NVIDIA Lyra 2.0 - Explorable 3D Worlds from One Photo
NVIDIA's Spatial Intelligence Lab released Lyra 2.0, a 14B model that turns a single photograph into a navigable 3D environment - but the weights carry a research-only license.

NVIDIA's Spatial Intelligence Lab published Lyra 2.0 on April 14, 2026. Feed it a single photo, define a camera path, and it creates a spatially consistent walkthrough video of the scene - then lifts that video into 3D Gaussian splats and surface meshes you can export directly into physics engines.
One photo in. Navigable 3D world out.
The source code is on GitHub under Apache 2.0. The model weights, available on HuggingFace, carry NVIDIA's Internal Scientific Research and Development License - research and development use only, no deployment, no commercial use.
That distinction matters more than NVIDIA's press language suggests.
How It Works
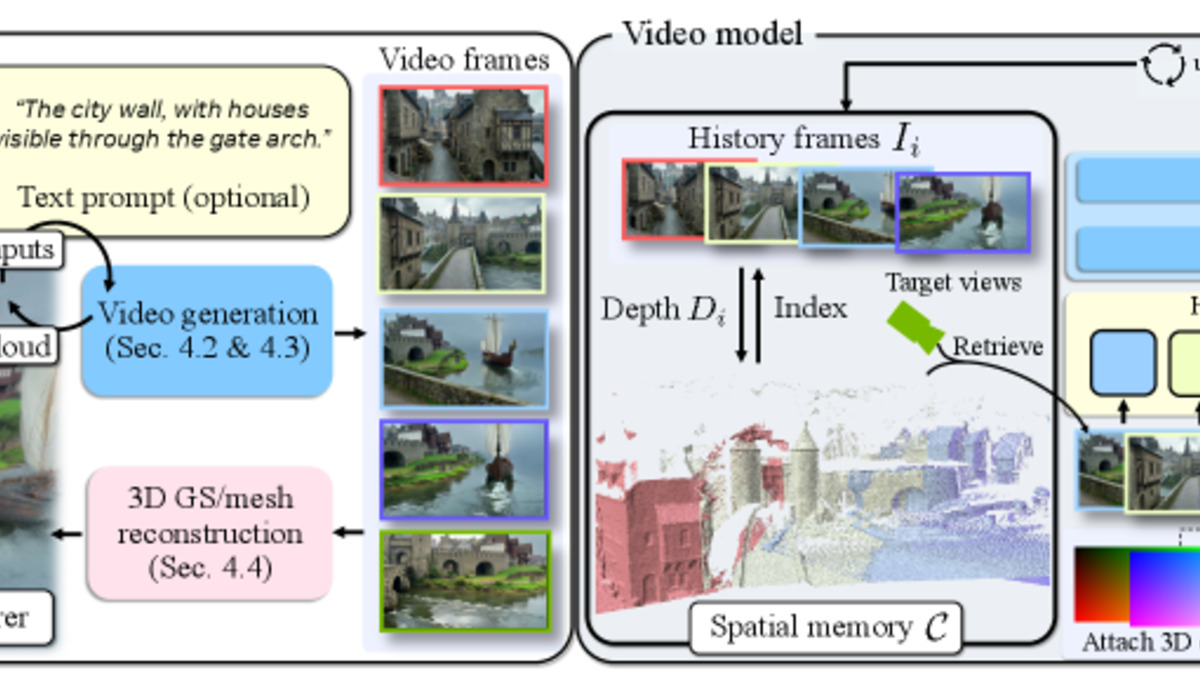
Lyra 2.0 runs two separate pipelines in sequence. The first creates video from the input image. The second lifts that video into 3D geometry.
Step 1 - Camera-Controlled Video Generation
The video backbone is Wán 2.1-14B, a Diffusion Transformer fine-tuned for long-horizon scene generation. Given an input image and a user-defined camera arc, the model produces 80-frame chunks autoregressively, extending the scene outward as the virtual camera moves. NVIDIA trained it on 10,000 long video clips from the DL3DV dataset using 64 GB200 GPUs over 7,000 iterations.
Two technical problems needed solving before the results were usable, both rooted in the difficulty of generating long sequences autoregressively.
Spatial forgetting is what happens when a created video revisits an earlier part of the scene - the model loses track of what the space looked like, and the regenerated region looks different. Lyra 2.0 addresses this by maintaining per-frame 3D geometry and using it for information routing: it retrieves relevant past frames through dense 3D correspondences rather than image conditioning. The geometry is a spatial index, not just a pretty output.
Temporal drifting is error accumulation over long sequences - small inconsistencies in one chunk compound into visible artifacts in the next. The fix is self-augmentation training: during training, the model is exposed to its own degraded one-step predictions at 70% of iterations, forcing it to learn drift correction rather than propagating accumulated mistakes.
Step 2 - Lifting to 3D Gaussians
Once the video is generated, a separate feed-forward reconstruction pipeline converts it to 3D Gaussian splats (.ply files) and surface meshes. This second stage is a fine-tuned version of Depth Anything V3 with a modified Gaussian DPT head that reduces the number of Gaussians by 4x. NVIDIA trained it on 3,000 produced one-minute videos over 10,000 iterations.
The resulting geometry exports directly to NVIDIA Isaac Sim. That's the primary use case the team shows: dropping a robot into a scene reconstructed from a photograph, then testing navigation and interaction in a physically grounded environment.
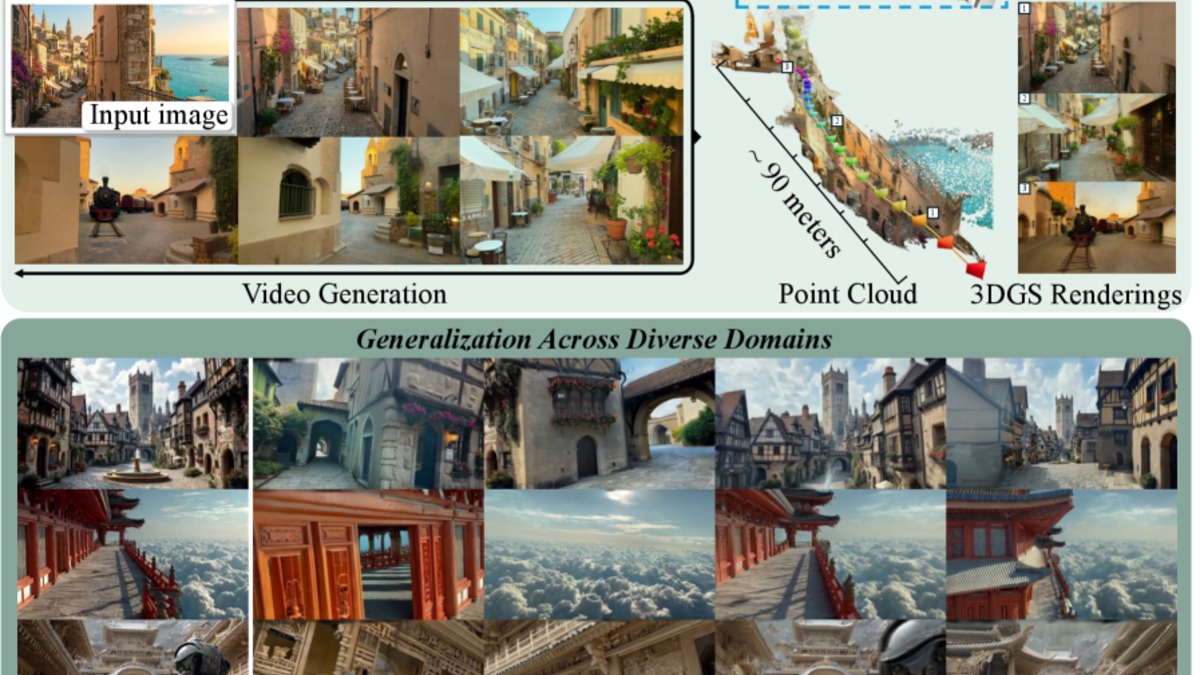 Lyra 2.0 takes a single input image and produces navigable 3D scenes extending up to 90 meters.
Source: arxiv.org/abs/2604.13036
Lyra 2.0 takes a single input image and produces navigable 3D scenes extending up to 90 meters.
Source: arxiv.org/abs/2604.13036
Benchmark Results
On the Tanks and Temples benchmark, Lyra 2.0 beats GEN3C, CaM, and SPMem across every reported metric (SSIM and Style Consistency: higher is better; LPIPS and FID: lower is better):
| Method | SSIM | LPIPS | FID | Style Consistency |
|---|---|---|---|---|
| Lyra 2.0 | 0.384 | 0.552 | 51.33 | 85.07 |
| GEN3C | 0.350 | 0.589 | 79.07 | 75.54 |
| CaM | 0.367 | 0.605 | 59.20 | 82.83 |
| SPMem | 0.383 | 0.571 | 60.11 | 79.68 |
The ablation study shows where the margin comes from. Removing self-augmentation drops Style Consistency from 85.07 to 77.98. Removing the spatial memory module (FramePack) increases reprojection error from 0.069 to 0.079. Both components are doing real work, not just tuning.
NVIDIA also reports that Lyra 2.0 outperforms Yume-1.5 on image quality and camera controllability in separate evaluations, though head-to-head numbers aren't in the paper.
 Benchmark comparison from the Lyra 2.0 paper showing improvements across SSIM, LPIPS, and FID metrics.
Source: arxiv.org/abs/2604.13036
Benchmark comparison from the Lyra 2.0 paper showing improvements across SSIM, LPIPS, and FID metrics.
Source: arxiv.org/abs/2604.13036
Running It Yourself
Hardware Requirements
| Requirement | Details |
|---|---|
| GPU Architecture | Ampere, Hopper, or Blackwell (H100 / GB200 recommended) |
| VRAM | 80GB+ for full model inference |
| Operating System | Linux only |
| Model Size | 14B parameters |
| Storage | ~30GB for weights |
No managed inference endpoint exists at launch. Teams run it on their own hardware. If you don't have a H100 or equivalent, you're not running this locally.
Setup
# Clone the repository and navigate to Lyra 2.0
git clone https://github.com/nv-tlabs/lyra
cd lyra/Lyra-2
# Install dependencies
pip install -r requirements.txt
# Download weights from HuggingFace (research license applies)
huggingface-cli download nvidia/Lyra-2.0 --local-dir ./weights
The distilled variant (DMD, 4 denoising steps instead of 35) cuts generation time from ~194 seconds per segment to ~15 seconds - a 13x speedup. For most research workflows, that's the version worth using.
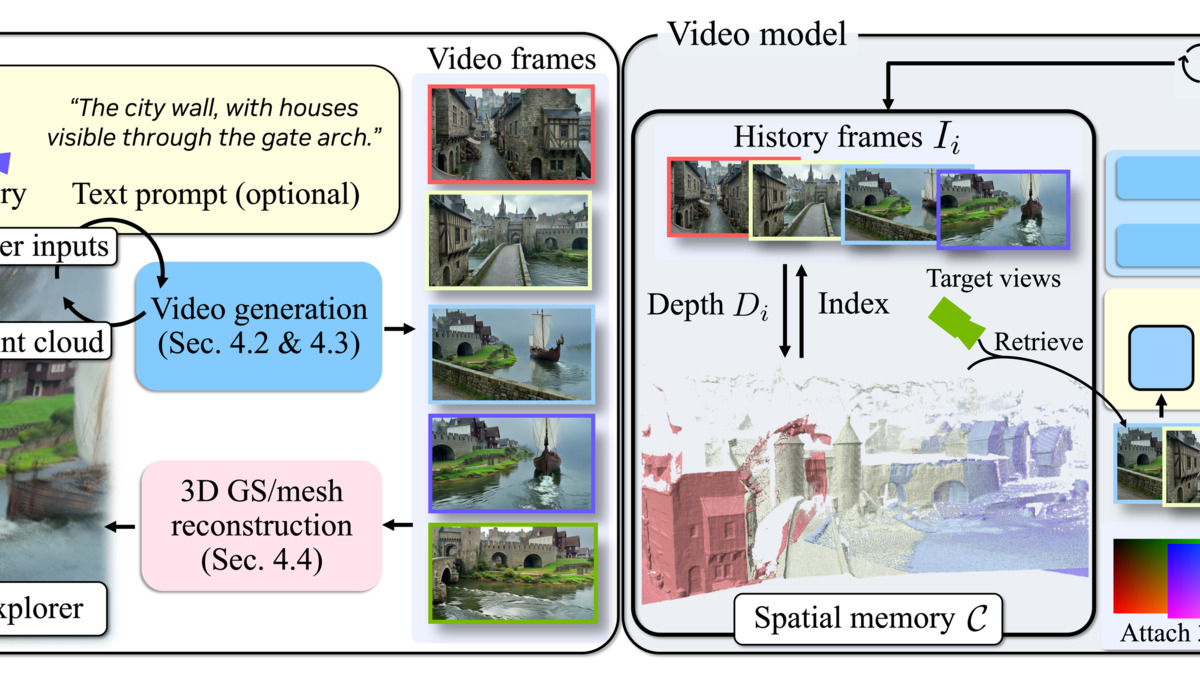 System overview: the two-stage pipeline from input image through camera-controlled video generation to 3D Gaussian reconstruction.
Source: research.nvidia.com/labs/sil/projects/lyra2
System overview: the two-stage pipeline from input image through camera-controlled video generation to 3D Gaussian reconstruction.
Source: research.nvidia.com/labs/sil/projects/lyra2
Where It Falls Short
The weights license isn't open. This is the one thing every downstream user needs to understand before getting excited. The Apache 2.0 on the code covers training scripts and inference scaffolding. The model weights themselves are under NVIDIA's Internal Scientific Research and Development License, which explicitly prohibits production deployment, distribution, and commercial use. NVIDIA pulled the same move with Cosmos and several other "open source" releases - the code is open, the model isn't. If you need this in a product, you're waiting for a commercial license that doesn't exist yet.
Static scenes only. Lyra 2.0 doesn't handle dynamic objects - no people walking, no vehicles, no weather. The generated environment is a frozen reconstruction of whatever was in the input image. For robotics training in controlled warehouse environments, this works. For any application involving moving objects, it doesn't.
The hardware bar is real. Running 14B-parameter video diffusion inference needs 80GB+ of VRAM. That's one H100 minimum. The distilled 4-step variant helps with speed, but it doesn't reduce memory requirements. Researchers without access to high-end compute will need to use the model through a cloud provider or wait for a quantized community fork.
No managed endpoint at launch. Unlike NVIDIA's Alpamayo, which shipped with inference access through Hugging Face, Lyra 2.0 requires self-hosting from day one. That limits adoption to labs and companies with the infrastructure to run it.
The practical ceiling for Lyra 2.0 right now is robotics simulation data generation - a useful but narrow application. The research value is higher, especially for teams working on embodied AI and physical AI that need to create training environments at scale without expensive real-world data collection. For robotics teams generating synthetic training environments from real-world images, this is the most capable option available today. For everyone else, the weights license makes Lyra 2.0 a paper to cite, not a tool to ship.
Sources:
Last updated
