Nemotron 3 Nano 4B: NVIDIA Edge Model Runs on 8GB
NVIDIA's Nemotron 3 Nano 4B packs a Mamba-dominant hybrid architecture, 262K token context, and 95.4% on MATH500 into a model that fits an 8GB Jetson Orin Nano.

NVIDIA published Nemotron 3 Nano 4B on March 17, a 3.97-billion-parameter model built around a Mamba-2 hybrid architecture and compressed from the 9B Nemotron Nano v2 via structured pruning. It fits inside a 8GB Jetson Orin Nano, hits 95.4% on MATH500 in reasoning mode, and carries a commercial-permissive license. For teams running inference at the edge without a rack of H100s, that combination is worth looking at closely.
Key Specs
| Spec | Value |
|---|---|
| Parameters | 3.97B |
| Architecture | Mamba-2 + Transformer hybrid |
| Context window | 262K tokens |
| Quantization | BF16, FP8, GGUF (Q4_K_M) |
| Edge throughput | 18 tokens/sec on Jetson Orin Nano 8GB |
| MATH500 (reasoning-on) | 95.4% |
| AIME25 (reasoning-on) | 78.5 |
| License | NVIDIA Nemotron Open Model License |
| Inference engines | HF Transformers, vLLM, TRT-LLM, Llama.cpp |
What Makes the Architecture Unusual
Most 4B models are Transformer-only. Nemotron 3 Nano 4B isn't. Its 42 layers are divided into 21 Mamba layers, 4 attention layers, and 17 MLP layers. That's a 5:1 ratio of Mamba to attention - unusual enough that the model card flags it explicitly.
Why Mamba at This Scale
Mamba's selective state space design has a specific advantage at inference time: it doesn't grow a key-value cache the way Transformer attention does. For long contexts, this means memory stays flat instead of expanding linearly with sequence length. At 262K tokens, that matters more than it'd at a 4K or 8K window.
The tradeoff is that Mamba models can struggle with exact recall on long-range lookups compared to full attention. NVIDIA's answer is to keep four attention layers in the mix - enough to handle the recall-sensitive tasks while the Mamba layers handle the bulk of the context processing cheaply.
The Nemotron Elastic Pipeline
The 4B model wasn't trained from scratch. NVIDIA pruned it from the 9B Nemotron Nano v2 using a technique they call Nemotron Elastic - a structured pruning process followed by knowledge distillation. The training data runs to more than 10 trillion tokens with a knowledge cutoff of September 2024.
Structured pruning (removing whole neurons, attention heads, or layers rather than individual weights) is generally more hardware-friendly than unstructured sparsity, which requires special sparse kernels to see any speedup. The result can be run on standard dense inference stacks without modification.
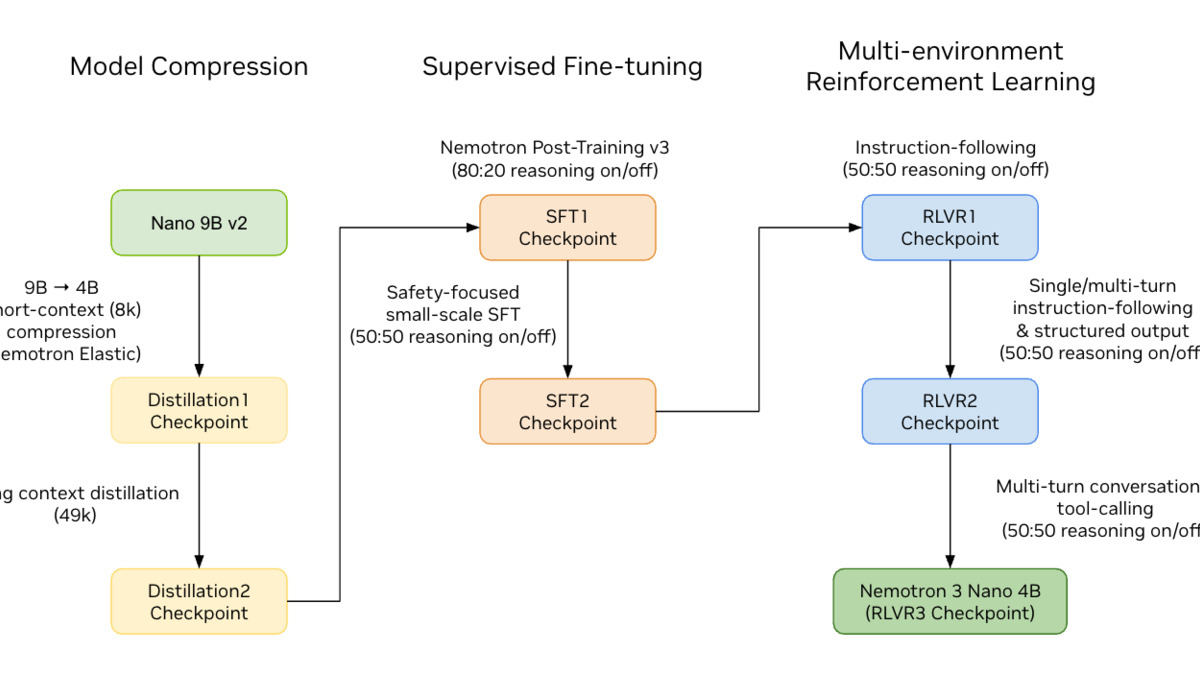 The Nemotron Elastic pipeline compresses the 9B v2 model to 4B via structured pruning and knowledge distillation, preserving most benchmark performance.
Source: huggingface.co
The Nemotron Elastic pipeline compresses the 9B v2 model to 4B via structured pruning and knowledge distillation, preserving most benchmark performance.
Source: huggingface.co
Benchmark Performance
The model ships with two operating modes: Reasoning-Off for standard generation and Reasoning-On for chain-of-thought tasks. NVIDIA reports these separately, which is the right call - collapsing them would obscure where the model is actually strong.
Instruction Following
In Reasoning-Off mode, Nemotron 3 Nano 4B scores 88.0 on IFEval-Instruction and 82.8 on IFEval-Prompt. In Reasoning-On mode, IFEval-Instruction climbs to 92.0. The IFBench scores (43.2 prompt, 44.2 instruction) are less impressive but IFBench is a harder test - these numbers are competitive for a 4B model.
Math and Reasoning
The headline numbers are in Reasoning-On mode: 95.4% on MATH500, 78.5 on AIME25, 53.2 on GPQA. MATH500 at 95.4% is genuinely strong at this parameter count - it puts the model in range of larger reasoning models on pure math. GPQA at 53.2 is more modest and reflects the limits of a 4B parameter budget on harder science reasoning.
| Benchmark | Reasoning-Off | Reasoning-On |
|---|---|---|
| MATH500 | - | 95.4% |
| AIME25 | - | 78.5 |
| GPQA | - | 53.2 |
| IFEval-Instruction | 88.0 | 92.0 |
| BFCL v3 | 61.1 | - |
| RULER (128K) | 91.1 | - |
| HaluEval | 62.2 | - |
RULER 91.1 at 128K context is the other number worth noting. Long-context retrieval benchmarks are where Mamba hybrids have historically struggled most - 91.1 isn't a red flag.
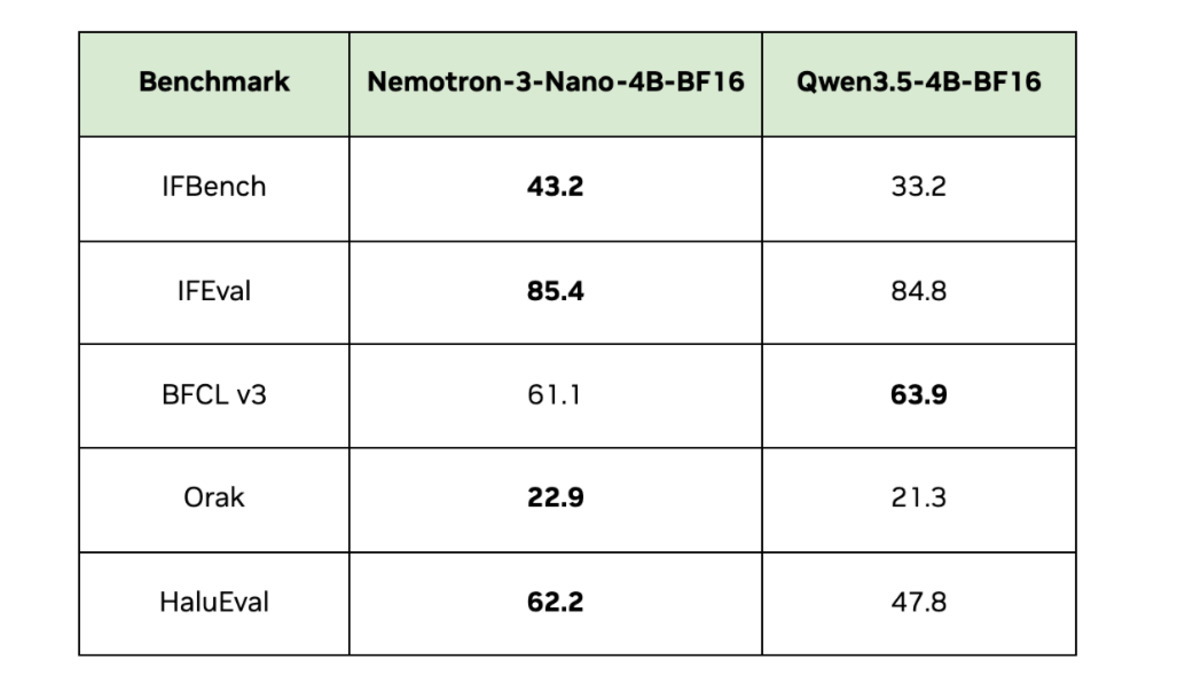 Official benchmark comparison across competing small models. Nemotron 3 Nano 4B leads on IFEval and reasoning tasks.
Source: huggingface.co
Official benchmark comparison across competing small models. Nemotron 3 Nano 4B leads on IFEval and reasoning tasks.
Source: huggingface.co
Hardware Requirements and Deployment
Edge Platforms
The model is designed for three NVIDIA edge tiers. On a Jetson Orin Nano 8GB running Q4_K_M quantization via Llama.cpp, it delivers 18 tokens/sec. That's twice the throughput of the Nemotron Nano 9B v2 on the same board - the compression works. Jetson Thor and DGX Spark are also supported; on those platforms, FP8 inference gives a 1.8x latency improvement over BF16. For teams using the DGX Spark as a local inference machine, our DGX Spark setup guide has the full environment walkthrough.
 The Jetson Orin Nano Super Developer Kit is the primary edge target. Q4_K_M quantization delivers 18 tokens/sec within its 8GB memory budget.
Source: nvidia.com
The Jetson Orin Nano Super Developer Kit is the primary edge target. Q4_K_M quantization delivers 18 tokens/sec within its 8GB memory budget.
Source: nvidia.com
Inference Engines
Four inference paths are supported out of the box: Hugging Face Transformers, vLLM, TensorRT-LLM, and Llama.cpp. That covers the main deployment stacks. If you're running local inference with Ollama or LM Studio, Llama.cpp compatibility means the GGUF file should work - our local LLM guide covers that setup path.
License
The model ships under the NVIDIA Nemotron Open Model License, which permits commercial use. This isn't Apache 2.0 or MIT - the NVIDIA license has its own terms, so check them before production deployment. For comparison, our small language model leaderboard tracks license types across the main sub-10B models.
What To Watch
The Mamba-heavy architecture is the genuine unknown here. Most of the models it competes with at the 4B range - Phi-4 Mini, Gemma 3 4B, Qwen 3.5 4B - are Transformer-only. NVIDIA's claim that 91.1 RULER at 128K is competitive is plausible on paper, but long-context retrieval benchmarks are sensitive to how tasks are structured. Independent evals on recall-heavy tasks will tell more than the official numbers.
The other variable is the license. "Commercial use permitted" under NVIDIA's Nemotron license is different from a true open license. Teams building products on this should read the terms before assuming it's a drop-in replacement for Apache-licensed models in their stack.
On performance per watt and tokens-per-second-per-dollar at the edge, Nemotron 3 Nano 4B looks truly competitive. Whether the Mamba architecture holds up under adversarial long-context workloads is the question that'll determine how seriously the open-source community builds around it.
Sources:

