NVIDIA SANA-WM - Minute-Scale Video on One GPU
NVIDIA NVLabs open-sourced SANA-WM, a 2.6B-parameter world model that generates 60-second 720p camera-controlled video on a single GPU, outperforming 14B+ competitors that need 8 GPUs.

NVIDIA's NVLabs research group published SANA-WM on May 14, 2026 - a 2.6B-parameter world model that produces minute-long, 720p video following precise camera trajectories, and runs on a single GPU. That last part is the story.
Every competing open-source world model requires a rack of GPUs. SANA-WM does the same task on one H100, or one RTX 5090 for consumer settings, while posting better camera accuracy than models 4-5x its size running on 8 GPUs.
Key Specs
| Spec | Value |
|---|---|
| Parameters | 2.6B (main); 17B refiner |
| Output | 60-second, 720p (1280x720) |
| Camera control | 6-DoF arc |
| Hardware | Single H100 (51.1 GB) or RTX 5090 |
| Throughput | 22.0 videos/hour (with refiner) |
| License | Apache 2.0 (code); LTX-2 Community (refiner weights) |
| Code | github.com/NVlabs/Sana |
A Different Kind of Video Generator
SANA-WM isn't a text-to-video model. You don't describe a scene in words and get a clip back. You give it a starting image and a 6-DoF camera arc - rotation and translation across all three axes - and it synthesizes a spatially consistent video as the virtual camera moves through the scene.
The distinction matters for what it's designed to do. The team at NVLabs frames this explicitly as infrastructure for embodied AI: producing training environments for robot policies, synthetic data for autonomous driving, and navigable scenes for VR and AR. The model simulates a physical environment as a camera passes through it, not a creative montage responding to prompts.
Camera-Controlled Scene Generation
Where most image-to-video models treat the camera as a rough suggestion, SANA-WM uses a dual-branch system to encode camera movement at two levels of precision simultaneously.
The first branch - Ray-Local UCPE (Unified Camera Positional Encoding) - operates at the latent-frame level and captures the global structure of the camera's path across the whole clip. The second branch - Plücker Mixing - operates within each temporal stride and restores fine intra-stride motion details that the coarser branch misses.
Ablation results from the paper make clear both branches are contributing: dropping either one meaningfully increases camera motion consistency error. Using UCPE alone is actually worse than using neither, because the coarse signal misleads the model without the fine-detail correction.
 SANA-WM takes a single image and a camera arc as input and generates spatially consistent 60-second 720p video.
Source: nvlabs.github.io
SANA-WM takes a single image and a camera arc as input and generates spatially consistent 60-second 720p video.
Source: nvlabs.github.io
How the Architecture Works
The core model is a 2.6-billion-parameter Diffusion Transformer with an unusual design: 20 transformer blocks, but only 5 of them use standard softmax attention. The other 15 use Gated DeltaNet (GDN), a recurrent linear attention mechanism that processes entire latent frames per step.
Why Linear Attention at This Scale
The engineering trade-off is straightforward. Quadratic attention scales badly with sequence length, and 720p video at 60 seconds produces very long sequences. GDN keeps the computation linear while the model processes whole frames at a time, rather than individual tokens. Five periodic softmax blocks at fixed intervals with attention sinks and local temporal windows give the model a way to form long-range relationships that the recurrent blocks can't capture alone.
The team also wrote custom Triton kernels for GDN, RMSNorm, and key scaling that deliver a 1.5x to 2x efficiency gain over unoptimized implementations. Context-parallel training with prefix-sum composition and halo exchange for temporal convolutions handle the distributed training setup across 64 H100 GPUs.
A stability detail buried in the paper: the key scaling formula includes a stabilization term that keeps the trace of the recurrence matrix bounded. Without it, training diverges to NaN at step 1. Not a footnote - a load-bearing design decision.
The Refiner Stage
SANA-WM's second stage is a 17B refiner initialized from LTX-2, with rank-384 LoRA adapters on attention and feed-forward projections. It takes the main generator's output and corrects long-horizon quality drift using truncated-sigma flow matching and just 3 denoising steps.
The paper measures this directly: on hard trajectories, the quality degradation metric drops from 3.09 to 0.31 with the refiner applied. It's a cheap correction on top of the main generation pass, not a full second inference run.
Benchmark Performance
The evaluation covers 80 scenes across four categories - game, indoor, outdoor city, outdoor nature - with simple and hard camera path splits. Lower rotation error and camera motion consistency (CamMC) are better; higher VBench and throughput are better.
| Method | Params | GPUs | RotErr (deg) | CamMC | VBench | Throughput |
|---|---|---|---|---|---|---|
| SANA-WM + refiner | 2.6B+17B | 1 | 4.50 | 1.41 | 80.62 | 22.0 vid/hr |
| SANA-WM only | 2.6B | 1 | 7.59 | 1.63 | 79.29 | 24.1 vid/hr |
| LingBot-World | 14B+14B | 8 | 10.47 | 2.05 | 81.82 | 0.6 vid/hr |
| Matrix-Game 3.0 | 5B | 8 | 12.96 | 1.92 | 78.53 | 3.1 vid/hr |
| Infinite-World | 1.3B | 1 | 16.55 | 2.08 | 79.18 | 5.9 vid/hr |
| HY-WorldPlay | 8B | 8 | 17.89 | 2.45 | 68.82 | 1.1 vid/hr |
The throughput gap is the headline number: 22.0 versus 0.6 videos per hour for the largest competitor - 36x. LingBot-World has the highest VBench score (visual quality), but it also uses 11x more parameters on 8 GPUs and delivers camera accuracy that's more than twice as poor as SANA-WM.
Infinite-World is the closest in accessibility - also single-GPU, 1.3B parameters - but runs at 480p and has a rotation error of 16.55 degrees, roughly 3.7x worse than SANA-WM with the refiner.
What You Need to Run It
Three inference paths exist:
Full bidirectional generation (H100): 49.2 GB VRAM, standard server deployment.
Chunk-causal autoregressive (H100): 51.1 GB VRAM, more memory-efficient for streaming generation.
4-step distilled + NVFP4 quantization (RTX 5090): 34 seconds per 60-second 720p clip. Consumer-accessible, about 2.1x faster than real-time.
The RTX 5090 path represents the first time a model at this output quality level fits on consumer hardware. For context, the prior open-source benchmark leader NVIDIA Lyra 2.0 requires a 14B model weight on HuggingFace with a research-only license and produces similar camera-controlled output from a single photo - but SANA-WM covers the 60-second generation case that Lyra doesn't address.
Training the model required 64 H100 GPUs over roughly 18.5 days across four stages, using 212,975 video clips from sources including SpatialVID-HQ, MiraData, and DL3DV.
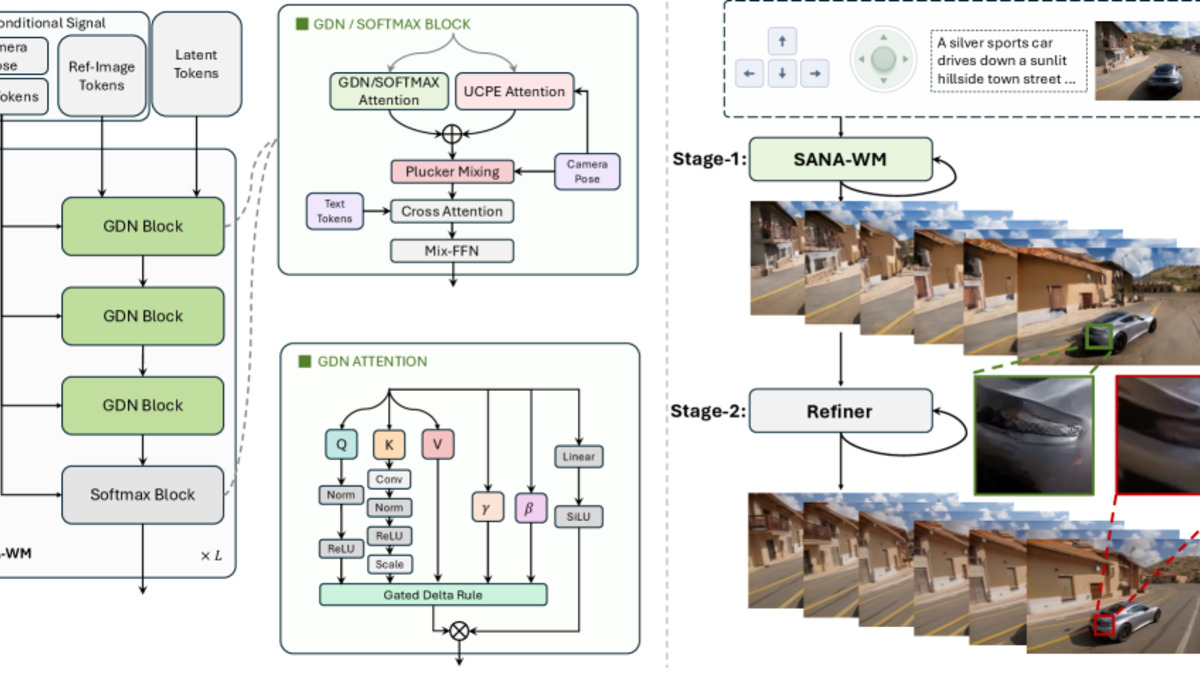 SANA-WM's pipeline: alternating GDN and softmax attention blocks process tokens, while UCPE and Plücker mixing encode the 6-DoF camera path at coarse and fine resolution simultaneously.
Source: arxiv.org/abs/2605.15178
SANA-WM's pipeline: alternating GDN and softmax attention blocks process tokens, while UCPE and Plücker mixing encode the 6-DoF camera path at coarse and fine resolution simultaneously.
Source: arxiv.org/abs/2605.15178
What It's Actually For
The direct applications the paper highlights: creating synthetic training environments for robot navigation policies, creating photorealistic data for autonomous driving systems, and building navigable scenes for AR and VR. World models are a growing research area - LeCun's group at AMI Labs has argued that world models are the path to general reasoning, and SANA-WM provides open infrastructure for the embodied AI side of that agenda.
The model doesn't have a text interface. It won't replace general video generation tools like Veo or Sora for creative work. It's a simulation engine dressed as a video model - the camera trajectory is the command, and the output is a traversable approximation of a 3D environment.
What To Watch
License complexity
The code is Apache 2.0, but the 17B refiner inherits the LTX-2 Community License from its base model. That limits commercial deployment. The arXiv page cites CC BY-NC-SA 4.0 while MarkTechPost reported Apache 2.0. Anyone building production pipelines should check the individual component licenses in the repo, not the summary descriptions.
Weight availability
At initial release, model weights on HuggingFace were listed as "coming soon" in the GitHub README. The code is available at github.com/NVlabs/Sana, and the project page is live at nvlabs.github.io/Sana/WM/, but practical deployment depends on weight availability through the Efficient-Large-Model HuggingFace organization.
Scene memory limits
The model has no explicit 3D scene memory. Revisit metrics - PSNR 14.46, SSIM 0.292 - reflect imperfect consistency when the camera returns to an earlier part of the scene. Dynamic scenes and rare viewpoints expose quality degradation. For use cases that require strict scene consistency across long trajectories, that's a real constraint, not a nit.
The paper describes future work including robot action controls and point tracking. Whether those extend SANA-WM or form a separate project is unclear. The research is out; the production infrastructure isn't yet.
Sources:
