Mistral Ships Voxtral - Open-Weights Voice AI Platform
Mistral releases Voxtral, a pair of open-weights models covering speech recognition and text-to-speech that undercut OpenAI and ElevenLabs on price.

Mistral just dropped Voxtral, and it's two products at once: an open-weights speech recognition family that beats Whisper large-v3 on every benchmark Mistral tested, and a 4B text-to-speech model that clones a voice from three seconds of audio. Both run on consumer hardware. The ASR comes under Apache 2.0. The TTS ships under CC BY NC 4.0.
Key Specs - Voxtral ASR
| Spec | Voxtral 24B | Voxtral Mini 3B |
|---|---|---|
| Backbone | Mistral Small 3.1 | Ministral 3B |
| Context | 32,000 tokens | 32,000 tokens |
| Max audio (transcription) | 30 minutes | 30 minutes |
| Max audio (understanding) | 40 minutes | 40 minutes |
| Languages | 9 | 9 |
| API price | $0.001/min | $0.001/min |
| License | Apache 2.0 | Apache 2.0 |
Two Models, One Brand
Mistral is bundling ASR and TTS under the Voxtral name, which could cause confusion - they're architecturally unrelated and licensed differently. The bigger story is the ASR side.
Voxtral 24B and Mini
The 24B model is built on the Mistral Small 3.1 backbone, which means it retains full text LLM capabilities. You can feed it an hour-long recording and ask it to summarize the action items, not just produce a transcript. The pipeline doesn't require separate ASR-then-LLM chaining - the model does both in one pass.
Voxtral Mini uses a 3B backbone aimed at edge deployments and local inference. Both support the same nine languages with automatic language detection: English, Spanish, French, Portuguese, Hindi, German, Dutch, Italian, and Arabic.
One capability that stands out: function-calling triggered directly from spoken intent. A user says "set a reminder for 3pm" and the model issues the function call without an intermediate transcription step. Whether this works reliably in noisy real-world audio is something the benchmarks don't answer.
What "Retains Text Capabilities" Actually Means
Because Voxtral is built on a language model backbone rather than a purpose-built acoustic encoder, it handles long-form audio better than traditional ASR systems. The 32,000-token context window lets it maintain coherence across multi-speaker conversations, lectures, and earnings calls. Domain-specific fine-tuning for legal, medical, or customer support use cases is possible with standard tools, since the weights are Apache 2.0.
 Voxtral launch visual from Mistral's official announcement, March 26, 2026.
Source: mistral.ai
Voxtral launch visual from Mistral's official announcement, March 26, 2026.
Source: mistral.ai
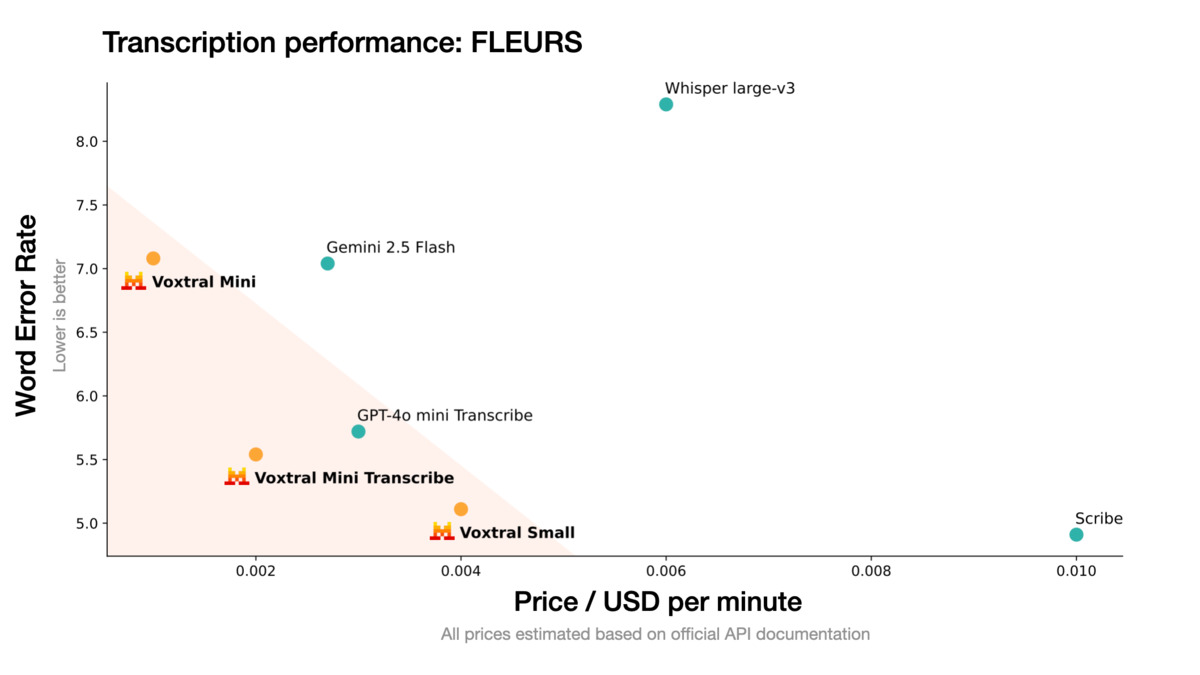
Benchmarks: The Numbers Mistral Chose to Show
Mistral reports Voxtral beats Whisper large-v3, GPT-4o mini Transcribe, and Gemini 2.5 Flash across all transcription benchmarks they tested, including English short-form, Mozilla Common Voice, and FLEURS multilingual. On speech translation, they claim state-of-the-art results.
| Model | English Short-Form | FLEURS Multilingual | Speech Translation |
|---|---|---|---|
| Voxtral 24B | Best in class | Best in class | State-of-the-art |
| GPT-4o mini Transcribe | Below Voxtral | Below Voxtral | Not reported |
| Gemini 2.5 Flash | Below Voxtral | Below Voxtral | Not reported |
| Whisper large-v3 | Below Voxtral | Below Voxtral | N/A |
A table like this always requires scrutiny. Mistral selected the benchmarks, the test sets, and the evaluation methodology. Independent replication takes time. The FLEURS multilingual result is plausible given that European languages are well-represented in Mistral's training data, but word error rates on low-resource languages within the nine supported are not broken out.
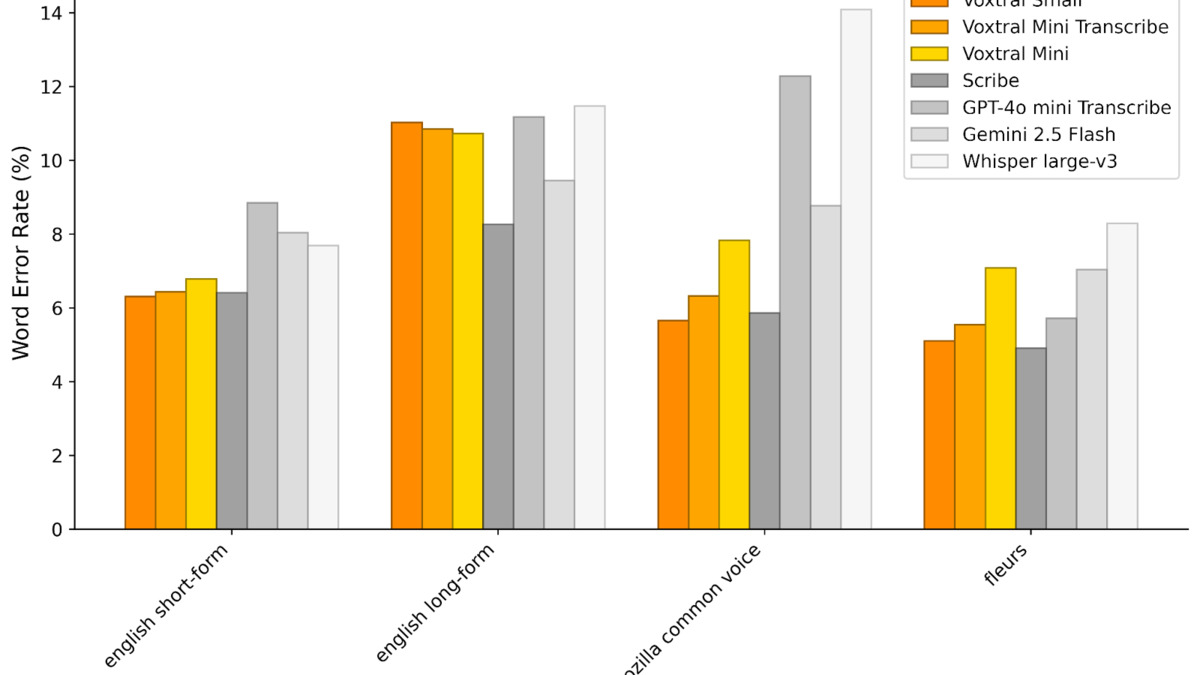 Voxtral benchmark results across English short-form, Mozilla Common Voice, and FLEURS. Source: Mistral AI, March 26, 2026.
Source: mistral.ai
Voxtral benchmark results across English short-form, Mozilla Common Voice, and FLEURS. Source: Mistral AI, March 26, 2026.
Source: mistral.ai
The pricing argument is harder to dispute: $0.001 per minute via API puts Voxtral at roughly half the cost of comparable hosted solutions, at least based on Mistral's own comparison. For anyone running transcription at volume - customer support pipelines, podcast workflows, meeting intelligence - the cost difference compounds fast.
This positions Voxtral directly against IBM Granite 4 Speech, which IBM also launched for edge ASR, and against Tencent's Covo-Audio 7B, which targeted the OpenAI Realtime API. The open-weights voice AI space got very crowded, very fast.
The TTS Side
The text-to-speech model is 4 billion parameters, licensed under CC BY NC 4.0 (not Apache 2.0 - commercial use requires a separate agreement). It covers the same nine languages as the ASR and can clone a custom voice from as little as three seconds of reference audio, capturing accent, inflection, and natural speech patterns including pauses and repetitions.
Mistral's human evaluation puts it at naturalness parity with ElevenLabs Flash v2.5, with comparable performance to ElevenLabs v3 on voice agent interactions. API pricing is $0.016 per 1,000 characters. Latency to first audio on a 500-character input is reported at 70ms.
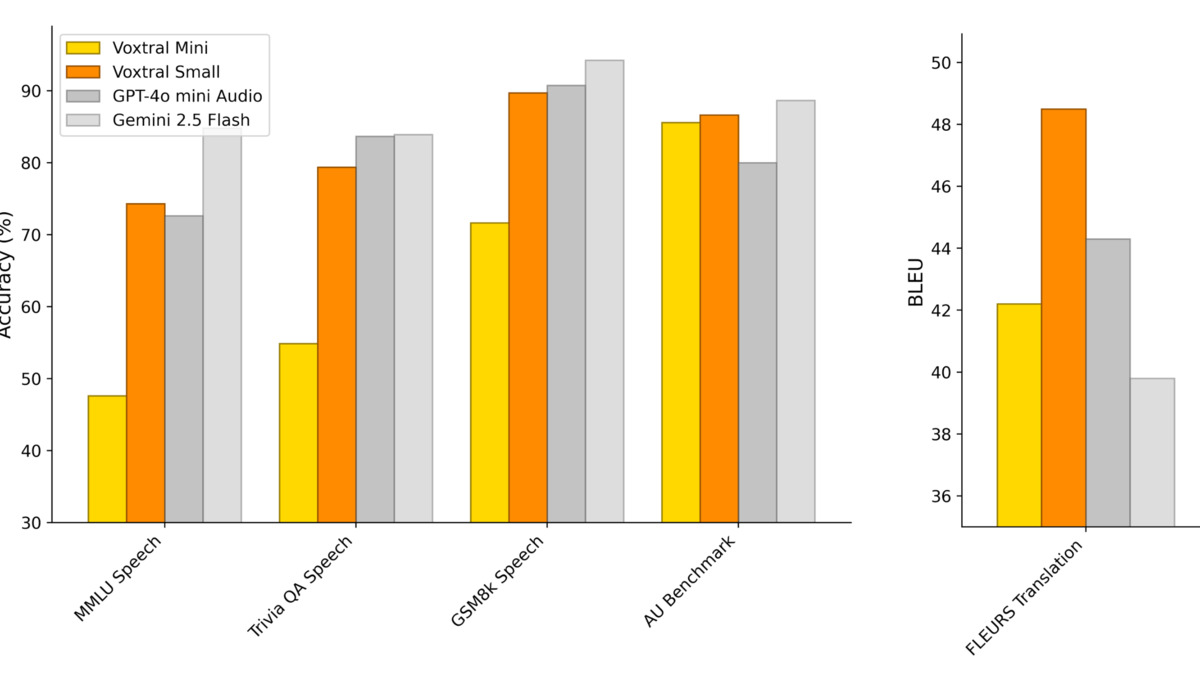 Audio understanding and reasoning benchmark results for Voxtral, comparing against GPT-4o mini and Gemini 2.5 Flash.
Source: mistral.ai
Audio understanding and reasoning benchmark results for Voxtral, comparing against GPT-4o mini and Gemini 2.5 Flash.
Source: mistral.ai
The CC BY NC license on the TTS weights matters. Apache 2.0 on the ASR means enterprise self-hosting is straightforward. The TTS is downloadable on Hugging Face, but commercial deployment requires going through Mistral's API or negotiating a separate license. That's a meaningful distinction for teams trying to build fully on-premise voice pipelines, and it's why the open-source framing only applies cleanly to the ASR side.
What To Watch
The Roadmap Items That Aren't There Yet
Mistral's announcement lists several capabilities as in development: speaker segmentation, audio emotion and age markup, word-level timestamps, and non-speech audio recognition. These aren't in the current release. For production voice applications, word-level timestamps are often mandatory - without them, syncing transcripts to audio for review is painful. Their absence from v1 is the most striking gap.
Mistral's Strategic Shift
This release is a significant pivot from Mistral's recent consulting and enterprise platform focus. Shipping two models simultaneously that compete with ElevenLabs, Deepgram, Whisper, and Google puts Mistral back in the open-weights model race rather than on the sidelines of it. It also fits the broader pattern of open-source models closing the gap with proprietary alternatives across modality after modality.
Hugging Face Availability and Fine-Tuning
Both ASR model variants are downloadable now on Hugging Face. The Apache 2.0 license means teams can fine-tune on domain-specific audio without restrictions. A 3B model that runs on edge hardware and can be specialized for a specific accent or industry vocabulary is a legitimate enterprise story - assuming the base performance holds up in real-world noise conditions, which controlled benchmarks systematically undertest.
Mistral's research paper is available at arxiv.org/abs/2507.13264. The question for the next few weeks is whether independent evaluations replicate the benchmark claims - particularly on FLEURS multilingual, where the competition has been fierce and the methodology choices matter enormously.
Sources:

