Nemotron-Cascade 2: 30B Open MoE, One GPU, Beats 120B
NVIDIA's new Nemotron-Cascade-2-30B-A3B activates just 3B parameters per token, runs on a single RTX 4090, and outscores NVIDIA's own 120B model on coding and math benchmarks.

NVIDIA dropped Nemotron-Cascade-2-30B-A3B on March 20, and the efficiency numbers are worth paying attention to. The model has 30B total parameters but activates only 3B per token at inference - the same active compute as a mid-size dense model. It beats NVIDIA's own Nemotron-3-Super 120B on coding and instruction-following benchmarks while fitting into 24GB of VRAM with Q4 quantization. That's a single RTX 4090.
Key Specs
| Spec | Value |
|---|---|
| Total parameters | 30B |
| Active parameters / token | 3B |
| Architecture | Hybrid Mamba-Transformer MoE |
| Context window | 1M tokens |
| License | NVIDIA Open Model License |
| Ollama | Yes (24GB Q4_K_M variant) |
| HuggingFace | nvidia/Nemotron-Cascade-2-30B-A3B |
| AIME 2025 | 92.4 (98.6 with TIR) |
| LiveCodeBench v6 | 87.2 |
A Different Kind of MoE
Most open Mixture-of-Experts models trade inference cost for raw benchmark scores - you run a 671B model and pay for 37B of active compute per token. Nemotron-Cascade-2 goes further. The 30B total parameter footprint is itself modest by MoE standards, and the 3B active compute budget means it sits in the same inference bracket as Qwen3.5-35B-A3B, another 3B-active model that targets the same efficiency sweet spot.
The base architecture comes from the Nemotron 3 Nano 30B-A3B family - a hybrid design that mixes Mamba-2 state-space layers with standard Transformer attention layers. Mamba layers handle long-context token processing more efficiently than full attention, which helps explain how the 1M token context window is actually usable on consumer hardware rather than just listed in a spec sheet.
How Cascade RL Works
The model was trained using what NVIDIA calls Cascade RL - sequential reinforcement learning that moves through domains in stages. Instead of training on everything simultaneously and hoping the gradient updates balance out, Cascade RL trains one domain at a time, letting each stage build on the last. NVIDIA paired this with Multi-Domain On-Policy Distillation (MOPD), which pulls supervision from the strongest available teacher model in each domain during RL training. The dataset underneath is sizable: 1.9M Python reasoning traces, 1.3M Python tool-calling samples, 816K math proofs, and roughly 500K software engineering examples split between agentic and agentless approaches. Both the SFT and RL datasets are public on HuggingFace.
The model ships with a thinking mode that wraps chain-of-thought in <think> tags and an instruct mode for direct responses. Both run from the same set of weights.
 The Cascade RL training pipeline applies sequential domain-by-domain reinforcement learning. Each stage uses the strongest available teacher model for that domain.
Source: research.nvidia.com
The Cascade RL training pipeline applies sequential domain-by-domain reinforcement learning. Each stage uses the strongest available teacher model for that domain.
Source: research.nvidia.com
Benchmark Numbers
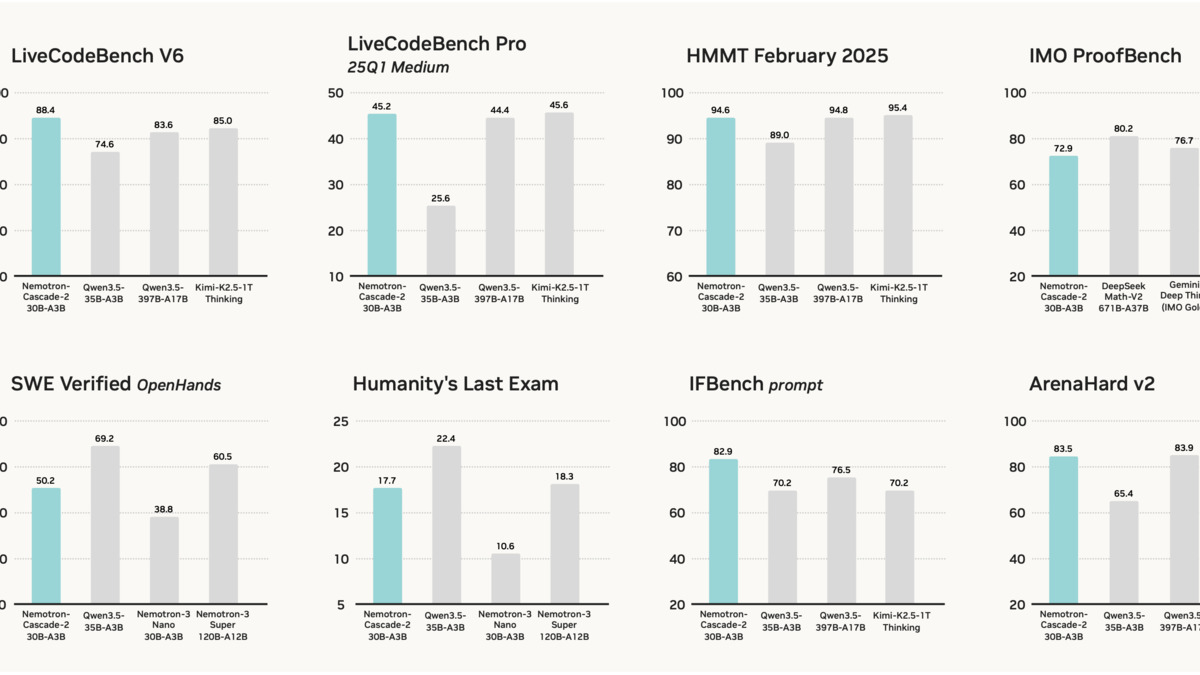
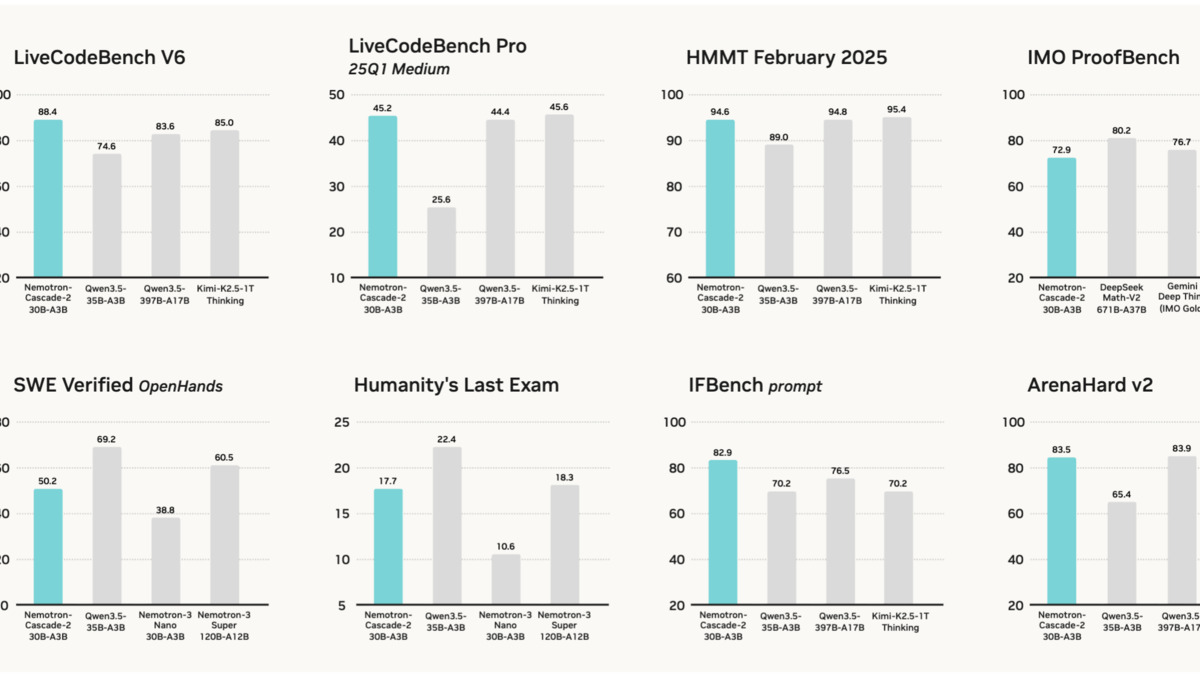
The comparison that stands out most is against NVIDIA's own 120B model. Nemotron-Cascade-2 beats Nemotron-3-Super on LiveCodeBench and instruction-following while using 4x fewer active parameters. The Qwen3.5-35B-A3B comparison is arguably more meaningful for most developers since the two models have identical active compute budgets - and the gap on coding and math is wide.
| Benchmark | Cascade-2 30B-A3B | Qwen3.5-35B-A3B | Difference |
|---|---|---|---|
| AIME 2025 | 92.4 | 91.9 | +0.5 |
| HMMT Feb 2025 | 94.6 | 89.0 | +5.6 |
| LiveCodeBench v6 | 87.2 | 74.6 | +12.6 |
| IOI 2025 | 439.3 | 348.6 | +90.7 |
| ArenaHard v2 | 83.5 | 65.4 | +18.1 |
| GPQA-Diamond | 76.1 | - | - |
| MMLU-Pro | 79.8 | - | - |
| IFBench | 82.9 | 70.2 | +12.7 |
The IOI and AIME scores stand out. NVIDIA claims Cascade-2 reaches gold medal-level performance at IMO 2025 (35 points), IOI 2025 (439.3 points), and ICPC World Finals 2025 (10/12 problems). The model card describes it as the second open-weight model to hit gold medal thresholds across all three competitions. The first is almost certainly one of the large DeepSeek variants, though NVIDIA doesn't name it. The AIME evaluation used avg@64 with a 131K token thinking budget, which is a generous setup - single-shot performance will be lower.
Tool-Integrated Reasoning (TIR) pushes the AIME score to 98.6 and LiveCodeBench to 88.4, which requires giving the model access to a Python interpreter during reasoning. Those numbers are impressive but not directly comparable to evaluations that don't use tool access.
 Benchmark comparison from the official model card. Cascade-2 holds its own across math, coding, and instruction-following against both open and proprietary models.
Source: huggingface.co
Benchmark comparison from the official model card. Cascade-2 holds its own across math, coding, and instruction-following against both open and proprietary models.
Source: huggingface.co
Reasoning vs. Instruct Mode
The thinking mode adds latency but moves AIME from whatever non-reasoning baseline exists up to 92.4. For time-critical workloads - chat, classification, document processing - the instruct mode runs faster and skips the chain-of-thought overhead completely. Both are the same model; it's a parameter at inference time, not a separate download.
Running It Yourself
Hardware Requirements
The Q4_K_M GGUF variant weighs 24.5GB and fits a single RTX 4090. Full BF16 precision requires roughly 63GB VRAM - two H100 80GB cards or better. The quantized path handles most dev and research workloads fine; you'd only need the full-precision weights if you're running evals that are sensitive to quantization noise or building something for production serving.
| Format | Size | GPU requirement |
|---|---|---|
| Q4_K_M GGUF | 24.5 GB | Single RTX 4090 or equivalent |
| Q5_K_M GGUF | 26.1 GB | Single H100 40GB+ |
| Q8_0 GGUF | 33.6 GB | Single H100 80GB |
| BF16 (full) | 63.2 GB | 2x H100 80GB or DGX |
Deployment Options
Ollama is the fastest path for local use: ollama run nemotron-cascade-2. The default Ollama variant uses Q4_K_M at 256K context. For full 1M context or custom serving, use GGUF weights directly in llama.cpp or LM Studio, or the official vLLM Docker image from NVIDIA for production deployments:
docker pull nvcr.io/nvidia/nemotron-cascade-2:latest
The model uses ChatML chat template format. Function calling, structured JSON output, and Fill-in-the-Middle are all supported. NVIDIA NIM containers are available on build.nvidia.com if you'd rather not handle serving infrastructure yourself.
 The H100 is the minimum recommended GPU for full-precision Nemotron-Cascade-2 serving. The Q4 GGUF variant runs on consumer RTX 4090 hardware.
Source: commons.wikimedia.org
The H100 is the minimum recommended GPU for full-precision Nemotron-Cascade-2 serving. The Q4 GGUF variant runs on consumer RTX 4090 hardware.
Source: commons.wikimedia.org
What To Watch
The license isn't Apache 2.0. The NVIDIA Open Model License is permissive - it allows commercial use, modification, and redistribution - but it's not the same as Apache 2.0. Organizations with strict open-source policies should review the exact terms before launching. The training datasets, by contrast, are under a separate permissive license and are fully public on HuggingFace.
The benchmark setup matters. The AIME avg@64 methodology gives the model 64 attempts per problem and takes the best result. That's useful for understanding ceiling performance but not representative of single-query production behavior. The LiveCodeBench numbers are more directly useful since they measure pass@1.
NVIDIA's self-interest is worth keeping in mind. Nemotron-Cascade-2 runs best on NVIDIA hardware. A model that fits a single RTX 4090 in Q4 but needs two H100s in full precision creates a clear path to NVIDIA NIM contracts for teams that outgrow local inference. The open-weight release is truly useful, and the efficiency engineering is real - but NVIDIA is also building its own ecosystem here.
The training data and RL code are public, which is more than most vendors release. If the efficiency gains from Cascade RL generalize to other architectures, that's a recipe worth studying regardless of where you run it.
Sources:

