Microsoft Launches Polaris and Foundry Local at Build 2026
Microsoft's Build 2026 keynote ships Project Polaris to replace GPT-4 in GitHub Copilot by August and declares Foundry Local generally available for zero-cloud on-device inference.

Two separate infrastructure moves came out of Microsoft's Build 2026 keynote Monday in San Francisco, and they're aimed at different parts of the stack. Project Polaris, an in-house mixture-of-experts coding model, will replace GPT-4 Turbo as the default engine in GitHub Copilot starting August 2026 - running on Microsoft's own Maia AI accelerators and ending the inference dependency on OpenAI. Alongside it, Foundry Local reached general availability: a ~20 MB embeddable AI runtime that runs on Windows, macOS Apple Silicon, and Linux x64 with no cloud subscription, no per-token cost, and no separate daemon process to manage.
Neither announcement is a model launch in the traditional sense. Both are infrastructure bets - Microsoft is building end-to-end ownership of its AI delivery stack, from the silicon to the runtime to the models to the products on top.
TL;DR
- Project Polaris (MoE architecture, Maia accelerators) replaces GPT-4 Turbo in GitHub Copilot from August 2026; three-month GPT-4 fallback available before the cutover
- Foundry Local hits GA as a ~20 MB in-process runtime across Windows, macOS, and Linux - no daemon, no Azure account, no per-token cost
- ONNX Runtime backend; Microsoft claims 3.9x average throughput advantage over llama.cpp
- Azure AI Foundry GA adds visual RAG designer, per-project token budgets, Cohere/Mistral/Stability AI in the catalog
- Windows Agent Framework v1.0 ships MIT-licensed with YAML-defined agents scaling from laptop to Azure Arc
Foundry Local GA
Foundry Local entered public preview at Build 2025 and hit general availability on April 9, 2026. Microsoft announced the GA milestone again at Build 2026 to give it developer conference visibility.
The product isn't aimed at power users who want to run arbitrary models on a home server. It's a distribution mechanism for developers who want to ship AI inside their applications without asking end users to install anything separately. The entire runtime adds about 20 MB to an application package. On first launch, Foundry Local pulls the best-performing model variant for the user's hardware from a curated catalog, caches it locally, and later launches use the cached version with no network round-trip.
pip install foundry-local-sdk
npm install foundry-local-sdk
dotnet add package Microsoft.AI.Foundry.Local
cargo add foundry-local-sdk
The API is OpenAI-compatible, including the Responses API format - applications already using the OpenAI SDK can point to a local Foundry endpoint with minimal code changes. Hardware detection and execution provider selection are automatic: Windows ML on Windows (GPU, NPU, or CPU fallback), Metal on macOS Apple Silicon. Linux x64 defaults to CPU; GPU support for Linux is listed as upcoming but without a date.
What Runs Locally
The model catalog at GA includes Phi (Microsoft), Qwen, DeepSeek, Mistral, and Whisper for audio transcription. This is intentionally narrow. Microsoft positions it as a production catalog - every model goes through quantization and hardware compatibility testing - not a general model hub. If you need a fine-tuned variant, a recently released model not yet in the catalog, or anything in GGUF format, Foundry Local won't handle it.
Hardware Requirements
| Requirement | Minimum | Recommended |
|---|---|---|
| RAM | 8 GB | 16 GB |
| Free disk space | 3 GB | 15 GB |
| Windows | Windows 10/11 | Windows 11 |
| macOS | Apple Silicon only | Apple Silicon |
| Linux | x64, CPU only | x64 |
Models larger than 7B parameters need 16 GB of RAM in practice regardless of what the spec sheet says. The 8 GB minimum applies to smaller models only.
How It Differs From Ollama
Foundry Local runs in-process with the calling application. Ollama requires a running daemon that exposes a HTTP server. That distinction matters for application developers more than for developers running models on a local machine for their own use.
Microsoft claims the ONNX Runtime backend is on average 3.9x faster than llama.cpp. The comparison involves ONNX-optimized model variants rather than GGUF files, so the two aren't identical inputs - but the architectural difference is real. No HTTP overhead, no separate process to manage, no port conflicts. For an embedded AI use case in a desktop application, that's a cleaner integration story.
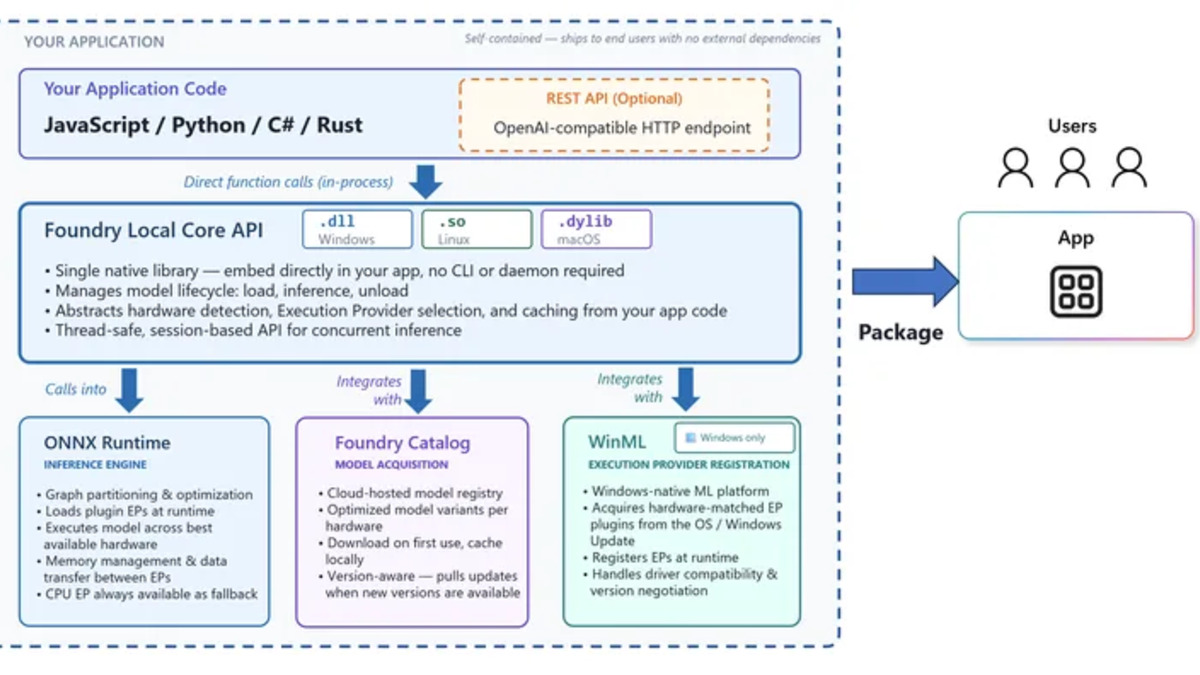 Foundry Local's layered architecture: SDK calls (Python/JS/C#/Rust) go into a native core library that manages model lifecycle and dispatches to Windows ML, Metal, or CPU execution providers.
Source: devblogs.microsoft.com
Foundry Local's layered architecture: SDK calls (Python/JS/C#/Rust) go into a native core library that manages model lifecycle and dispatches to Windows ML, Metal, or CPU execution providers.
Source: devblogs.microsoft.com
Project Polaris: GPT-4 Out of Copilot by August
Project Polaris is Microsoft's in-house coding model. The technical details released so far: mixture-of-experts architecture with sub-modules specialized by programming language, running on Maia AI accelerators inside Azure. Microsoft says it outperforms GPT-4 Turbo on HumanEval and MBPP, with the largest gains in low-resource languages including Rust and Haskell. Those benchmark figures are Microsoft's own - no independent validation at publication time, and SWE-bench scores haven't been disclosed.
The migration schedule is fixed. All Copilot subscribers move to Polaris starting August 2026. A three-month fallback to GPT-4 Turbo is available, but it requires configuration before the cutover date. Post-August, the option disappears.
What Polaris Changes for Pro Subscribers
Pro tier subscribers gain two capabilities with the Polaris rollout: multi-file context up to 100,000 lines across a repository (up from much smaller limits on GPT-4 Turbo), and autonomous test generation that runs without per-step confirmation. The VS Code extension adds parallel subagents - an orchestrator assigns linting, test generation, documentation, and security review to specialized subagents running simultaneously, surfacing results in a unified interface.
The commercial logic is plain. Every Copilot token call was an OpenAI API call. Polaris runs on Microsoft's own infrastructure, removing that cost entirely. The company hasn't announced whether Copilot subscriber pricing changes as a result. That omission is standout given that token-based billing already shocked enterprise Copilot customers last week when flat-rate subscriptions switched to consumption pricing.
Polaris is the logical next step in the direction Microsoft signaled in April when it launched MAI-Transcribe-1, MAI-Voice-1, and MAI-Image-2 - the company's first homegrown foundation models. The coding model closes the one gap that mattered most commercially, since Copilot is the revenue-producing product where inference cost directly affects margin.
Azure AI Foundry GA and Windows Agent Framework
Azure AI Foundry hit general availability alongside Foundry Local. GA adds native multimodal pipeline support across text, image, video, and audio in a unified workflow; a visual drag-and-drop designer for RAG and fine-tuning configurations; per-project token budgets with configurable alert thresholds; and Cohere, Mistral, and Stability AI as first-party catalog options. Foundry IQ and Fabric IQ are new connector layers for pulling in external data sources.
The Fireworks AI partnership on Foundry from March - which brought DeepSeek, Kimi, and MiniMax models into the platform - feeds into this broader Foundry GA push.
Windows Agent Framework v1.0 shipped MIT-licensed, which wasn't highlighted in the keynote but matters for adoption. Agents are defined in YAML manifests, not tied to a specific runtime, and the framework handles orchestration across local Windows machines, Windows 365 Cloud PCs, and Azure Arc devices using the same definition files. The keynote demo showed a manifest for an agent monitoring a SharePoint library, extracting contract clauses from documents, and writing output to a Dynamics 365 record - running on a Windows 365 Agent Node with results appearing locally in under 10 seconds.
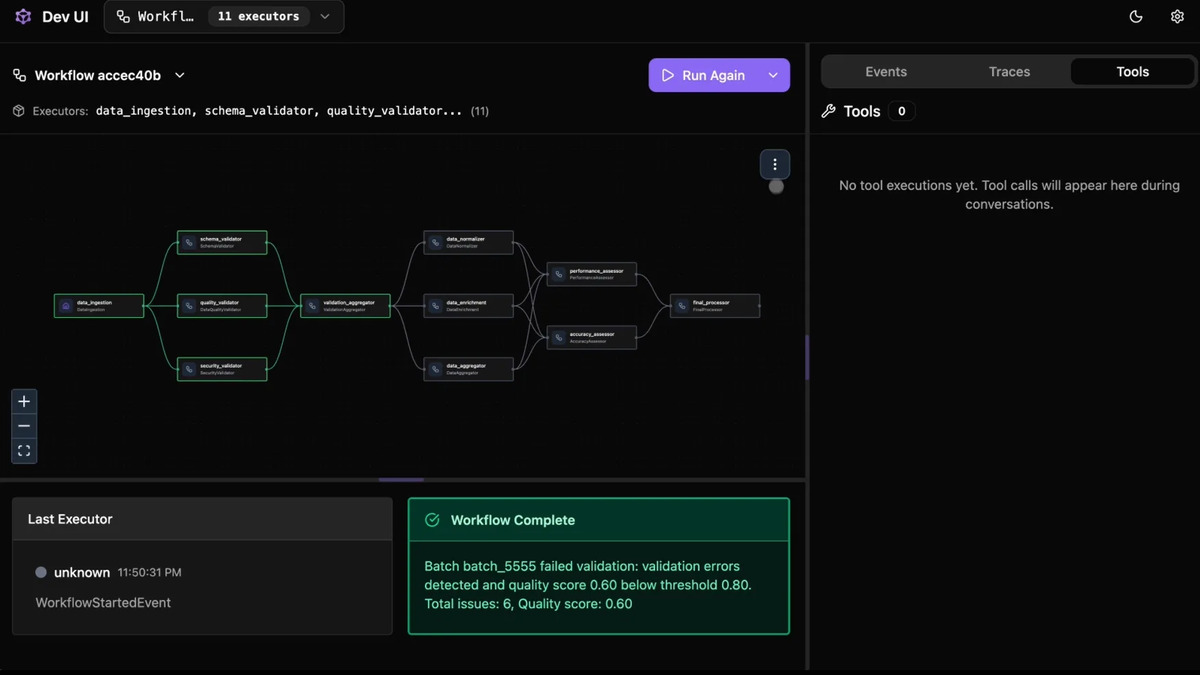 The Agent Framework DevUI shows YAML-based agent configuration with a live orchestration view. MIT licensing removes the standard enterprise adoption blocker for open-source tooling.
Source: devblogs.microsoft.com
The Agent Framework DevUI shows YAML-based agent configuration with a live orchestration view. MIT licensing removes the standard enterprise adoption blocker for open-source tooling.
Source: devblogs.microsoft.com
The Windows Agent Store launches with a preview of the Windows Agent Runtime (OS-level native agent APIs, currently in Windows Insider builds), with an 85% revenue share for publishers.
Where It Falls Short
Foundry Local catalog breadth. The curated catalog approach is the right call for production application deployment, but it creates a gap for teams that need models the catalog doesn't include. Fine-tuned variants, newly released open-weight models, and GGUF format are all out of scope. Developers who need flexibility use Ollama or llama.cpp instead; Foundry Local isn't trying to compete there.
Linux GPU support. The Linux x64 path runs on CPU regardless of available GPU hardware. For developers on Linux workstations - a common setup among the engineers most likely to reach for a tool like Foundry Local - this is a real limitation. No timeline announced.
Polaris benchmarks need external validation. Microsoft cited HumanEval and MBPP improvements over GPT-4 Turbo using its own benchmark data. Until independent evaluators publish results against Polaris on standard benchmarks including SWE-bench Verified, treat the performance figures as preliminary. The gap between vendor-reported and externally audited benchmark scores on coding models has been wide enough in the past to matter.
No Anthropic in the Foundry catalog. Azure AI Foundry GA doesn't include Claude as a first-party option, despite the Microsoft-Anthropic partnership. The gap is notable given that Microsoft dropped Claude integration from Copilot desktop earlier this year. The commercial relationship is clearly being restructured in ways that haven't been publicly spelled out.
Project Polaris's August ship date is the near-term thing to watch. A model with unvalidated benchmarks replacing the default engine for millions of Copilot users is a significant deployment. The three-month fallback window suggests Microsoft knows that and is giving enterprise customers an exit ramp - the question is how many use it.
Sources:
- Foundry Local is now Generally Available - Microsoft Foundry Blog
- What is Foundry Local? - Microsoft Learn
- GitHub Copilot Replaces GPT-4 With Project Polaris - TechTimes
- Microsoft Build 2026: Homegrown AI Models to Power GitHub Copilot - Windows News
- Microsoft Build 2026 Recap: Windows Is Now an Agent Platform - ChatForest
- Microsoft Agent Framework Version 1.0 - DevBlogs
- Microsoft Ships Foundry Local GA: A ~20MB Native Library - Lilting
