Nemotron 3 Nano Omni Unifies Vision, Audio, Language
NVIDIA's new open omni model activates 3B of 30B parameters, processes video, audio, and documents in one pass, and delivers up to 9.2x higher throughput than other open omni models.

On April 28, NVIDIA released Nemotron 3 Nano Omni, a 30B-A3B open model that processes text, images, audio, and video in a single inference pass. The interesting part isn't the modality count. It's the efficiency: on video and document workloads, NVIDIA's benchmarks show throughput gains of up to 9.2x over other open omni models at the same interactivity level, with only 3B parameters active per token.
Key Specs
| Spec | Value |
|---|---|
| Parameters | 30B total / 3B active (hybrid Mamba-MoE) |
| Context window | 256K tokens |
| Modalities | Text, images, audio (up to 20 min), video |
| Throughput gain | Up to 9.2x vs other open omni models |
| License | Open weights (NVIDIA) |
| Released | April 28, 2026 |
| Available on | HuggingFace, OpenRouter, 25+ platforms |
One Model, No Orchestration Tax
Most multimodal agent pipelines wire together separate models: one for vision, one for audio, one for language. That design works, but adds latency at every handoff and makes cross-modal context hard to maintain. When a document contains both a chart and an embedded audio annotation, a multi-model pipeline either drops one or runs two separate inference calls and merges the results manually.
Nemotron 3 Nano Omni takes a different approach. Vision tokens from C-RADIOv4-H, audio tokens from Parakeet-TDT-0.6B-v2, and text tokens all enter the same decoder in a single pass. Context from one modality is immediately visible to the others, which matters for tasks like "read this PDF and reconcile it against the meeting recording."
The efficiency argument
The model's 30B-A3B hybrid MoE means most of the 30B parameter count sits in inactive experts. Only 3B activate per token, which is why throughput holds up well at scale. NVIDIA's Efficient Video Sampling (EVS) layer additionally compresses high-density video tokens before they enter the context window, preventing frame-heavy inputs from blowing out the 256K token budget.
For teams running agents in production - processing hundreds of PDFs per hour, monitoring video feeds, or transcribing and summarizing call recordings - the 7.4x to 9.2x throughput multiplier isn't abstract. At equivalent inference cost, you're running roughly nine times as many concurrent jobs.
Architecture
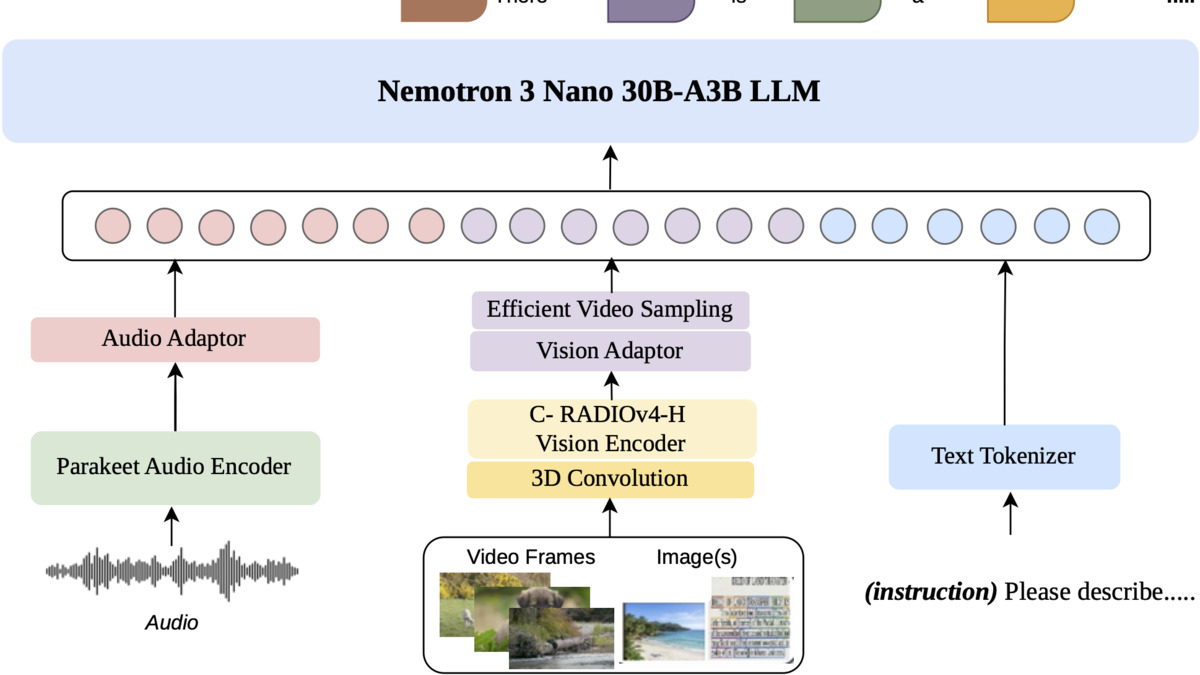 The Nano Omni architecture: C-RADIOv4-H for vision, Parakeet-TDT-0.6B-v2 for audio, and Nemotron 3 Nano as the shared language backbone. MLP projectors bridge each encoder to the token space.
Source: huggingface.co
The Nano Omni architecture: C-RADIOv4-H for vision, Parakeet-TDT-0.6B-v2 for audio, and Nemotron 3 Nano as the shared language backbone. MLP projectors bridge each encoder to the token space.
Source: huggingface.co
The backbone is Nemotron 3 Nano 30B-A3B: 23 Mamba selective state-space layers, 23 MoE layers (128 experts, top-6 routing per token), and 6 grouped-query attention layers. Two lightweight MLP projectors connect the encoder outputs to the shared embedding space.
Vision
The vision encoder is C-RADIOv4-H, which supports dynamic resolution up to 13,312 patches per image. For video, 3D convolutions capture temporal-spatial motion before the EVS layer compresses the token stream. Computer-use agents benefit directly: on OSWorld, which tests navigation of graphical interfaces, Nano Omni scores 47.4 - a significant jump from the previous Nano V2 VL's 11.0.
Audio
The audio encoder is Parakeet-TDT-0.6B-v2, NVIDIA's own ASR foundation. It handles up to 20 minutes of audio per request. On the HuggingFace Open ASR leaderboard, Nano Omni reaches a 5.95% word error rate, versus 6.55% for Qwen3-Omni 30B-A3B. Not a huge gap, but consistent.
Benchmark Results
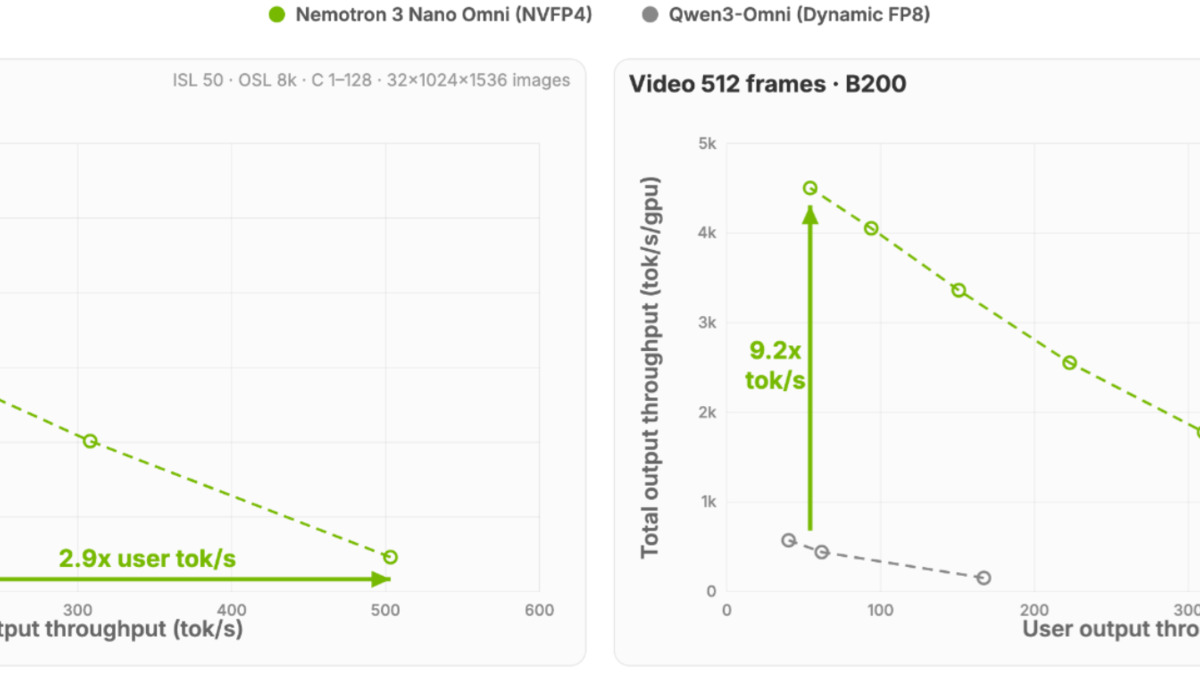 System throughput at a fixed first-token latency threshold. The Nano Omni's MoE architecture lets it process far more concurrent requests than dense open omni models.
Source: huggingface.co
System throughput at a fixed first-token latency threshold. The Nano Omni's MoE architecture lets it process far more concurrent requests than dense open omni models.
Source: huggingface.co
The table below puts Nano Omni next to Qwen3-Omni 30B-A3B (its closest parameter-class competitor) and NVIDIA's own previous Nano V2 VL (text-image only):
| Benchmark | Nano Omni | Qwen3-Omni 30B-A3B | Nano V2 VL |
|---|---|---|---|
| MMLongBench-Doc | 57.5 | 49.5 | 38.0 |
| OCRBenchV2-En | 65.8 | - | 61.2 |
| CharXiv reasoning | 63.6 | 61.1 | 41.3 |
| OSWorld (GUI agents) | 47.4 | 29.0 | 11.0 |
| ScreenSpot-Pro | 57.8 | 59.7 | 5.5 |
| Video-MME | 72.2 | 70.5 | 63.0 |
| WorldSense | 55.4 | 54.0 | - |
| DailyOmni | 74.1 | 73.6 | - |
| VoiceBench | 89.4 | 88.8 | - |
| HF Open ASR WER (lower is better) | 5.95 | 6.55 | - |
The OSWorld result is the most notable delta. Qwen scores 29.0; Nano Omni scores 47.4. GUI navigation is a genuine bottleneck for computer-use agents, so that 18-point gap has real product implications. ScreenSpot-Pro is the one area where Qwen holds a small edge (59.7 vs 57.8).
Independent results from Coactive's MediaPerf benchmark - run outside NVIDIA's labs - showed Nano Omni at 9.91 hours-of-video processed per hour on video tagging. That's about five times GPT 5.1's rate and six times Gemini 3.0 Pro's on the same task. Multi-document summarization tracked similarly.
Where It Runs
The model is available now across a broad set of inference surfaces:
- Full weights: Hugging Face under NVIDIA's open model license
- Hosted API: OpenRouter and build.nvidia.com as a NVIDIA NIM microservice
- Inference frameworks: vLLM, SGLang, TensorRT-LLM
- Local tools: Ollama, llama.cpp, LM Studio, Unsloth
- Cloud: AWS SageMaker, Oracle Cloud (Azure listed as coming soon)
- On-premises: Dell Technologies integration with NemoClaw privacy sandbox
- Edge: NVIDIA Jetson AI Lab for robotics
NVIDIA published the full training recipe, 124M post-training examples, 20 RL datasets spanning 25 environments, and 11.4M synthetic visual QA pairs. Fine-tuning for a specific domain - legal documents, medical imaging, security camera footage - is possible without asking NVIDIA for anything.
What To Watch
The 9x throughput figures assume NVFP4 quantization on Blackwell GPUs. On H100s, A100s, or consumer RTX cards you'll get the model's accuracy but not the headline throughput numbers. NVFP4 is a Blackwell-only format, so older hardware users should treat efficiency claims skeptically until they run their own benchmarks.
The Qwen3-Omni 30B-A3B comparison is closer than NVIDIA's marketing implies. On most tasks the gap is real but not decisive - single-digit benchmark points rather than a factor-of-two. Teams already launched on Qwen infrastructure won't find a compelling migration case unless cost-per-inference is an active problem.
The wider Nemotron 3 family is worth watching. Super at approximately 100B active parameters was originally scheduled for H1 2026; the Nano Omni launch contained no updated timeline for Super or Ultra. The Nemotron-Cascade-2 from March was the text-only efficiency story - Nano Omni is the same MoE foundation with vision and audio encoders added on top.
Sources:
