MiniMax M3 Makes 1M Context Viable With Sparse Attention
MiniMax M3 uses sparse attention to cut long-context inference cost 20x, topping GPT-5.5 on coding benchmarks at a fraction of the price.

Million-token context windows have been available in AI APIs for the better part of a year. The problem was making them usable: standard attention scales quadratically with sequence length, so a 1M-token request costs roughly 100x more compute than a 10K request just from the attention operation alone. MiniMax M3, released June 1, is betting a custom sparse attention architecture can break that cost curve.
Key Specs
| Spec | Value |
|---|---|
| Context window | 1M tokens (512K guaranteed minimum) |
| Input price | $0.60/M tokens ($0.30/M during launch promo) |
| Output price | $2.40/M tokens ($1.20/M during launch promo) |
| Output speed | 43.9 tokens/sec (Artificial Analysis) |
| SWE-Bench Pro | 59.0% (vendor-reported) |
| Parameters | Not disclosed |
| Inputs | Text, image, video |
| Weights | Promised on Hugging Face by ~June 11 |
How Sparse Attention Changes the Equation
Standard full attention - the kind running in virtually every transformer rolled out today - has to consider every position in the context window when computing each output token. At 1M tokens that means attending to one million key-value pairs for every produced token. Memory traffic alone becomes the bottleneck before arithmetic does.
What MSA Actually Does
MiniMax Sparse Attention (MSA) breaks the problem in two stages. A lightweight index branch first selects which KV cache blocks are actually relevant to the current query. Only those blocks get passed into the full attention computation. The approach keeps a GQA (grouped-query attention) backbone with MSA layered on top - and crucially, it doesn't compress the KV state the way competing architectures like DeepSeek's MLA do. That preserves accuracy at very long contexts rather than trading it away for speed.
The implementation detail MiniMax highlights: KV blocks serve as the outer loop, so each block gets read from memory exactly once. Access patterns stay contiguous rather than scattered, which matters more than theoretical operation count when inference is memory-bandwidth-bound.
The Numbers at 1M Context
At maximum context length, MiniMax reports:
- 1/20th the per-token compute of M2 (the previous generation) at 1M tokens
- 9x faster prefill compared to M2 at 1M tokens
- 15x faster decoding at 1M tokens
- 4x faster than Flash-Sparse-Attention under the same head configuration
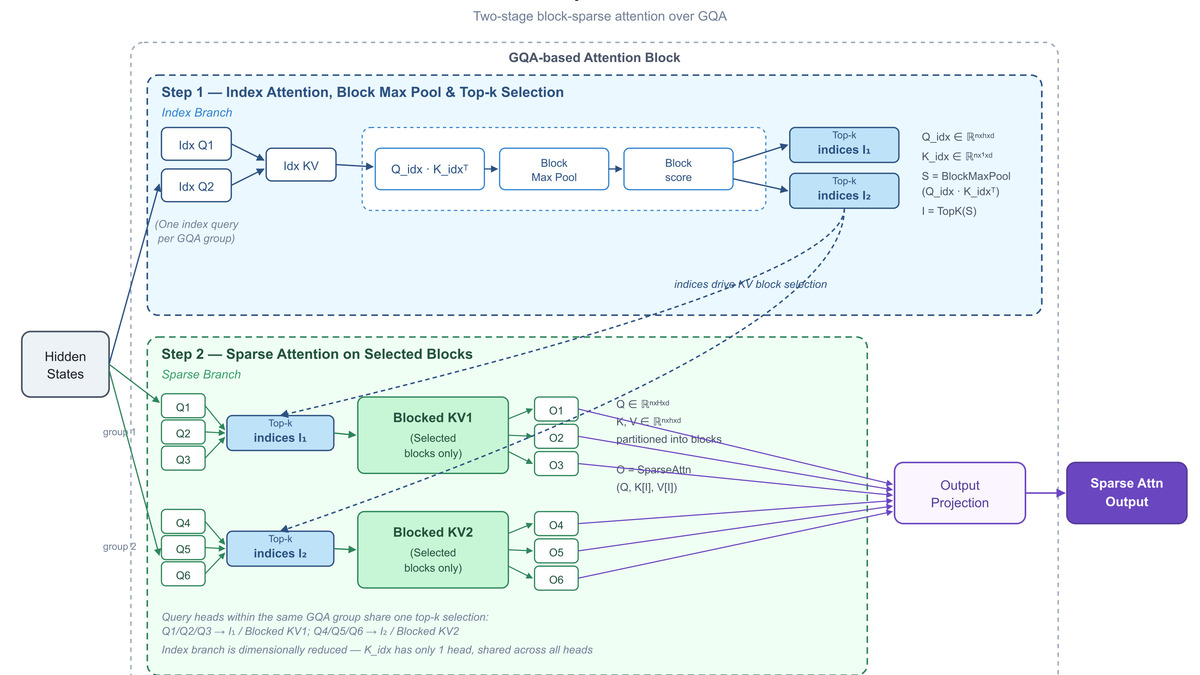 The MSA architecture diagram from Hugging Face's technical breakdown, showing how the index branch pre-selects KV blocks before the attention computation runs.
Source: huggingface.co
The MSA architecture diagram from Hugging Face's technical breakdown, showing how the index branch pre-selects KV blocks before the attention computation runs.
Source: huggingface.co
The practical result: M3's API speed at 1M context is reported at roughly 100 tokens per second output - about 3x faster than Claude Opus models at that length, according to MiniMax. Artificial Analysis independently measured 43.9 tokens per second overall (not specifically at maximum context), which puts it ahead of most frontier models in the same price bracket.
Benchmark Results
Every number in the table below comes from MiniMax's own launch materials, run on MiniMax infrastructure with agent scaffolding MiniMax configured. Independent verification was pending at launch.
| Benchmark | M3 | Claude Opus 4.8 | GPT-5.5 | Gemini 3.1 Pro |
|---|---|---|---|---|
| SWE-Bench Pro | 59.0% | 69.2% | 58.6% | 54.2% |
| Terminal-Bench 2.1 | 66.0% | 74.6% | - | - |
| OSWorld-Verified | 70.1% | 83.4% | - | - |
| BrowseComp | 83.5% | - | - | - |
| PostTrainBench | 37.1 (#3) | 42.4 (#1) | 39.3 (#2) | - |
On coding evals, M3 edges past GPT-5.5 on SWE-Bench Pro while staying 10 points behind Claude Opus 4.8's 69.2%. BrowseComp at 83.5% - compared against Claude Opus 4.7's 79.3% - is M3's clearest result. Computer use at 70.1% on OSWorld trails Opus 4.8 by 13 points. For context on where these numbers sit in the broader SWE-Bench leaderboard, M3 lands solidly in the open-weight frontier tier but not at the top.
MiniMax also ran a 12-hour autonomous agent demonstration: an ICLR paper replication spanning 18 commits and 23 experimental figures. That's meant to show long-horizon agentic capability at scale, not just a benchmark score, but it's still a demo MiniMax staged and reported internally.
 CUDA kernel optimization run from MiniMax's launch materials, showing iterative performance improvement across optimization cycles at 1M context.
Source: minimax.io
CUDA kernel optimization run from MiniMax's launch materials, showing iterative performance improvement across optimization cycles at 1M context.
Source: minimax.io
Pricing and Availability
The standard API rate is $0.60/M input tokens and $2.40/M output tokens. A 50% launch discount ran for the first week, bringing input to $0.30/M. Even at full price, that's roughly 5-10% of what Claude Opus charges at comparable context lengths.
For a 500K-input plus 100K-output agentic coding run, M3 costs around $0.54 at standard rates versus roughly $5 on frontier proprietary models. The gap is real. Subscription plans on MiniMax Code: Plus at $20/month (~1.7B tokens), Max at $50/month, Ultra at $120/month. Tokens are unified across text, image, speech, and music.
One caveat on the pricing headline: inputs above 512K tokens carry a context surcharge. The "1M context at $0.60/M" marketing figure applies only up to the 512K guarantee; longer requests cost more. The full model profile has the per-tier pricing breakdown.
M3 is also available through OpenRouter at the same rates. For long-context benchmark comparisons against other 1M-context models, M3's combination of speed and price is truly competitive - if the benchmarks hold up under independent testing.
What To Watch
Weights are still pending. MiniMax promised open weights on Hugging Face within ten days of the June 1 launch, targeting around June 11. As of this writing, nothing has appeared under the MiniMaxAI organization. June 11 hasn't passed yet, so this isn't a miss - but the "open-weight" label is doing significant work while the weights aren't actually available.
License terms are unknown. MiniMax's prior model, M2.7, shipped under a modified-MIT license blocking commercial use without written authorization from MiniMax. The company used "open-weight" language for that release too. M3's license ships with the weights, so you won't know what you're working with until they land. Don't assume permissive licensing based on the "open" framing.
Every benchmark is vendor-reported. MiniMax chose which benchmarks to include, configured the agent scaffolding, and ran everything on its own infrastructure. Artificial Analysis placed M3 at rank #1 out of 164 models in its price class on their Intelligence Index - a useful independent signal, though that index uses a composite score rather than a single task benchmark. Time-to-first-token at 2.60 seconds is slower than it looks for interactive use cases.
Chinese jurisdiction applies. MiniMax is a Shanghai-based company. API traffic falls under China's 2017 National Intelligence Law. That's an operational consideration, not a technical flaw, but it belongs in any serious deployment evaluation for teams handling sensitive code or data.
The predecessor, M2.7, shipped with verified open weights and a confirmed 59% SWE-Bench score on its own. M3's architecture gains are real - the MSA math checks out and the efficiency claims are consistent with how sparse attention works in practice. Whether the benchmark scores hold up when independent evaluators run their own tests is the open question that matters now.
Sources:
- MiniMax M3 Official Blog Post
- The Decoder: MiniMax M3 open-weight model with a million-token context
- Datanorth: MiniMax Launches M3
- Artificial Analysis: MiniMax M3 model profile
- TechTimes: MiniMax M3 - Frontier Claims, Unverified Benchmarks
- HuggingFace: MiniMax Goes Sparse - Decoding M3's Attention
- MarkTechPost: MiniMax releases MiniMax M3 with MSA Architecture
