Microsoft Open-Sources Harrier, a New Embedding Leader
Microsoft's Harrier-OSS-v1 family delivers three MIT-licensed multilingual embedding models, with the 27B variant claiming top spot on Multilingual MTEB v2 at 74.3.

Microsoft dropped a new family of multilingual text embedding models on Hugging Face on March 30 with no blog post, no press release, and no social media fanfare. Three models, all MIT-licensed, covering a range from 270 million to 27 billion parameters. The largest claims state-of-the-art on Multilingual MTEB v2 with a score of 74.3 - above every open-weight model with commercial-friendly licensing.
Key Specs: Harrier-OSS-v1 Family
| Model | Params | Embedding Dim | Context | MTEB v2 |
|---|---|---|---|---|
| harrier-oss-v1-270m | 270M | 640 | 32,768 tok | 66.5 |
| harrier-oss-v1-0.6b | 600M | 1,024 | 32,768 tok | 69.0 |
| harrier-oss-v1-27b | 27B | 5,376 | 32,768 tok | 74.3 (SOTA) |
- Released March 30, 2026, under MIT license across all three sizes
- 94 languages supported, 32,768-token context window on every variant
- Available via
sentence-transformersand HuggingFacetransformers
Three Models, Three Scenarios
The family covers the deployment range that matters in production: a 270M model that runs on practically anything, a 0.6B mid-tier for constrained cloud budgets, and a 27B variant for teams with a full GPU node to spare.
The 27B: Benchmark Territory
The 27B variant scores 74.3 on Multilingual MTEB v2. That puts it above Alibaba's Qwen3-Embedding-8B (70.58), NVIDIA's NV-Embed-v2 (non-commercial license, ~69-72 depending on variant), and well ahead of OpenAI's text-embedding-3-large (64.6). The 5,376-dimensional output vector is large by current standards, giving the model room to represent fine-grained semantic distinctions across 94 languages.
Running 27B at BF16 precision will need 80GB+ VRAM. Microsoft doesn't document quantization options in the model cards, so hardware-constrained deployments will need community GGUF or AWQ conversions once they appear.
The 0.6B: The Production Default
At 600M parameters, the 0.6B scores 69.0 - beating OpenAI's API-only option by a meaningful margin while fitting on consumer hardware or a mid-range cloud instance. For most RAG pipelines, this is the sensible starting point. Microsoft used knowledge distillation from a larger model to reach that score at low parameter count, which explains why it punches well above its weight class.
The 270M: Edge and Offline Workloads
The 270M scores 66.5 and still beats OpenAI text-embedding-3-large, which costs money per call. For teams embedding large document corpora offline, running local semantic search on consumer hardware, or shipping on-device, this is the tier to benchmark first. Like the 0.6B, it's distilled from a larger model.
 MTEB scores across task categories for top embedding models - Harrier-27B claims the top position on Multilingual MTEB v2 as of March 2026.
Source: geeksforgeeks.org
MTEB scores across task categories for top embedding models - Harrier-27B claims the top position on Multilingual MTEB v2 as of March 2026.
Source: geeksforgeeks.org
Architecture: Decoder-Only, Not BERT
Most production embedding models use encoder-only (BERT-style) or bi-encoder architectures. Harrier-OSS-v1 takes a different approach: a decoder-only transformer with last-token pooling and L2 normalization - the same architectural family as generative LLMs.
Why Decoder-Only?
Encoder-only models are trained with bidirectional attention that sees the full input in both directions. Decoder models read left-to-right, which seems like a disadvantage for embeddings. But recent work from E5-Mistral, GTE-Qwen2, and NVIDIA's Llama-Embed-Nemotron line has shown that large decoder models fine-tuned with contrastive learning can beat bidirectional models on retrieval tasks when they have enough capacity.
Last-token pooling means the final non-padding token's hidden state represents the full sequence. At 32,768 tokens of context, this matters for long-document retrieval where older models max out at 512 tokens or, at best, 8,192.
Using the Models
Queries need a task instruction prefix. Documents don't. The model card provides three preconfigured prompt names - web_search_query, sts_query, and bitext_query - for the most common use cases. Via sentence-transformers:
from sentence_transformers import SentenceTransformer
model = SentenceTransformer(
"microsoft/harrier-oss-v1-27b",
model_kwargs={"dtype": "auto"}
)
query_embeddings = model.encode(queries, prompt_name="web_search_query")
document_embeddings = model.encode(documents)
scores = (query_embeddings @ document_embeddings.T) * 100
For custom task types, the instruction format is: Instruct: {task_description}\nQuery: {query}. Skipping the instruction on queries degrades performance - the model card is explicit about this.
How It Fits Into RAG and Agent Memory
Embedding models are the component that turns text into searchable vectors. Every RAG pipeline depends on them: chunk your documents, embed them, store in a vector database, then embed the query at runtime and find the nearest chunks. Agent memory systems use the same mechanism to let AI agents recall past interactions.
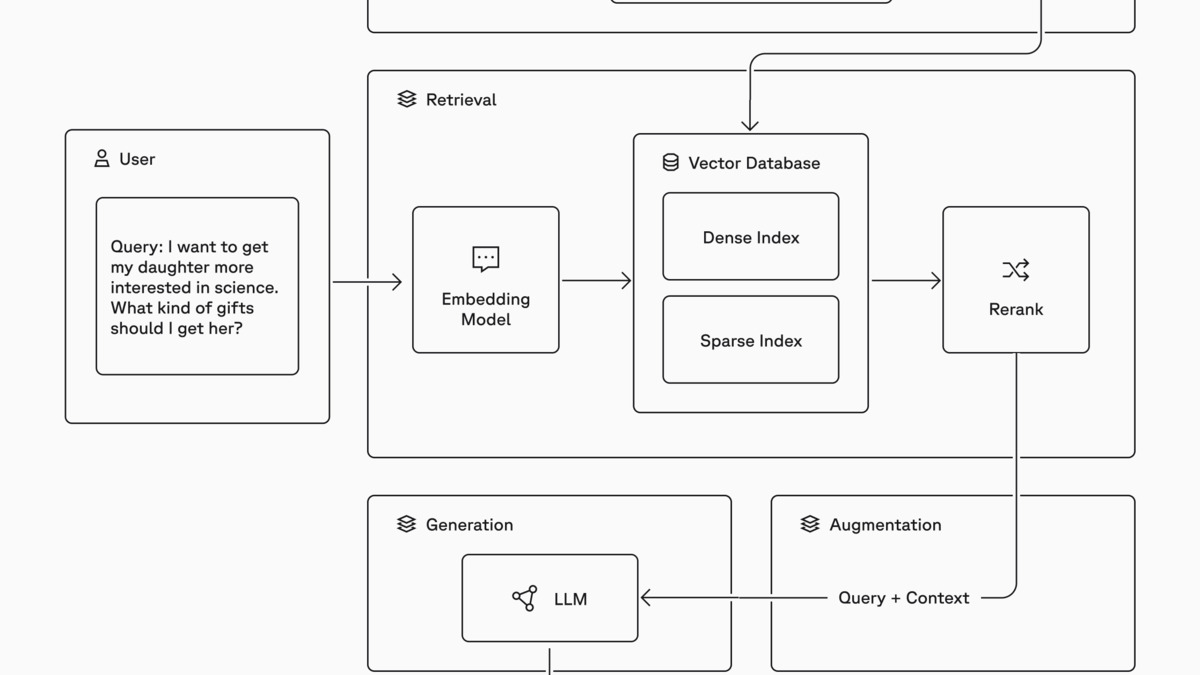 A typical RAG pipeline: documents are chunked, embedded, and stored in a vector index. At query time the same embedding model encodes the question, retrieves relevant chunks, and passes them as context to the LLM.
Source: pinecone.io
A typical RAG pipeline: documents are chunked, embedded, and stored in a vector index. At query time the same embedding model encodes the question, retrieves relevant chunks, and passes them as context to the LLM.
Source: pinecone.io
For teams building multilingual applications - enterprise knowledge bases in multiple languages, international customer support agents, cross-lingual search - embedding quality across languages is a bottleneck that API-based solutions often handle poorly. OpenAI's text-embedding-3-large caps at 8,192 tokens and isn't optimized for low-resource languages. Cohere's embed-v4 requires an API contract. Harrier's MIT license and 94-language support changes that calculus.
MTEB v2 Comparison
| Model | Size | Score | License | How to Deploy |
|---|---|---|---|---|
| harrier-oss-v1-27b | 27B | 74.3 | MIT | Self-hosted |
| harrier-oss-v1-0.6b | 600M | 69.0 | MIT | Self-hosted |
| Qwen3-Embedding-8B | 8B | 70.58 | Apache 2.0 | Self-hosted |
| Gemini Embedding 001 | API | 68.32 | Commercial | API only |
| harrier-oss-v1-270m | 270M | 66.5 | MIT | Self-hosted |
| Cohere embed-v4 | API | ~65.2 | Commercial | API only |
| OpenAI text-embedding-3-large | API | 64.6 | Commercial | API only |
| BGE-M3 (BAAI) | ~570M | 63.0 | MIT | Self-hosted |
Scores aren't all from the same benchmark version - the 74.3 Harrier figure is specifically Multilingual MTEB v2, while several competitor scores come from the general MTEB leaderboard. The MTEB leaderboard tracks the full picture. NVIDIA's NV-Embed-v2 family posts competitive numbers but carries a CC-BY-NC-4.0 license that blocks commercial use.
What To Watch
No technical paper. The release shipped with only model cards - no arXiv preprint, no Microsoft Research blog post. Training data, architecture hyperparameters, and evaluation methodology are undisclosed. That's a real gap for teams doing compliance or due diligence before launching in production. A paper may follow, but without it there's no way to independently audit for benchmark contamination on MTEB evaluation sets.
Quantization is community territory. BF16 is the only documented format. GGUF and AWQ conversions will appear on Hugging Face once the community picks this up, but they aren't available as of the release date. Teams planning to run this on hardware that can't hold 27B in BF16 should wait.
Per-language performance isn't broken out. The model card claims 94 languages but doesn't publish per-language scores. MTEB v2 averages across languages, and high-resource languages like English, French, and German will drag up the average. Tail languages in the 94-language set may perform significantly worse. Real-world testing on the target language is the only reliable check.
Google dropped its own multilingual embedding play last month with Gemini Embedding 2, which supports up to 8,192 tokens but sits behind an API. Harrier's self-hostable, MIT-licensed alternative - especially at the 0.6B tier - gives development teams a practical exit from per-token pricing for embedding workloads.
Sources:

