METR: Half of SWE-Bench Passes Fail Real Code Review
METR found maintainers would reject roughly half of AI PRs that pass SWE-bench automated grading, with a 24-point gap that suggests benchmark scores substantially overstate production readiness.

SWE-bench Verified has become the standard scoreboard for AI coding agents. When a new model ships, the first question most engineers ask is whether it makes a difference on SWE-bench. OpenAI publishes it. Anthropic publishes it. Leaderboards aggregate it. Investors quote it in pitch decks.
A new study from METR is now asking whether any of those numbers reflect what actually happens when an AI agent submits code to a real repository. The answer is a clear no - and the gap is larger than most practitioners assumed.
TL;DR
- Maintainers rejected roughly half of AI-generated PRs that passed SWE-bench automated grading
- The automated grader overstates merge rates by an average 24 percentage points across frontier models
- Claude 4.5's effective "time horizon" drops from 50 minutes (benchmark) to 8 minutes (maintainer review) - a 6x overestimation
- Primary rejection reasons: code quality, breaking unrelated code, and core functionality failures
- GPT-5 showed notably weaker code quality than Anthropic models in the study
- OpenAI is already moving to SWE-bench Pro as its recommended frontier eval
The Gap Between Grader and Maintainer
| Metric | Automated Grader | Maintainer Decision |
|---|---|---|
| Average pass/merge rate (frontier models) | ~72% | ~48% |
| Time horizon, Claude 4.5 | ~50 minutes | ~8 minutes |
| Annual improvement rate | baseline | 9.6 pp/yr slower |
| Golden patch (human-written) merge rate | n/a | 68% |
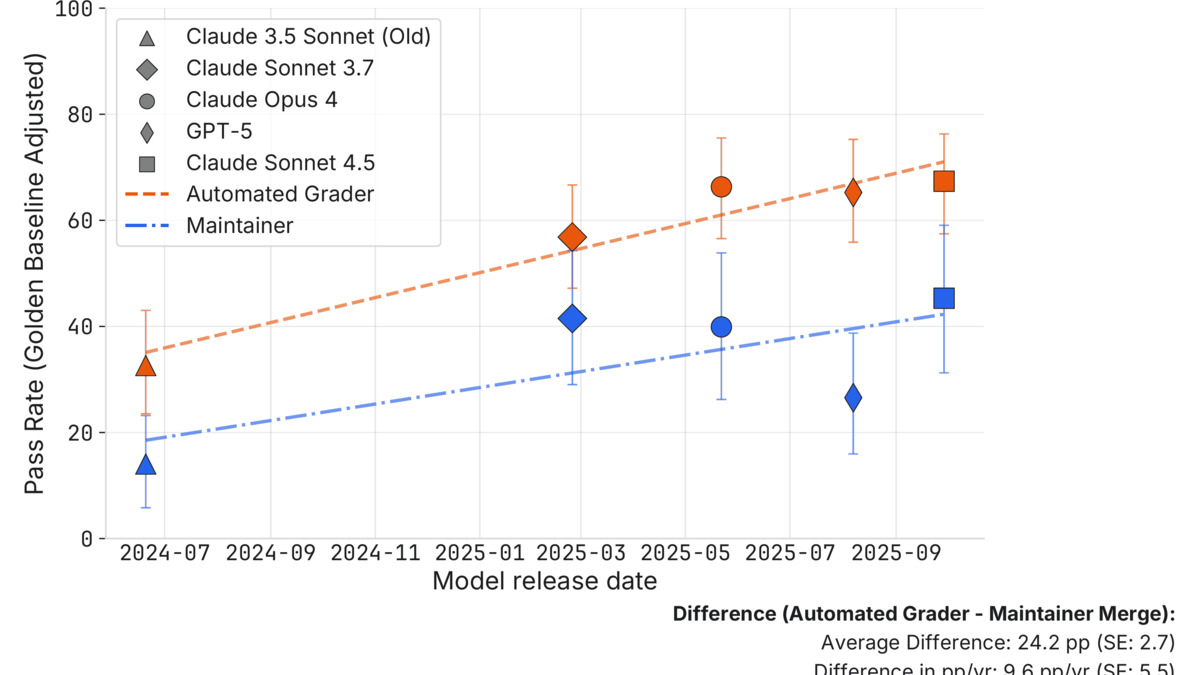 Pass rates over time: the orange line (automated grader) consistently runs 24 percentage points above the blue line (actual maintainer decisions).
Source: metr.org
Pass rates over time: the orange line (automated grader) consistently runs 24 percentage points above the blue line (actual maintainer decisions).
Source: metr.org
The study, published March 10 by Parker Whitfill, Cheryl Wu, Joel Becker, and Nate Rush, recruited four active maintainers from three SWE-bench Verified repositories: two from scikit-learn, one from Sphinx, one from pytest. The maintainers reviewed 296 AI-generated pull requests that had already passed the automated grader - working in historical repository states via GitHub, blinded to the source of each patch.
"Those forecasting AI progress and its real-world impact should view benchmarks as one piece of evidence, rather than as decisive."
- METR researchers, March 10 study
The 24 percentage point gap isn't a rounding error. On a benchmark that frontier models are now passing at 70-plus percent, a 24-point reduction in actual merge rates puts real-world performance at roughly the level the benchmark reported two years ago.
What They Measured
The Merge Rate Methodology
Each maintainer was paid hourly with quality bonuses and asked to give a binary accept/reject decision plus a structured reason for rejection. They weren't told whether a patch came from a human or a model. The baseline calibration ran against 47 golden patches - human-written PRs that were actually merged into main before the study. Maintainers accepted those at a 68% rate, which gives the experiment a real-world anchor.
The models tested span the recent generation of frontier coding agents: Claude 3.5 Sonnet (Old), Claude 3.7 Sonnet, Claude 4 Opus, Claude 4.5 Sonnet, and GPT-5. All had high automated pass rates before entering maintainer review.
Why Maintainers Rejected
The structured feedback identified three main buckets:
- Code quality issues - the patch didn't follow repository conventions, style, or idioms. The automated grader checks whether tests pass, not whether the code looks like it belongs in the codebase.
- Breaking other code - the patch fixed the target issue but caused failures elsewhere. SWE-bench only grades against the specific test suite for each issue.
- Core functionality failure - the patch appeared to pass grading but didn't actually solve the problem. The tests passed; the behavior didn't.
Code quality and collateral breakage were the bigger problems. On the GPT-5 results specifically, the authors note that it showed substantially weaker code quality than the Anthropic models tested.
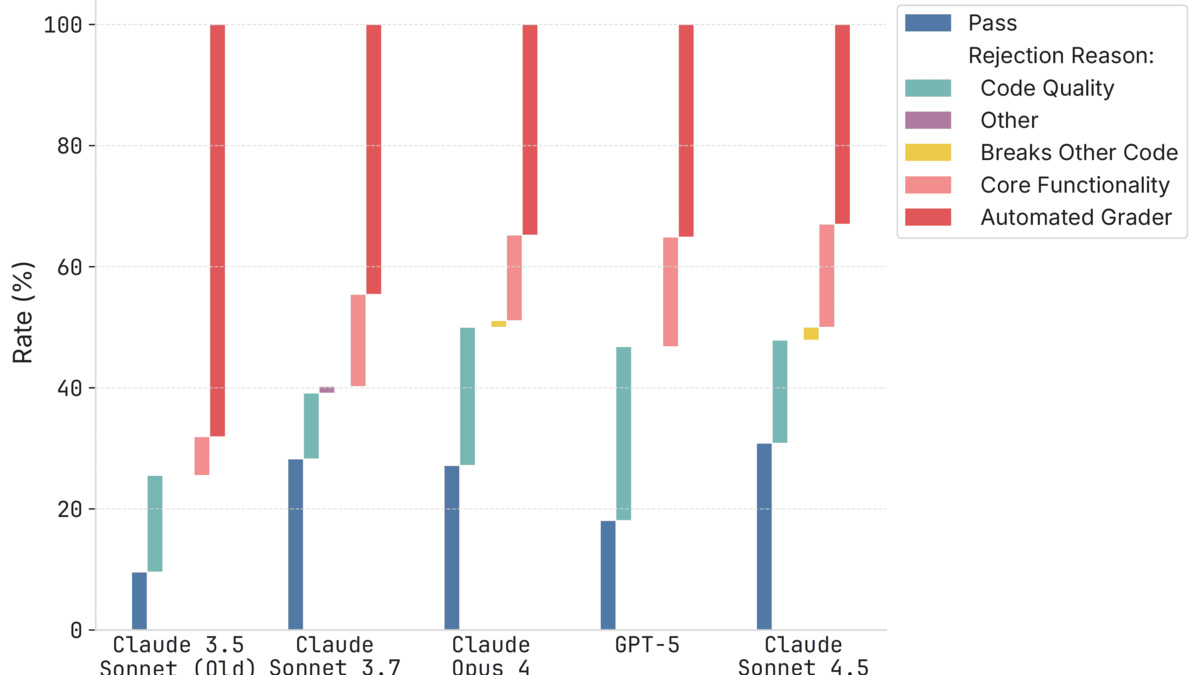 Rejection breakdown by model: code quality (dark) and breaking other code (mid) account for most failures across the board. GPT-5 shows a notably larger code quality failure share.
Source: metr.org
Rejection breakdown by model: code quality (dark) and breaking other code (mid) account for most failures across the board. GPT-5 shows a notably larger code quality failure share.
Source: metr.org
The Time Horizon Metric
METR uses a "time horizon" framing to measure effective agent capability - the duration of task a model can complete reliably. Against the automated grader, Claude 4.5 shows a ~50-minute time horizon. Under maintainer review, that collapses to ~8 minutes. The 6x overestimation means the benchmark is describing a meaningfully different (and more forgiving) environment than production code review.
A separate analysis by Entropic Thoughts applied Brier scoring to three models of AI coding progress using METR's data. The two models predicting constant or flat merge rates fit the data better than a linear growth trend - suggesting that despite benchmark scores rising through 2025, actual maintainer-accepted code quality may not have improved meaningfully.
What They Didn't
Coverage Is Narrow
The study covers 3 of 12 SWE-bench Verified repositories, across 95 of 500 issues. That's 19% of issues and 25% of repos. Scikit-learn, Sphinx, and pytest are all mature, style-conscious Python projects with established contribution conventions - which may make them harder on code quality than the full SWE-bench distribution. Different repos might show different gaps.
Single-Attempt Submissions
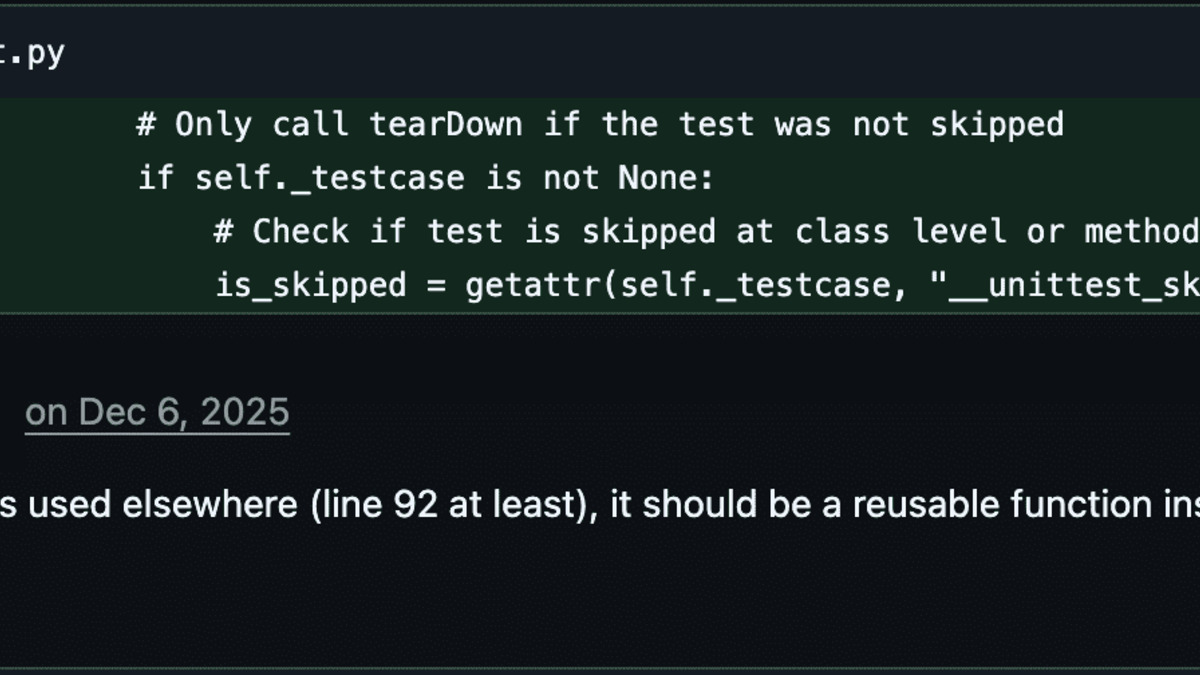 A real maintainer review on an AI-generated PR from the study - the patch passed the automated grader but was rejected for code quality concerns.
Source: metr.org
A real maintainer review on an AI-generated PR from the study - the patch passed the automated grader but was rejected for code quality concerns.
Source: metr.org
AI agents in this study submitted a patch once. Human developers iterate - they respond to reviewer comments, fix CI failures, refactor based on feedback. The comparison isn't fully symmetric. Joel Becker acknowledged this directly: an agent given reviewer feedback and the ability to resubmit might close a meaningful portion of the gap. That's also an argument for building agentic code review loops into evaluation methodology.
No CI Was Run
The maintainer review process didn't include running CI or verifying the full test suite. Some rejections may have flagged patches that would actually pass full automated testing. The authors note this as a limitation.
For context on what more realistic CI-integrated evals look like, Alibaba's SWE-CI benchmark tested 18 models across 233 days of maintenance and found that most agents build up technical debt over time - a related finding about the gap between pass-once and maintain-over-time performance.
Should You Care?
If you're building a product that relies on AI-generated code being merged into production repositories, yes. SWE-bench scores are a reasonable signal for comparing models against each other on a consistent task, but they don't tell you what fraction of patches will make it through human code review.
The practical implication isn't to stop tracking SWE-bench. It's to add a human-review layer to any evaluation pipeline that matters - or at minimum, to treat a model's SWE-bench score as the ceiling of its coding usefulness, not the floor.
OpenAI seems to be reading the same signal. The company recently announced it's moving from SWE-bench Verified to SWE-bench Pro as its recommended frontier coding eval - a harder benchmark with more realistic tasks. Whether Pro fares better on maintainer review than Verified isn't yet known.
This isn't an isolated finding. Gemini 3.1 Pro leads 13 benchmarks but runs into serious reliability problems in production, and SkillsBench found that small models with expert guides outperform frontier models on real-world tasks. The pattern is consistent: automated evals measure what automated evals measure, and real usage is something else.
For teams that have already started deploying AI coding agents on pull requests, Anthropic's multi-agent code review dispatches parallel agents to filter and rank patches before human review - which may be closer to how these tools need to operate to hit acceptable merge rates in practice.
METR's study covers a narrow slice of the full SWE-bench distribution. The 24-point gap may shrink across different repository types or widen further in codebases with stricter standards. What it removes is the ability to treat a high SWE-bench score as equivalent to high production code quality. Those are different things, and now there's data to show how different.
Sources:

