Mistral Small 4: 128 Experts, 6B Active, Apache 2.0
Mistral AI releases Small 4 - a 119B MoE with only 6B active parameters, 256K context, configurable reasoning, and Apache 2.0 license. Plus a new NVIDIA partnership to co-develop frontier open models.

Mistral AI dropped two announcements at GTC 2026. The first: Mistral Small 4, a 119B parameter mixture-of-experts model that activates only 6B parameters per token, ships under Apache 2.0, and introduces configurable reasoning. The second: a strategic partnership with NVIDIA to co-develop frontier open-source models as part of the new Nemotron Coalition.
TL;DR
- 119B total / 6B active per token, 128 experts (4 active), 256K context window
- Apache 2.0 - fully open, commercial use allowed
- Configurable reasoning:
reasoning_effort="none"for fast mode,"high"for step-by-step (replaces needing separate models) - 40% faster latency, 3x throughput vs Mistral Small 3
- Beats GPT-OSS 120B on LiveCodeBench while producing 20% less output
- NVIDIA partnership: Mistral joins Nemotron Coalition, will co-develop frontier base models on DGX Cloud
The Architecture
| Spec | Detail |
|---|---|
| Total parameters | 119B |
| Active parameters | 6B per token (8B with embeddings) |
| Architecture | Mixture of Experts (MoE) |
| Experts | 128 total, 4 active per token |
| Context window | 256K tokens |
| License | Apache 2.0 |
| Multimodal | Text + image input |
| Latency improvement | 40% faster than Small 3 |
| Throughput improvement | 3x more requests/sec than Small 3 |
The efficiency story is the headline. 119B parameters sounds large, but only 6B activate per token - making inference costs comparable to a 7B dense model while drawing on the knowledge capacity of a much larger one. The 128-expert design (vs typical 8-16 experts in earlier MoE models) enables finer-grained specialization across the expert pool.
Configurable Reasoning
This is the feature that matters most for developers. Instead of maintaining separate models for fast responses and deep reasoning, Small 4 exposes a single reasoning_effort parameter:
reasoning_effort="none": Fast, direct responses matching Mistral Small 3.2 behavior. Minimal output tokensreasoning_effort="high": Step-by-step chain-of-thought reasoning equivalent to Magistral. More tokens, deeper analysis
One model, one deployment, one API - with a parameter toggle between speed and depth. This removes the operational overhead of routing between a fast model and a reasoning model, which is how most production systems currently handle the tradeoff.
On the LCR (Logical Reasoning) benchmark, Small 4 achieves 0.72 accuracy with 1.6K character output. Comparable Qwen models require 5.8-6.1K characters (3.5-4x more output) for similar accuracy. Less output at equal quality means lower inference costs.
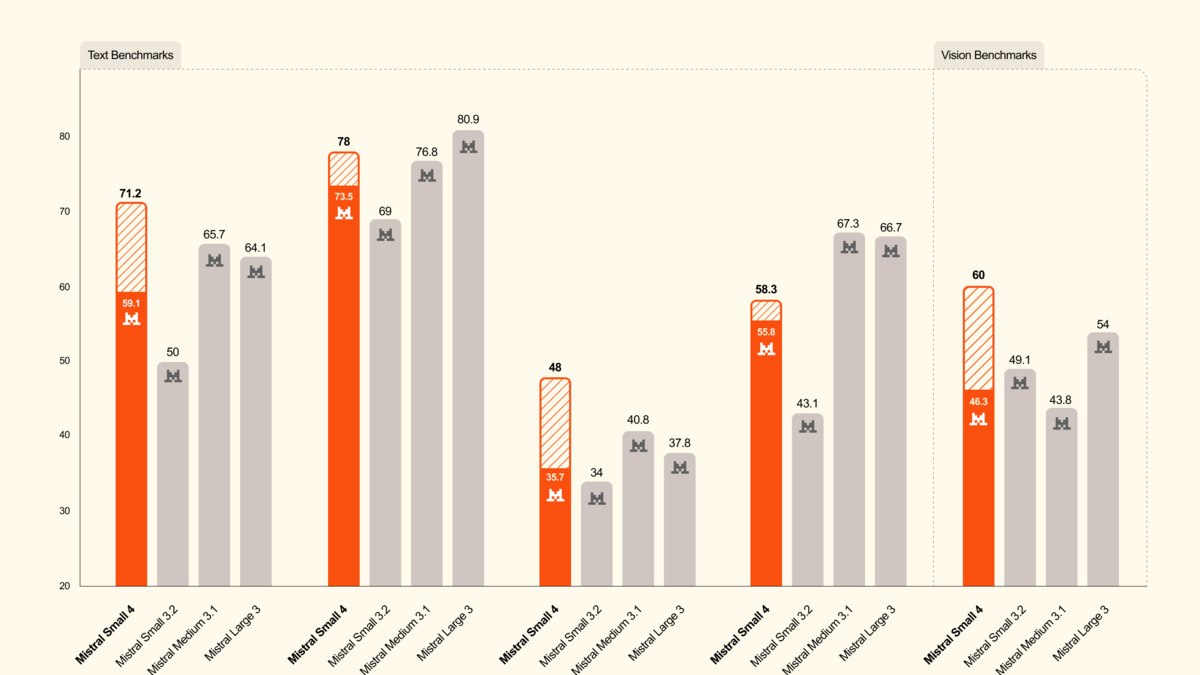 Mistral Small 4 beats GPT-OSS 120B on LiveCodeBench while producing 20% less output.
Source: mistral.ai
Mistral Small 4 beats GPT-OSS 120B on LiveCodeBench while producing 20% less output.
Source: mistral.ai
The NVIDIA Partnership
With Small 4, Mistral announced a strategic partnership with NVIDIA as a founding member of the Nemotron Coalition - a group of eight AI labs (including Black Forest Labs, Cursor, LangChain, Perplexity, Reflection AI, Sarvam, and Thinking Machines Lab) collaborating on open frontier models.
The first project: a base model co-developed by Mistral and NVIDIA, trained on NVIDIA DGX Cloud, which will underpin the upcoming Nemotron 4 model family. Mistral brings its MoE architecture expertise and training techniques. NVIDIA brings compute, synthetic data pipelines, and deployment infrastructure (NIM).
"Open frontier models are how AI becomes a true platform. Together with NVIDIA, we will take a leading role in training and advancing frontier models at scale."
- Arthur Mensch, Mistral CEO
This positions Mistral as NVIDIA's preferred open-model partner - a significant strategic alignment. NVIDIA gets a frontier model builder for its Nemotron lineup. Mistral gets DGX Cloud compute that would otherwise cost tens of millions.
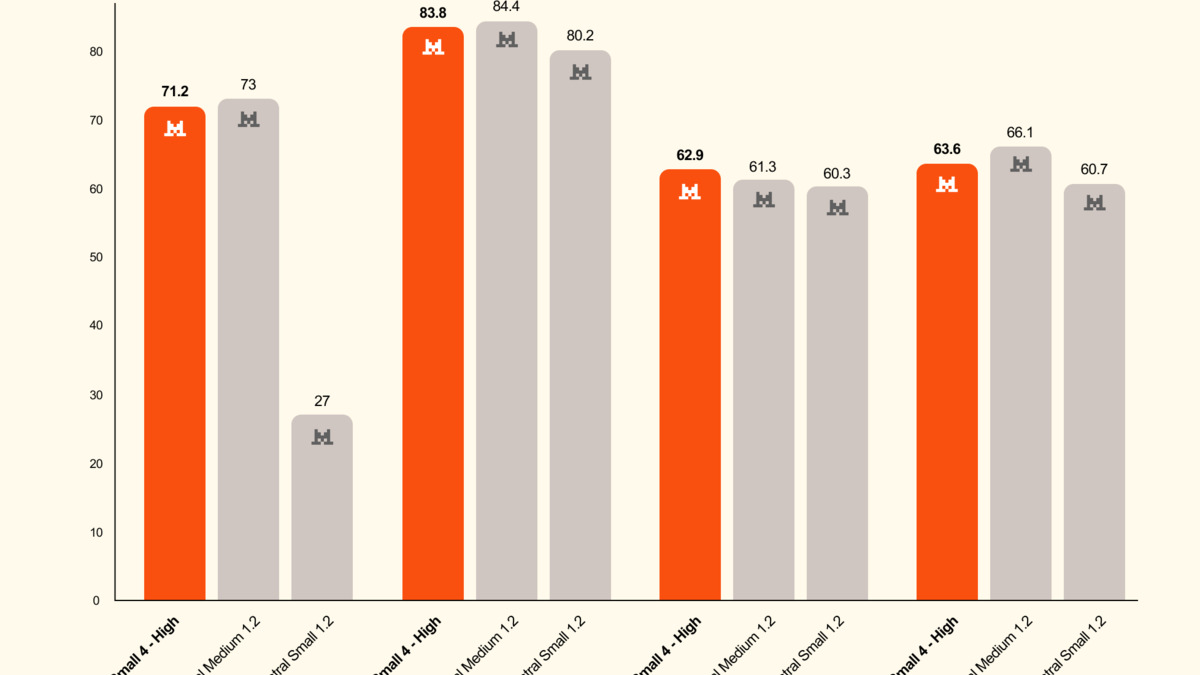 Configurable reasoning: Small 4 achieves comparable accuracy to larger models with markedly less output.
Source: mistral.ai
Configurable reasoning: Small 4 achieves comparable accuracy to larger models with markedly less output.
Source: mistral.ai
Hardware Requirements
| Setup | Configuration |
|---|---|
| Minimum | 4x NVIDIA HGX H100, 2x HGX H200, or 1x DGX B200 |
| Recommended | 4x HGX H100, 4x HGX H200, or 2x DGX B200 |
The hardware requirements are major for local deployment despite the 6B active parameter count - the full 119B parameter set needs to reside in memory. This pushes self-hosting toward enterprise GPU clusters. Most developers will use the API or cloud deployments.
Where It Falls Short
The "Small" branding is misleading. A model requiring 4x H100s to run isn't small by any practical definition. The 6B active parameter count is efficient at inference time, but the 119B total means you need the same VRAM as a large dense model. The name optimizes for marketing, not accuracy.
Benchmark selection is narrow. Mistral highlights LCR, LiveCodeBench, and AIME 2025 - all reasoning-heavy benchmarks where MoE models with configurable reasoning naturally excel. Broader evaluations (MMLU, GPQA Diamond, multilingual, long-context retrieval) aren't shown.
The NVIDIA partnership is early-stage. The Nemotron Coalition was announced on the same day. No co-developed model exists yet. The partnership is a commitment to build something, not a shipped product.
Deployment
| Platform | Status |
|---|---|
| Mistral API / AI Studio | Available |
| Hugging Face | Available |
| NVIDIA build.nvidia.com | Free prototyping |
| NVIDIA NIM | Production deployment |
| vLLM, SGLang, llama.cpp | Supported |
| Transformers | Supported |
Mistral Small 4 is the model Mistral should have shipped six months ago: one model that does fast responses and deep reasoning, with a parameter toggle instead of separate deployments. The 128-expert MoE at 6B active params per token is architecturally elegant. The Apache 2.0 license removes friction. The NVIDIA partnership gives Mistral access to the compute it needs to compete at frontier scale. The question is whether "configurable reasoning" in a single model can match the quality of purpose-built reasoning models like Claude Opus 4.6 or DeepSeek R2 - or whether the one-model-fits-all approach trades convenience for depth.
Sources:

