MiniMax M2.7 Claims to Automate Its Own Training
MiniMax's new 2,300B MoE model tops the Artificial Analysis Intelligence Index and claims to run 30-50% of its own RL research workflow autonomously.

MiniMax shipped M2.7 on March 18 and right away claimed the top spot on the Artificial Analysis Intelligence Index, ranking ahead of Claude Opus 4.6, GPT-5.3-Codex, and every other model in their 136-model evaluation. The headline claim is more provocative: that M2.7 now handles 30-50% of its own reinforcement learning research workflow, running optimization loops autonomously over 100+ iterations.
That claim deserves a close reading. So do the numbers underneath it.
TL;DR
- 2,300B parameter MoE model with 100B active, 200K context - released March 18
- Ranked #1 on Artificial Analysis Intelligence Index across 136 models
- 78% on SWE-bench Verified, 56.22% on SWE-Pro - matching GPT-5.3-Codex
- API available now at $0.30/$1.20 per million tokens in/out
- "Self-evolving" means using M2.7 as an agent in its own RL training pipeline - not recursive self-improvement
What MiniMax Actually Built
The architecture is a Mixture of Experts model with 2,300 billion total parameters and 100 billion active per forward pass. Context length sits at 200K tokens - about 307 pages of dense text. Output tokens cap at 204,800.
Two API variants are available: standard M2.7 and M2.7-highspeed, which MiniMax says delivers the same results faster. Both support automatic caching with no configuration needed.
Benchmark Performance
The numbers are strong across several coding and agentic benchmarks.
| Benchmark | M2.7 | GPT-5.3-Codex | Claude Opus 4.6 |
|---|---|---|---|
| SWE-bench Verified | 78% | ~78% | ~75% |
| SWE-Pro | 56.22% | ~56% | - |
| MLE-Bench Lite (medal rate) | 66.6% | - | 75.7% |
| Artificial Analysis Index | #1 / 136 | - | - |
| Toolathon Accuracy | 46.3% | - | - |
| Terminal Bench 2 | 57.0% | - | - |
The SWE-bench Verified score of 78% puts M2.7 in the top tier for autonomous software engineering tasks. The MLE-Bench Lite medal rate of 66.6% shows competitive machine learning engineering performance, though it sits behind Claude Opus 4.6 at 75.7%.
Multi-Agent Architecture
M2.7 ships with native "Agent Teams" support - structured multi-agent collaboration where different instances take on specialized roles. MiniMax reports a 97% skill adherence rate across 40+ complex skills, including tool calls with definitions passing 2,000 tokens. The model also features adaptive task decomposition for routing subproblems across agent teams.
 MiniMax's official announcement for M2.7, released March 18, 2026.
Source: filecdn.minimax.chat
MiniMax's official announcement for M2.7, released March 18, 2026.
Source: filecdn.minimax.chat
The Self-Evolution Claim
This is where the press release language diverges from the engineering reality.
MiniMax describes M2.7 as "self-evolving" and credits it with achieving a 30% performance improvement through autonomous scaffold optimization. The framing is dramatic. The underlying mechanism is more specific: MiniMax deployed M2.7 as an agent within their RL training pipeline, where it autonomously reads logs, debugs issues, analyzes metrics, and adjusts hyperparameters across extended runs without human intervention.
That is truly useful. The model effectively is a research engineer inside its own training loop, discovering parameter combinations that improve its next version. MiniMax calls this "Early Echoes of Self-Evolution" in their announcement - a phrase that acknowledges the claim's ambition while hedging against the obvious counterargument.
It isn't recursive self-improvement in the way science fiction describes it. It's a model acting as an agent within a structured RL harness to partially automate workflow optimization. The distinction matters, because the former would be a historic safety event and the latter is a truly interesting but bounded engineering milestone.
The 100+ iteration figure refers to optimization cycles within a controlled training scaffold, not open-ended autonomous runs. MiniMax hasn't published the full methodology, so independent verification isn't yet possible.
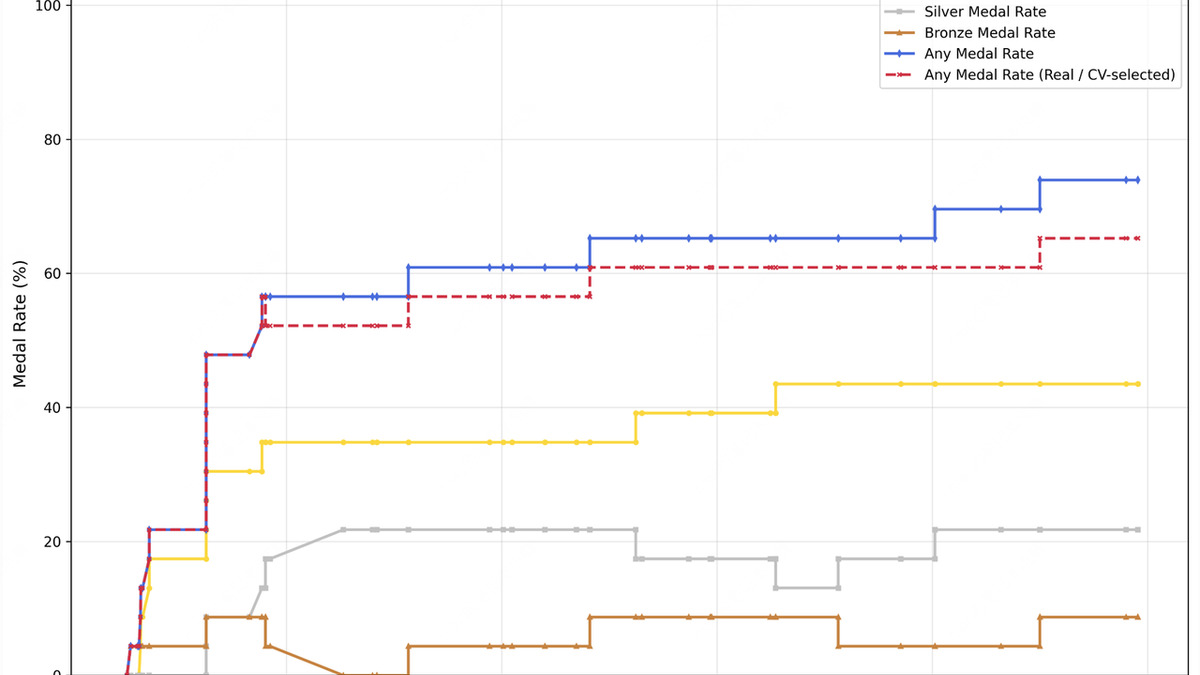 MLE-Bench Lite medal rate comparison from MiniMax's official announcement. M2.7 scores 66.6%, second to Claude Opus 4.6 at 75.7%.
Source: filecdn.minimax.chat
MLE-Bench Lite medal rate comparison from MiniMax's official announcement. M2.7 scores 66.6%, second to Claude Opus 4.6 at 75.7%.
Source: filecdn.minimax.chat
API and Pricing
M2.7 is live via the MiniMax API at:
- Input: $0.30 per million tokens
- Output: $1.20 per million tokens
- Blended with cache: $0.06 per million tokens
The pricing is competitive with comparable frontier models. Caching support is automatic, which helps for multi-turn agent workloads where context accumulates across calls.
An interactive demo environment called OpenRoom is available for no-code testing, alongside the standard API endpoint at https://api.minimax.io/v1/text/chatcompletion_v2.
What It Does Not Tell You
Speed is a real problem
Third-party evaluation by Artificial Analysis measured M2.7 at 49.7 tokens per second - MiniMax's own marketing claims 100 TPS. For reference, that puts M2.7 at roughly rank 98 of 136 models by throughput. Time to first token sits between 2.95 and 3.04 seconds. For interactive applications or high-volume pipelines, those numbers matter more than benchmark scores.
The M2.7-highspeed variant presumably addresses this, but no independent benchmarks for it are available yet.
The model is very verbose
Artificial Analysis found M2.7 produced roughly 87 million output tokens during their Intelligence Index testing, against an average of 20 million for comparable models. That's roughly four times the typical output volume. At $1.20 per million output tokens, verbosity has direct cost consequences. Users with token budgets should plan for notably higher burn rates than similar-tier models.
Context limits cause early exits
MiniMax acknowledges that M2.7 tends to terminate tasks early when it's approaching the edges of its context window. For complex agentic workflows that accumulate context across many steps, this is a real operational constraint.
The distillation controversy lingers
MiniMax was named in Anthropic's February investigation into distillation attacks - a finding that accused the company of running 13 million fraudulent exchanges with Claude to extract training signals. MiniMax didn't respond publicly to that report. M2.7's coding capabilities are strong enough that distillation from top proprietary models can't be ruled out as a contributing factor, even though the final model is clearly a major independent engineering effort.
The benchmark ceiling
The Artificial Analysis Intelligence Index ranking is real, but it's a composite score across many dimensions. On MLE-Bench Lite - arguably the most demanding real-world ML evaluation - M2.7 trails Claude Opus 4.6 by nine percentage points. The model excels at software engineering tasks specifically. Its general reasoning and science performance, outside the coding-heavy benchmarks, is less well characterized in publicly available evaluations.
M2.7 is the best coding-focused model MiniMax has shipped, and the Artificial Analysis composite ranking is a real achievement. The "self-evolving" framing will generate attention, but the more accurate description is a well-engineered agentic RL pipeline. Whether the underlying training methodology is reproducible - and whether it was developed without additional help from competitors' models - are questions that won't be answered until independent researchers dig into the weights. The weights haven't been released.
Sources:

