NVIDIA Ships Vera CPU to Labs, Claims $200B Market
NVIDIA delivered first Vera CPUs to Anthropic, OpenAI, and SpaceX on May 17-19 as Q1 FY2027 earnings hit $81.6B, with $20B in standalone Vera CPU orders on the books for 2026.

NVIDIA posted $81.6 billion in revenue for Q1 FY2027 on May 20 - up 85% year-over-year - and guided Q2 to $91 billion. Neither of those numbers is the most interesting signal from the call. That distinction goes to CFO Colette Kress, who disclosed $20 billion in "visibility" for standalone Vera CPU sales in 2026, attached to what Jensen Huang described as "a brand new $200 billion TAM" the company has never addressed before.
Three days before the call, NVIDIA VP Ian Buck personally hand-delivered the first production Vera CPUs to Anthropic in San Francisco, OpenAI in Mission Bay, and SpaceX's AI team in Palo Alto - May 17, 18, and 19 respectively.
TL;DR
- First Vera CPUs delivered to Anthropic, OpenAI, and SpaceX on May 17-19, 2026
- Q1 FY2027 revenue: $81.6B, up 85% YoY; Q2 guided to $91B
- CFO disclosed $20B in standalone Vera CPU pipeline for 2026 - separate from bundled systems
- Jensen Huang claims Vera opens "a brand new $200B TAM" NVIDIA has never addressed
- 88 Olympus cores, 1.2 TB/s memory bandwidth, 22,500+ concurrent environments per rack
- Vera-Rubin bundled platform ships Q3 FY2027; standalone Vera already in production
What Vera Actually Does
The GTC announcement in March laid out the specs. This is where those specs connect to a specific workload problem.
Standard AI inference runs on GPUs. But an AI agent doesn't spend most of its compute budget doing matrix multiplication. It calls tools, waits on APIs, reads files, manages state, coordinates sub-agents, and routes between tasks. That work runs on CPUs - and most cloud CPUs were not designed for it. They were designed for web servers, databases, and virtual machines, where latency per thread and multi-tenant isolation matter more than raw memory bandwidth.
Vera is Arm-based (Olympus cores, Armv9.2 ISA) and built around one constraint that separates it from both its predecessor Grace and anything x86: it needs to keep Rubin GPUs fed at 22 TB/s. If the CPU managing context, tool state, and routing can't keep up, the GPU sits idle. The entire design follows from that requirement.
The Memory Architecture
The bandwidth gap is the clearest way to see what changed:
| CPU | Memory BW | Memory Capacity | CPU-GPU Link |
|---|---|---|---|
| NVIDIA Grace | 512 GB/s HBM3 | ~480 GB | 900 GB/s NVLink-C2C |
| Vera | 1.2 TB/s LPDDR5X | 1.5 TB | 1.8 TB/s NVLink-C2C (2nd gen) |
| Typical cloud x86 | 120-300 GB/s DDR5 | 192-768 GB | PCIe Gen 6 (~128 GB/s) |
The 1.8 TB/s CPU-GPU link is 14x faster than PCIe Gen 6. More to the point, it's coherent - the CPU can read GPU memory and the GPU can read CPU memory without explicit transfers. For agents passing multi-hundred-gigabyte KV caches between planning and execution steps, that coherence removes a latency floor that otherwise can't be engineered away in software.
The Concurrency Claim
NVIDIA says a rack of 256 Vera CPUs supports 22,500 concurrent independent environments at full performance. That number matters for multi-agent deployments. If you're running a system where thousands of agents are doing parallel web browsing and tool calls, you need a CPU substrate that isolates those environments cheaply. Vera's spatial multithreading physically partitions resources rather than time-slicing them, which is what enables that concurrency claim without performance degradation under load - at least according to NVIDIA's own benchmarks.
Under the Hood
The Core Design
88 Olympus cores per chip. 176 threads via spatial multithreading. 2 MB L2 per core, 164 MB L3. A single monolithic compute die - no chiplet architecture, which avoids cross-die NUMA latency penalties. First CPU with native FP8 precision support. Full confidential computing on silicon.
That last item isn't just a checkbox. For Anthropic and OpenAI, running inference where model weights and context are verifiably isolated at the hardware level is a requirement for some enterprise deployments - not a feature they can add later in software.
 Jensen Huang characterized Vera as opening a market NVIDIA has never previously addressed - the CPU-side orchestration layer of agentic AI systems.
Source: wikimedia.org
Jensen Huang characterized Vera as opening a market NVIDIA has never previously addressed - the CPU-side orchestration layer of agentic AI systems.
Source: wikimedia.org
Deployment Configuration
For infrastructure teams receiving the first standalone Vera units, the recommended path is vLLM or SGLang with tensor parallelism across the NVL72 rack. A minimal serving config targeting the full rack:
# Serve Llama-4-Maverick across a full Vera-Rubin NVL72
# 72 Rubin GPUs + 36 Vera CPUs, coherent memory shared over NVLink-C2C
vllm serve meta-llama/Llama-4-Maverick \
--tensor-parallel-size 72 \
--dtype fp8 \
--gpu-memory-utilization 0.95 \
--max-model-len 1048576 \
--port 8000
Vera CPUs handle routing, tool dispatch, and KV cache coordination. Rubin GPUs handle token generation. The division isn't enforced programmatically - the coherent interconnect makes the boundary transparent to software.
The Bundled vs. Standalone Split
Kress was clear on one point: the $20 billion in pipeline is for standalone Vera CPUs, not the full Vera-Rubin NVL72 system. The bundled platform - 72 Rubin GPUs and 36 Vera CPUs in a single all-to-all NVLink rack - doesn't ship until Q3 FY2027, with volume ramp in Q4.
What's shipping now goes to shops that already have GPU infrastructure and need an orchestration-layer upgrade. Oracle Cloud's Karan Batta committed to "hundreds of thousands" of Vera CPUs in 2026. Anthropic's head of compute James Bradbury called it "a promising part of the ecosystem when solving for agentic workloads" - diplomatically restrained, but still a public endorsement from the lab that runs some of the most demanding agent workloads in production.
 The standalone Vera CPU targets data centers that need an orchestration-layer upgrade without replacing existing GPU racks.
Source: wikimedia.org
The standalone Vera CPU targets data centers that need an orchestration-layer upgrade without replacing existing GPU racks.
Source: wikimedia.org
The $200B Number
Huang said Vera "opens a brand new $200 billion TAM for Nvidia, a market we have never addressed before." Jefferies analyst Janardan Menon put a timeline on it: his note characterized the $200 billion as a FY2031 (calendar 2030) market size for the agentic AI CPU segment, based on Arm's royalty trajectory and projected hyperscaler CPU share. That's a five-year forward number, not a 2026 figure.
Neither framing is inaccurate. The question is how durable NVIDIA's position in that market is. The Arm vs. Intel agentic CPU debate in April made clear both companies are chasing the same workload thesis - purpose-built silicon for orchestration-heavy AI. Vera's actual competitive moat is the NVLink-C2C interconnect: coherent CPU-GPU bandwidth that neither Arm's AGI CPU nor anything x86 can reproduce without NVIDIA's stack.
That moat holds as long as Rubin is the GPU of choice. A customer building on AMD MI400 or Gaudi doesn't benefit from NVLink-C2C. Vera's value proposition narrows significantly outside the NVIDIA ecosystem, which limits how much of the $200 billion TAM NVIDIA can actually capture regardless of how well the CPU itself performs.
The China exclusion in Q2 guidance is also a factor. NVIDIA said the $91 billion outlook assumes zero data center compute revenue from China. Any TAM projection that includes Chinese hyperscalers has a significant caveat embedded in it.
Where It Falls Short
Pricing for standalone Vera isn't disclosed. That makes the $20 billion figure impossible to sanity-check: at what per-unit price does $20 billion in pipeline make sense, and does it imply margin compression relative to GPU revenue? Without pricing, the number is a claim, not a model.
The 22,500 concurrent environments benchmark is NVIDIA's own. The workload conditions aren't published. Real agent deployments mix task types in ways that controlled benchmarks don't reflect, and the performance difference between sustained load and peak burst conditions on spatially partitioned hardware can be sizable.
The first deliveries are standalone Vera units - the headline coherent CPU-GPU architecture, the full NVL72 rack, doesn't ship at scale until late 2026. What Anthropic, OpenAI, and SpaceX received in May is an orchestration upgrade to existing infrastructure, not the integrated platform NVIDIA has been describing since March.
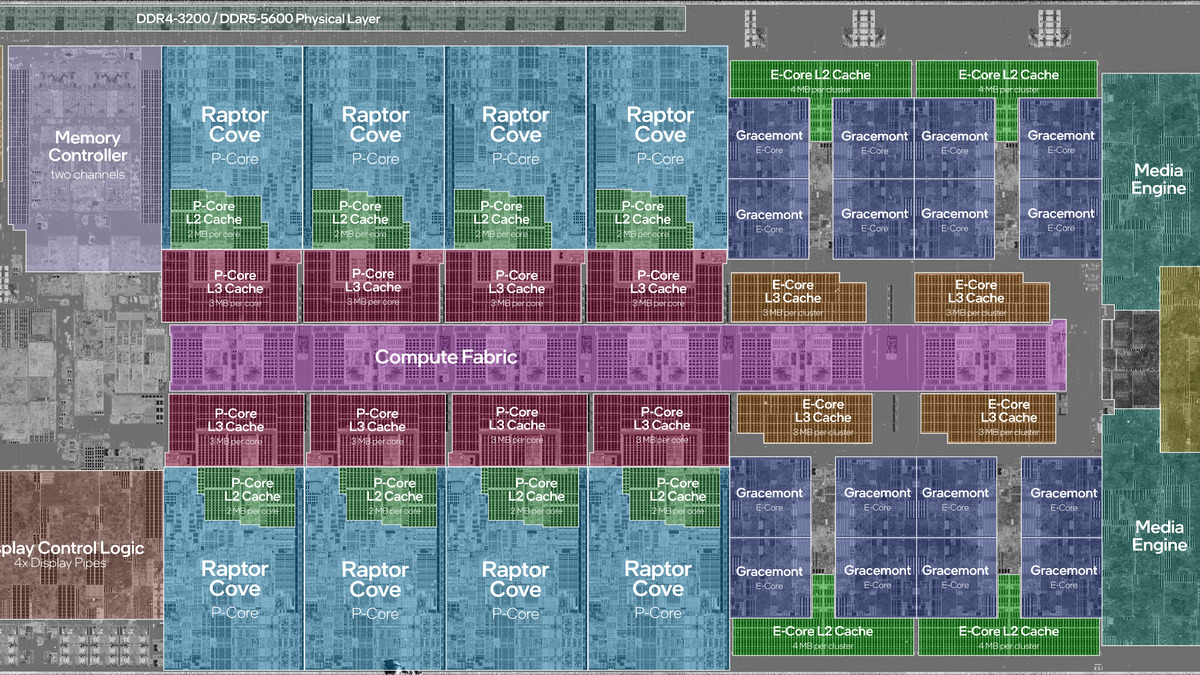 Vera uses a monolithic die - no chiplet boundaries - to remove cross-domain latency penalties that would otherwise bottleneck the CPU-GPU coherent memory path.
Source: wikimedia.org
Vera uses a monolithic die - no chiplet boundaries - to remove cross-domain latency penalties that would otherwise bottleneck the CPU-GPU coherent memory path.
Source: wikimedia.org
By the Numbers
Data center revenue for the quarter: $75.2 billion, up 92% year-over-year. NVIDIA's board authorized an additional $80 billion in share repurchases and raised the quarterly dividend from $0.01 to $0.25 per share - a 25x increase. The Q2 guidance of $91 billion assumes no Chinese data center compute revenue.
The standalone Vera CPU business is now an explicitly separate revenue line in NVIDIA's investor narrative. Whether $20 billion in 2026 pipeline becomes $20 billion in recognized revenue depends on deployment timelines at OCI, hyperscalers, and the other partners in the launch list. The $200 billion TAM is a 2030 projection. The first deliveries happened last week.
Sources:
