Meta SAM 3.1 - 7x Faster Multi-Object Video Tracking
Meta releases SAM 3.1 with Object Multiplex, processing all tracked objects in one shared pass for 7x faster inference at 128 objects and improvements on 6 of 7 VOS benchmarks.

Meta shipped SAM 3.1 on March 27, 2026, and the headline number is stark: at 128 simultaneously tracked objects, the updated model runs 7 times faster than SAM 3 on a single H100 GPU. The gain doesn't come from a new architecture or bigger training data - it comes from fixing a concurrency inefficiency that was baked into the original design.
The core change is called Object Multiplex. It's a joint processing approach that removes the extra computation each independent object pass was doing, and it lands without any accuracy tradeoff. Weights are available now on Hugging Face under SAM 3's existing license.
Key Specs
| Spec | Value |
|---|---|
| Architecture | Meta Perception Encoder + DETR detector + memory tracker |
| Parameters | 848M |
| Release date | March 27, 2026 |
| Object Multiplex speedup | ~7x at 128 objects (H100) |
| Throughput boost (mid-range) | 16 fps to 32 fps on H100 |
| VOS benchmarks improved | 6 of 7 |
| Largest gain | +2.0 on MOSEv2 |
| Weights | Gated - requires HuggingFace account + access request |
| License | SAM 3 research license |
| Python requirement | 3.12+ |
| PyTorch requirement | 2.7+ |
Object Multiplex - What Changed
The original problem
SAM 3's video tracker was architecturally clean but expensive at scale. Every tracked object got its own forward pass through the pipeline - memory reads, encoder operations, postprocessing, all repeated independently per object. At small object counts that's fine. At 16 or 32 objects it starts to hurt. At 128 objects you're paying for the same overhead over and over.
Object Multiplex solves this by grouping tracked objects into fixed-capacity buckets and running them jointly through a single shared-memory pass. The encoder computes once, the memory bank is read once, and the results get distributed across all objects in the bucket. GPU utilization goes up; unnecessary computation drops out.
The gains are nonlinear. At low object counts (under 8), the benefit is modest. At 128 objects on a single H100, Meta reports about a 7x inference speedup versus the November 2025 SAM 3 release. Throughput for medium object counts - the range most real production workloads hit - doubles from 16 fps to 32 fps.
Additional engineering in 3.1
Beyond Object Multiplex, the release includes three other improvements. CPU-GPU synchronization overhead in the detection-tracker handoff was reduced. torch.compile support was enhanced with better operation fusion, which matters for anyone running SAM 3 inside a larger vLLM-style inference stack. Postprocessing was batched end-to-end.
None of these are dramatic on their own. Together they compound the Object Multiplex gains and make the 3.1 upgrade worth taking for any production deployment tracking more than a handful of objects.
 SAM 3 tracking multiple objects across video frames. SAM 3.1 applies the same masks at 7x the throughput when tracking at scale.
Source: about.fb.com
SAM 3 tracking multiple objects across video frames. SAM 3.1 applies the same masks at 7x the throughput when tracking at scale.
Source: about.fb.com
Benchmark Results
VOS: Video Object Segmentation
SAM 3.1 improves on 6 of 7 VOS benchmarks compared to the November SAM 3 baseline. The biggest gain is on MOSEv2, a dataset built around heavily occluded and cluttered scenes where objects constantly overlap and disappear behind each other.
| Benchmark | SAM 3 | SAM 3.1 | Delta |
|---|---|---|---|
| MOSEv1 | 78.4 | 79.6 | +1.2 |
| DAVIS17 | 92.2 | 92.7 | +0.5 |
| LVOSv2 | 88.5 | 89.2 | +0.7 |
| MOSEv2 | 60.3 | 62.3 | +2.0 |
The MOSEv2 score is the one to note. The dataset is specifically designed to break trackers - it focuses on scenarios where conventional segmentation models lose track completely. A +2.0 gain there is more meaningful than a comparable gain on DAVIS17, which is a cleaner and easier benchmark.
Text-guided video (SA-Co/VEval)
SAM 3.1 also improves on Meta's own SA-Co/VEval evaluation suite, which uses open-vocabulary text prompts to query the model for arbitrary concepts in video. The biggest textual improvement is on YT-Temporal-1B, where cgF1 rises from 50.8 to 52.9.
| Dataset | Metric | SAM 3 | SAM 3.1 |
|---|---|---|---|
| SA-V | cgF1 | 30.3 | 30.5 |
| SA-V | pHOTA | 58.0 | 58.7 |
| YT-Temporal-1B | cgF1 | 50.8 | 52.9 |
| YT-Temporal-1B | pHOTA | 69.9 | 70.7 |
The Object Multiplex change is primarily an inference optimization, so accuracy gains here are smaller - they come from the batched postprocessing and encoder improvements rather than a fundamental model change.
Installing and Using SAM 3.1
Requirements
SAM 3.1 requires Python 3.12+, PyTorch 2.7+, and a CUDA 12.6+ GPU. The model fits on a 16 GB GPU - less VRAM than the original SAM 2.
conda create -n sam3 python=3.12
conda activate sam3
pip install torch --index-url https://download.pytorch.org/whl/cu126
git clone https://github.com/facebookresearch/sam3
cd sam3
pip install -e .
Accessing the weights
Weights are gated on Hugging Face. You'll need to request access at huggingface.co/facebook/sam3.1, wait for approval, then authenticate:
hf auth login
SAM 3.1 is a drop-in replacement for SAM 3 - no code changes needed if you're already running SAM 3 inference. The repo includes sam3.1_video_predictor_example.ipynb with point and text prompt examples using the new multiplexed tracker.
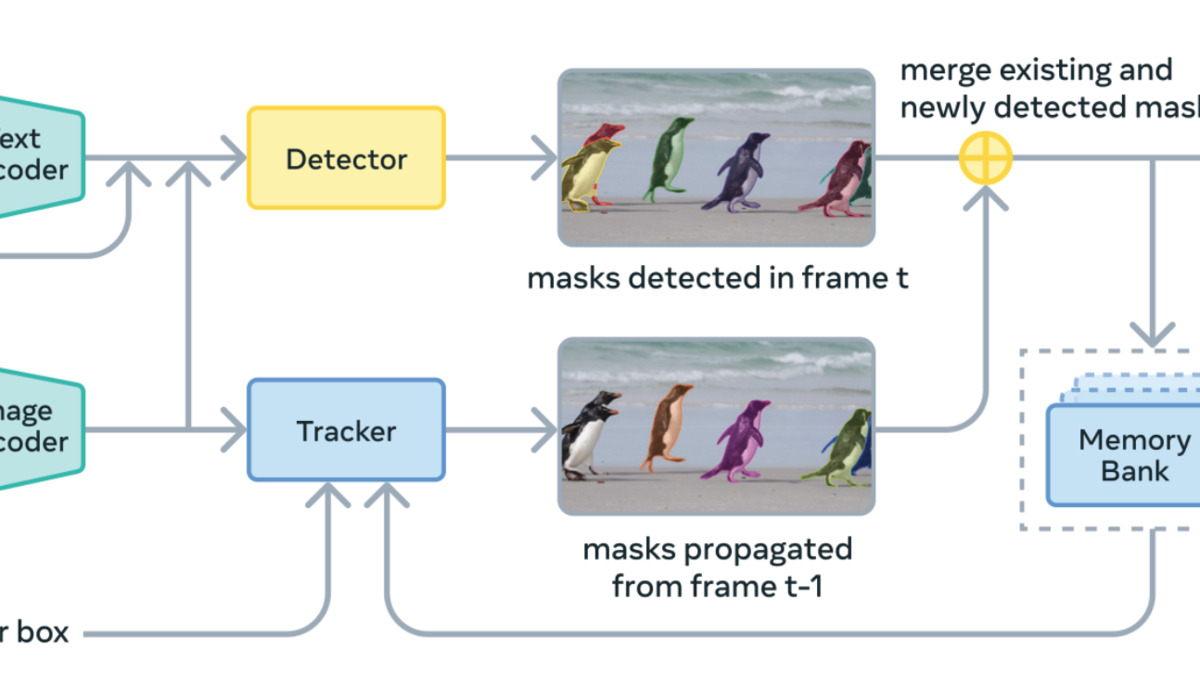 SAM 3 architecture: a shared Meta Perception Encoder drives both a DETR-based detector and a memory tracker. SAM 3.1 adds Object Multiplex to the tracker, letting all objects share a single encoder pass.
Source: github.com/facebookresearch/sam3
SAM 3 architecture: a shared Meta Perception Encoder drives both a DETR-based detector and a memory tracker. SAM 3.1 adds Object Multiplex to the tracker, letting all objects share a single encoder pass.
Source: github.com/facebookresearch/sam3
What To Watch
The Object Multiplex approach is described in Appendix H of the SAM 3 paper (arXiv:2511.16719, presented at ICLR 2026). The technical details are public, which means it's reproducible and could be adapted to other tracking architectures.
The access request requirement is worth flagging. The weights are gated rather than fully open - Meta controls who can download them, and approvals aren't instant. For a model positioned as an open-source research tool, the gated distribution adds friction that fully open-weight releases (like Mistral's Voxtral or Cohere Transcribe) don't have. Whether that matters depends on your use case.
There's no Hugging Face Transformers integration. All code lives in the facebookresearch/sam3 repo. That means no pipeline API, no .from_pretrained(), and less community tooling compared to models that land with native Transformers support.
For robotics teams working on real-time scene understanding - the kind of multi-object tracking that underpins open-source humanoid systems - SAM 3.1's doubled throughput at medium object counts is a meaningful shift. 32 fps on a single H100 is fast enough to pipeline tracking with other inference workloads without a dedicated GPU.
Meta credits Arpit Kalla, Chaitanya Ryali, Christian Puhrsch, Ho Kei Cheng, Joseph Greer, Meng Wang, Miran Heo, Pengchuan Zhang, Roman Radle, and Yuan-Ting Hu on the SAM 3.1 release.
Sources:

