NVIDIA Ships Nemotron 3 Ultra - 550B Open-Weight MoE
NVIDIA's 550B Nemotron 3 Ultra, released June 4, tops the US open-weight leaderboard with a hybrid Mamba-Transformer MoE architecture and 300-plus tokens per second throughput.

NVIDIA released Nemotron 3 Ultra on June 4, two days after Jensen Huang announced it at Computex in Taipei. At 550 billion total parameters, it's the largest open-weight model NVIDIA has shipped and, by Artificial Analysis's Intelligence Index, the best US open-weight model released to date.
Key Specs
| Spec | Value |
|---|---|
| Total parameters | ~550B (MoE) |
| Active parameters | ~55B per token |
| Context window | 262K tokens (BF16) / 1M tokens (NVFP4) |
| Training data | 20 trillion tokens |
| License | OpenMDW-1.1 |
| Inference speed | 300+ tokens/sec |
| Intelligence Index (AA) | 48 - best US open model |
| Available via | HuggingFace, OpenRouter, NVIDIA NIM |
Weights are on HuggingFace in both BF16 and NVFP4 formats. OpenRouter serves it at $0.50 per million input tokens, with a free tier also available.
Architecture
Nemotron 3 Ultra doesn't use a standard Transformer-only architecture. NVIDIA combined three design choices that each address a specific performance problem.
Hybrid Mamba-Transformer Layers
The model interleaves Mamba state-space layers with standard Transformer attention. Mamba handles long-context efficiency - it retains distant context without the quadratic cost of full attention. Transformer layers handle precise in-context fact retrieval. Neither alone would give you both properties at this scale.
LatentMoE Expert Routing
The Mixture-of-Experts routing uses what NVIDIA calls LatentMoE: a hardware-aware expert design that activates roughly 55 billion of the 550 billion parameters per token. That's 10:1 sparsity. The routing specializes experts by domain during training, which NVIDIA says produces better accuracy than naively balanced routing across domains.
Multi-Token Prediction
Ultra generates multiple tokens per forward pass rather than one at a time. This cuts wall-clock latency without changing benchmark scores. Combined with MoE sparsity, NVIDIA reports over 300 tokens per second on early DeepInfra endpoints - compared to 50-100 tokens per second for Chinese open models with higher benchmark scores.
 NVIDIA's Nemotron 3 Ultra, announced at Computex 2026 and released June 4. The 550B model targets multi-agent planning and long-context workloads.
Source: blogs.nvidia.com
NVIDIA's Nemotron 3 Ultra, announced at Computex 2026 and released June 4. The 550B model targets multi-agent planning and long-context workloads.
Source: blogs.nvidia.com
Training
NVIDIA trained Ultra on 20 trillion tokens using a technique called multi-teacher on-policy distillation. Rather than learning from a single teacher model, Ultra trained against ten or more domain-specific specialist models simultaneously. Each teacher provided dense feedback in its area during training. NVIDIA says this let the model develop gradually stronger specialization across domains over successive rounds.
The training data includes Nemotron-CC-v2.1 - 2.5 trillion English tokens from Common Crawl - along with code and supervised fine-tuning datasets. All training data and recipes are released with the weights.
NVFP4 on Blackwell
The NVFP4 variant requires NVIDIA Blackwell-class hardware but extends the context window from 262K to 1 million tokens and delivers five times the per-GPU throughput compared to BF16. For organizations with Blackwell access, that's the production target. BF16 works on H100-class hardware but needs multi-GPU setups - this isn't a single-card model.
Benchmarks
| Model | AA Intelligence Index | MMLU-Pro | GPQA Diamond | SWE-Bench Verified | Tokens/sec |
|---|---|---|---|---|---|
| Nemotron 3 Ultra (US open) | 48 | 86.8 | 87.0 | 65 - 70.4% | 300+ |
| Nemotron 3 Super (US open) | 36 | - | - | - | ~500+ |
| Kimi K2.6 (Chinese open) | 54 | - | - | - | ~50-100 |
| Claude Opus 4.8 (closed) | 61 | - | - | - | - |
The Intelligence Index of 48 places Ultra ahead of every other US-built open-weight model. China's Kimi K2.6 sits at 54 on the same index, and Anthropic's closed Claude Opus 4.8 reaches 61. Ultra isn't at the top globally, but it's the best you can download and self-host if you need US-origin open weights.
On agent-focused benchmarks, the numbers are stronger. PinchBench Agent Productivity: 90%. RULER at 1 million tokens (NVFP4): 94.7%. IFBench instruction following: 81.7%.
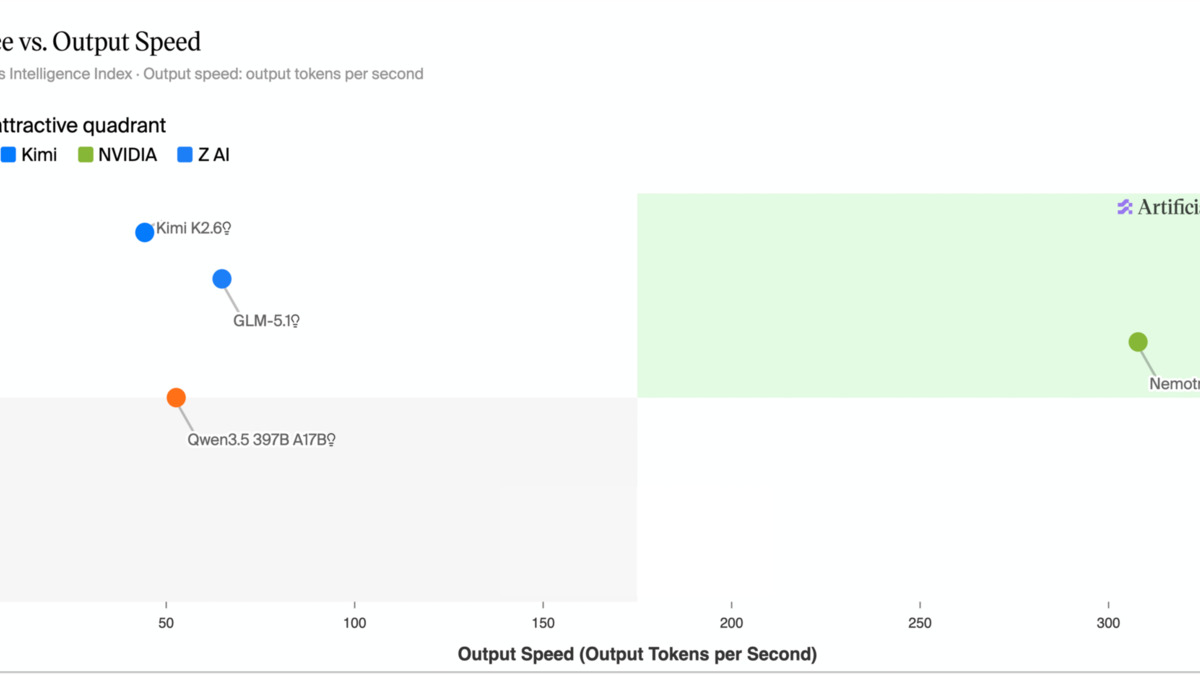 Artificial Analysis benchmark placement for Nemotron 3 Ultra. The model scores 48 on the Intelligence Index, the highest for any US-origin open-weight model.
Source: blogs.nvidia.com
Artificial Analysis benchmark placement for Nemotron 3 Ultra. The model scores 48 on the Intelligence Index, the highest for any US-origin open-weight model.
Source: blogs.nvidia.com
SWE-bench Verified results vary by agent scaffold. Using Pi, OpenHands, Hermes, OpenCode, and Mini SWE Agent, Ultra completed between 65% and 70.4% of tasks. In a real-world CodeRabbit evaluation, mean latency per full review trace was 7:06 versus an 8:31 baseline - about a 16% improvement. Check the SWE-bench coding agent leaderboard for independent comparisons as they accumulate.
Throughput as a Quality Proxy
Ultra's inference speed matters more than it first appears for agentic work. Kimi K2.6 scores 54 on the Intelligence Index compared to Ultra's 48, but runs at roughly 50-100 tokens per second through commercial APIs. Ultra at 300+ tokens per second closes much of that quality gap in real wall-clock time when a pipeline runs dozens of planning steps in sequence.
Where It Fits in the Family
NVIDIA's framing positions each Nemotron 3 size for a specific role in a multi-agent system. Nano handled perception and real-time responses. Super covered high-frequency execution tasks. Ultra handles complex long-horizon planning - synthesizing evidence across extended contexts and verifying multi-step constraints over a full agent run.
That maps to the benchmark profile. Ultra's strength on agent productivity tests and long-context retention reflects optimization for sustained reasoning over many tokens, not just peak single-turn response quality. If you're routing tasks in a multi-agent pipeline and need a model that holds context across a full planning cycle, Ultra's 262K-to-1M window is the main argument for choosing it over smaller models.
 Jensen Huang at the GTC Taipei keynote at Computex 2026, June 1, where he announced Nemotron 3 Ultra as the flagship of NVIDIA's open model family.
Source: blogs.nvidia.com
Jensen Huang at the GTC Taipei keynote at Computex 2026, June 1, where he announced Nemotron 3 Ultra as the flagship of NVIDIA's open model family.
Source: blogs.nvidia.com
License and Access
The OpenMDW-1.1 license is permissive and includes redistribution rights. Weights are available in FP8, BF16, and NVFP4 checkpoint formats on HuggingFace at nvidia/NVIDIA-Nemotron-3-Ultra-550B-A55B-BF16 and the NVFP4 variant. NVIDIA NIM microservices support direct cloud deployment, with third-party inference providers including DeepInfra, Fireworks, and Together AI already serving it.
For organizations assessing Ultra for production: API access through OpenRouter at $0.50 per million input tokens is the practical starting point. The free tier on OpenRouter works for evaluation. Self-hosting BF16 requires multi-GPU H100-class hardware. The full model card with pricing and deployment specs is at /models/nvidia-nemotron-3-ultra-550b/.
What To Watch
Ultra is NVIDIA's answer to whether a chip company can also produce the best open models. For US-origin open weights, the answer is now yes.
Three things to track from now on:
China's lead holds. Kimi K2.6 scores 54 on the Intelligence Index compared to Ultra's 48. Despite US export controls and NVIDIA's hardware advantage, the best open-weight model globally still comes from a Chinese lab.
The NVFP4 dependency. Ultra's 1M context window and 5x throughput improvement require Blackwell. Most H100 production clusters don't have it yet. Those performance numbers are real but locked behind a hardware upgrade cycle that most organizations haven't completed.
Independent benchmark verification. NVIDIA's agent productivity numbers (90% on PinchBench) come from NVIDIA's own evaluation infrastructure. Third-party verification on the same scaffolds isn't published yet. The SWE-bench range of 65-70.4% is plausible but wide, and depends heavily on which agent scaffold is used.
Sources:
