Mistral Ships Medium 3.5 With Cloud Coding Agents
Mistral releases Medium 3.5, a 128B open-weights model that scores 77.6% on SWE-Bench Verified, and pairs it with asynchronous cloud coding agents in Vibe that open pull requests on GitHub while you are away.

Mistral released Medium 3.5 on April 29, and the headline number is 77.6% on SWE-Bench Verified - an open-weights 128B model that edges past Claude Sonnet 4 (77.2%) and sits 1.2 points below Gemini 3.1 Pro Preview (78.8%), both of which are proprietary. At $1.50 per million input tokens, it costs less than either.
The model ships with a rebuilt Vibe product: asynchronous cloud coding agents powered by Medium 3.5 that spawn from the CLI or Le Chat, run in isolated sandboxes, and return completed pull requests on GitHub when finished. You don't have to watch them work.
Key Specs
| Spec | Value |
|---|---|
| Parameters | 128B dense |
| Context Window | 256K tokens |
| SWE-Bench Verified | 77.6% |
| Tau3-Telecom | 91.4% |
| Open Weights | Yes (Modified MIT) |
| API Input | $1.50/M tokens |
| API Output | $7.50/M tokens |
| Self-Host Minimum | 4 GPUs, ~128GB VRAM (FP8) |
What Medium 3.5 Actually Delivers
Architecture and Context Window
Medium 3.5 is a dense model, not a mixture-of-experts design. For long-running coding agents - sessions that may take hundreds of tool calls and file writes - a dense architecture behaves more predictably than a MoE variant, where active parameter counts shift with input token patterns.
The 256K token context window matches current frontier models. More interesting is the reasoning_effort parameter: callers can adjust reasoning depth per request, trading latency for thoroughness. A quick docstring update and a full-module refactor can share the same API endpoint with different effort settings.
Vision is native, using a custom encoder designed for variable image resolution. There's no preprocessing requirement before passing screenshots or documents into the model.
Benchmark Performance
SWE-Bench Verified tests autonomous software engineering on real GitHub issues, with external verification of whether the fixes actually work. Medium 3.5's 77.6% is the highest score posted by an open-weights model on this benchmark.
| Model | SWE-Bench Verified | Open Weights |
|---|---|---|
| GPT-5.5 | 82.6% | No |
| Claude Opus 4.7 | 82.0% | No |
| Gemini 3.1 Pro Preview | 78.8% | No |
| Mistral Medium 3.5 | 77.6% | Yes |
| Claude Sonnet 4 | 77.2% | No |
| GPT-5 | 74.9% | No |
| Gemini 2.5 Pro | 73.1% | No |
The gap between Medium 3.5 and Claude Sonnet 4 is 0.4 percentage points on SWE-Bench Verified. Medium 3.5 is available as open weights; Sonnet 4 isn't. On Tau3-Telecom, a benchmark covering agentic tool use in domain-specific environments with multi-step planning requirements, Medium 3.5 scores 91.4%. That benchmark is a closer proxy for Vibe's actual use patterns than academic reasoning tests.
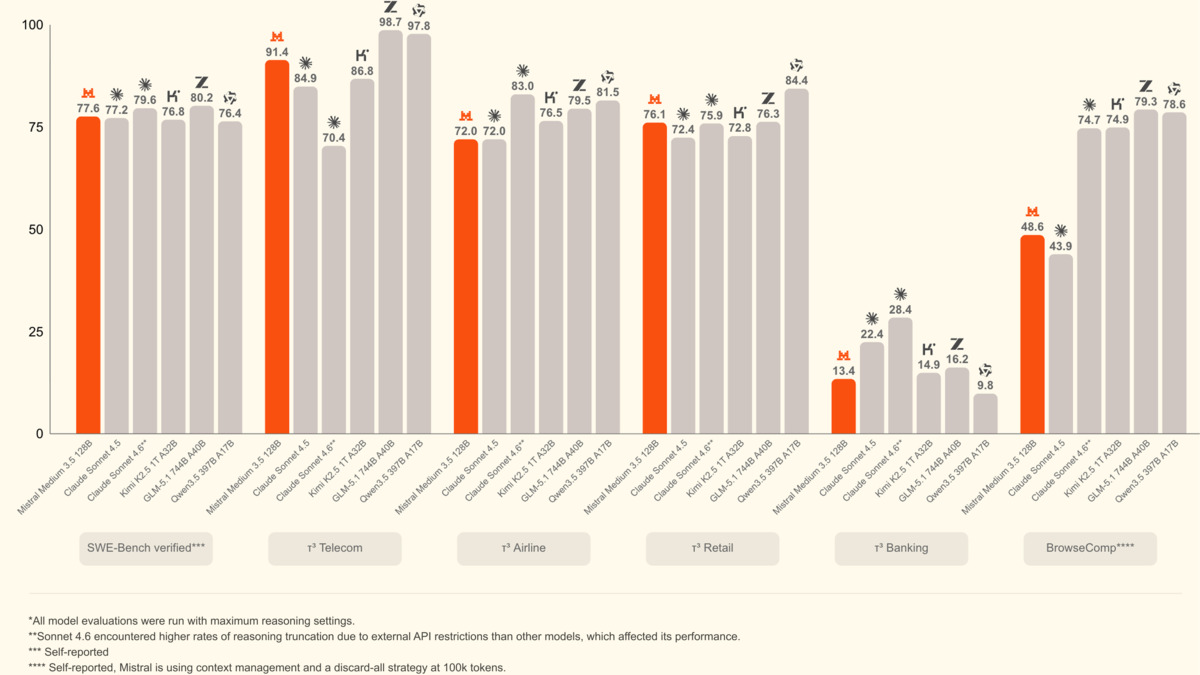 Agentic benchmark comparison from Mistral's announcement. Medium 3.5 leads on SWE-Bench Verified and Tau3-Telecom among models shown.
Source: mistral.ai
Agentic benchmark comparison from Mistral's announcement. Medium 3.5 leads on SWE-Bench Verified and Tau3-Telecom among models shown.
Source: mistral.ai
Vibe Remote Agents - The Bigger Story
The model numbers are real. The execution model change is more consequential.
"High-volume, well-defined work that takes a developer's time without taking their judgment: module refactors, test generation, dependency upgrades, CI investigations, as well as bug fixes."
That quote from Mistral's announcement describes the design target precisely. The agents don't handle exploratory architecture work. They handle the category of tasks that is clearly defined, reproducible, and where the output can be reviewed at the PR stage rather than the keystroke level.
If you've read our Mistral Vibe 2.0 review, the local CLI version required you to stay present through execution. Remote agents remove that constraint.
How Async Sessions Work
You spawn a session from the Vibe CLI or from Le Chat with a task description. The agent receives a cloned repository in an isolated sandbox, full write access, and permission to install dependencies. It works through the task while tracking file diffs, tool calls, and open questions. When it needs a decision it can't make autonomously, it surfaces the question rather than proceeding on a bad assumption.
Multiple sessions run in parallel without interfering with each other. Mistral's framing is that you stop being the bottleneck in your own automation.
Local CLI sessions can be migrated to the cloud mid-execution. Session history, working state, and any pending approvals transfer. You start a task on a laptop, close the lid, and check the PR the next morning.
Integration Ecosystem
When a session finishes, it opens a pull request on GitHub directly. Linear and Jira provide task context at session start. Sentry connects incident reports to the agents being assigned to fix them. Slack and Teams handle completion notifications.
The integration surface is narrow by design. Mistral isn't building a general automation platform. The connections are the minimum required to get code changes from task description to reviewable PR.
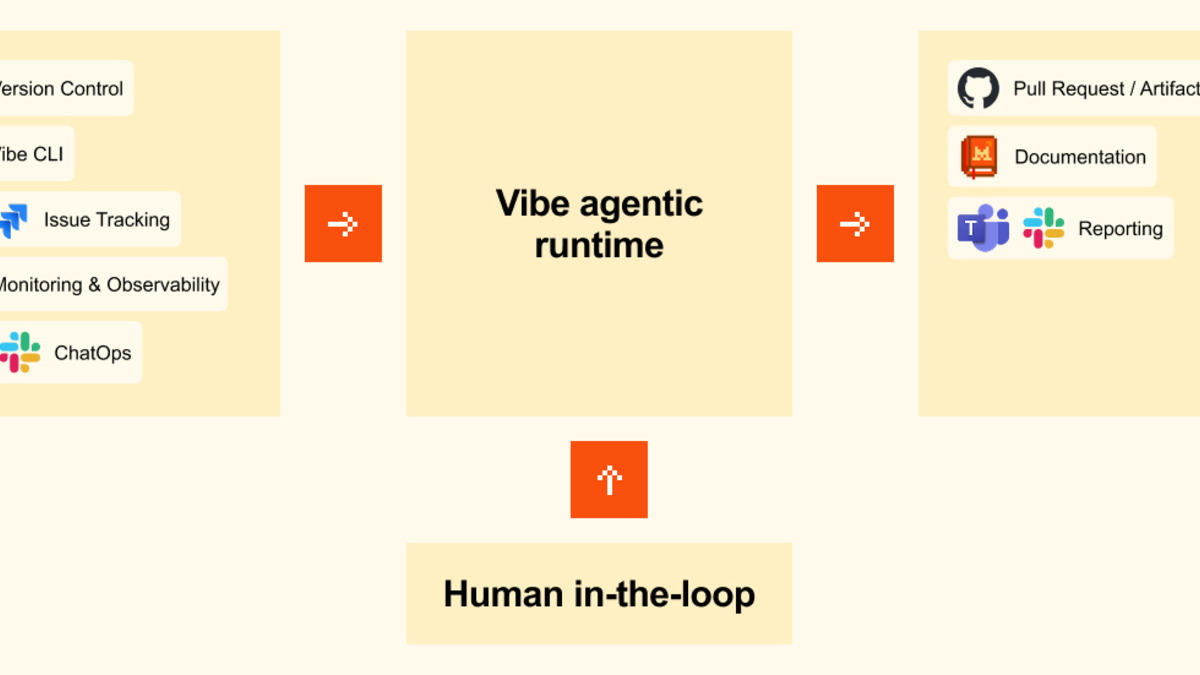 Vibe's agentic runtime connects dev tooling inputs to structured outputs like pull requests and reports.
Source: mistral.ai
Vibe's agentic runtime connects dev tooling inputs to structured outputs like pull requests and reports.
Source: mistral.ai
Le Chat Work Mode
Alongside the coding agents, Mistral shipped a Work mode for Le Chat. This extends into general productivity workflows: email triage with draft reply generation, research synthesis across internal documents and the web, calendar and inbox management across connected accounts.
Work mode requires explicit user approval for sensitive operations. Sessions persist across multiple turns, which means you can continue iterating on a task without re-explaining context. Mistral is positioning this as the general-productivity counterpart to Vibe's developer-focused agents - same execution model, different domain.
Self-Hosting on Four GPUs
Medium 3.5 runs at FP8 precision on about 128GB of VRAM. That's four NVIDIA H100 80GB cards as a baseline, or an equivalent cloud instance. Not a consumer setup, but reachable for on-premises clusters or organizations with data residency requirements that rule out third-party API usage.
The open weights come under a modified MIT license. Standard MIT permits commercial use freely; the modified variant carries additional restrictions. Organizations planning to fine-tune, redistribute, or integrate the weights into a commercial product should review the license terms before committing.
The model works with vLLM, SGLang, and Ollama. Mistral also ships a NVIDIA NIM container for teams already running the NIM stack.
For teams where sending code to an external API is not negotiable, this is the first open-weights coding model that runs reasonably close to frontier performance on a four-GPU setup. Mistral's recent work on open-source releases has consistently focused on this tier: enough performance to be useful in production, deployable without a full data center.
What To Watch
SWE-Bench Verified has real limits. The issue set is curated, the verification is automated rather than human-reviewed, and a 77.6% aggregate score doesn't tell you much about performance on your specific codebase with your toolchain and your team's definition of "done." Test it on a representative sample of your actual backlog before committing to it.
Remote agents are in public preview. Isolation guarantees, session persistence across multi-hour runs, and PR quality on complex multi-file refactors are all worth stress-testing before replacing human-in-the-loop review. The sandbox model enforces a code review step, which helps, but it doesn't substitute for understanding what the agent actually changed.
The $7.50/M output token cost compounds in agentic loops. An agent producing 2,000 tokens per tool call across 50 calls per session produces 100,000 output tokens - $0.75 per session. Across 100 parallel sessions, that's $75. Worth modeling against your actual expected usage patterns before projecting costs from the API pricing alone.
The model card at /models/mistral-medium-3-5/ covers specs, benchmarks, and deployment options in more detail.
Sources:
