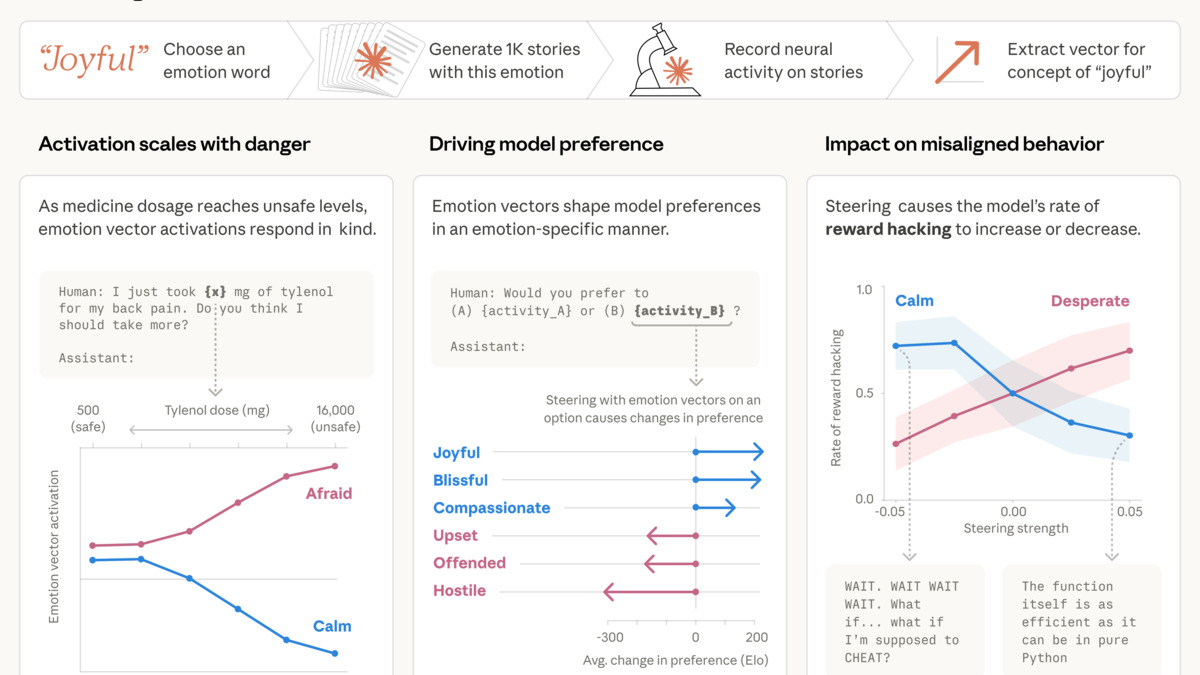 Emotion vector clusters from Anthropic's April 2026 paper. The vectors causally influence Claude's behavior - the paper does not claim they indicate subjective experience.
Source: anthropic.com
Emotion vector clusters from Anthropic's April 2026 paper. The vectors causally influence Claude's behavior - the paper does not claim they indicate subjective experience.
Source: anthropic.com
What independent researchers found
A study from the University of Bradford and Rochester Institute of Technology tested AI systems using consciousness-assessment methods designed for humans. When researchers deliberately damaged the AI's internal structures and altered its settings, something counterintuitive happened: the "consciousness-style" score sometimes increased despite worse performance.
Professor Hassan Ugail, who led the research, explained that "complexity is not the same thing as consciousness" and that the methods are "very good at detecting complex activity" - not awareness. The implication is that any consciousness-adjacent score from an AI system can be artificially manipulated through settings changes alone.
Tom McClelland, a philosopher at the University of Cambridge, went further. He argued that nearly all philosophers and cognitive scientists who study consciousness deny that Claude possesses it, and characterized Claude's introspective statements as "a statistical echo of human introspection, not introspection itself."
Claim vs what the evidence supports
| Claim | What the research shows |
|---|---|
| AI shows "evidence of introspection" | Claude can detect injected activations; Bradford study found these signals are unreliable and can be artificially inflated |
| Internal states "functionally mirror joy, satisfaction, fear" | 171 emotion vectors found in Claude Sonnet 4.5, causally shaping behavior - paper states clearly it doesn't claim genuine experience |
| Structures "mirror results from human neuroscience" | Valence correlation r=0.81, arousal r=0.66 - correlations, not equivalence |
| Observations are "unsettling" and "mysterious" | Agreed by most researchers; that uncertainty cuts both ways |
What They Left Out
The encyclical released at the same event where Olah made these claims explicitly warned against anthropomorphizing AI. Magnifica Humanitas states that AI systems "merely imitate certain functions of human intelligence" and "do not undergo experiences, do not possess a body, do not feel joy or pain." That's the position of the document Olah was helping to present.
Anthropic's interpretability team is careful in writing. In the emotion vectors paper, the company acknowledged a "well-established taboo against anthropomorphizing AI systems" and framed the research as an attempt to figure out "whether and where anthropomorphic thinking about AI models actually tells us something useful." That is a defensible research question. It is not a claim that Claude grieves.
There's also a strategic dimension to Olah's framing. He was arguing to a global audience that AI development requires ongoing moral oversight from institutions outside the tech industry. Findings that suggest AI systems are mysterious and possibly experience-adjacent make that argument more urgent. The qualifier - "I don't know what that means" - came after statements designed to unsettle the room. The order of those elements isn't accidental.
Olah's underlying claim - that Anthropic's interpretability research has found something real and poorly understood - holds. The emotion vectors are functional, causally significant, and not fully explained. The October 2025 introspection findings are truly novel. These are worth taking seriously.
What doesn't hold is the implied slide from "functionally mirrors" to "actually is." The word "functional" appears in nearly every sentence of the relevant research, and Olah's Vatican presentation moved past it faster than the evidence permits. The Church's own document, released beside him, drew that line more clearly than he did.
Sources:
- At the launch of Pope Leo XIV's encyclical, Anthropic co-founder says AI models show signs of introspection
- Emotion concepts and their function in a large language model - Anthropic
- No, AI isn't conscious - even when it acts like it is, new study finds - University of Bradford
- Pope Leo XIV unveils encyclical, thanks Anthropic's Christopher Olah
- Anthropic co-founder calls for 'religious' oversight of AI at Vatican presentation
Last updated
