Meta Muse Spark Launches, Ranks 4th Among Frontier Models
Meta Superintelligence Labs releases Muse Spark, its first AI model built from scratch in nine months, landing 4th on the Artificial Analysis Intelligence Index.

Nine months. That's how long Meta Superintelligence Labs took to scrap its entire AI stack and build a new one from the ground up. The result is Muse Spark, Meta's first model under Chief AI Officer Alexandr Wang - and it debuts not as an open-weight release, but as a closed proprietary system rolled out directly into Meta's consumer apps.
The model lands 4th on the Artificial Analysis Intelligence Index with a score of 52, behind Gemini 3.1 Pro, GPT-5.4, and Claude Opus 4.6. That puts Meta back in the frontier conversation after Llama 4's underwhelming reception last year, but it doesn't unseat the current leaders. What makes the launch worth studying is where Muse Spark wins - and where it still doesn't.
TL;DR
- Meta Superintelligence Labs ships its first model, Muse Spark, built from scratch in nine months
- Ranks 4th on the Artificial Analysis Intelligence Index (score: 52), trailing Gemini 3.1 Pro, GPT-5.4, and Claude Opus 4.6
- Leads on HealthBench Hard (42.8%), FrontierScience (38.3%), and Humanity's Last Exam (50.2%)
- Falls short on abstract reasoning and coding - ARC-AGI-2 at 42.5 vs Gemini's 76.5
- Available now in Meta AI app, Facebook, Instagram, and Threads; closed-source at launch
The Benchmark Picture
Muse Spark's performance is uneven in the most interesting way. It beats the current frontier on health and science, and then loses badly on the tasks that matter most to developers.
| Benchmark | Muse Spark | GPT-5.4 | Gemini 3.1 Pro |
|---|---|---|---|
| HealthBench Hard | 42.8 | below 42.8 | below 42.8 |
| Humanity's Last Exam | 50.2 | 43.9 | 48.4 |
| FrontierScience | 38.3 | 36.7 | 23.3 |
| DeepSearchQA | 74.8 | n/a | 69.7 |
| ARC-AGI-2 | 42.5 | 76.1 | 76.5 |
| Terminal-Bench 2.0 | 59.0 | 75.1 | 68.5 |
The HealthBench Hard score is striking. Meta says it developed the health capabilities with input from 1,000 physicians, and the number suggests that collaboration produced something real. On the multimodal benchmarks leaderboard, Muse Spark also posts 86.4 on Figure Understanding, ahead of both GPT-5.4 (82.8) and Gemini 3.1 Pro (80.2).
The ARC-AGI-2 gap is harder to explain away. Scoring 42.5 when competitors sit at 76.1 and 76.5 isn't a rounding error. It's a 34-point deficit on the benchmark most closely associated with general reasoning.
Nine Months From Scratch
Wang announced the model with a degree of engineering transparency unusual for a hyperscaler launch. "Nine months ago we rebuilt our ai stack from scratch," he wrote. "New infrastructure, new architecture, new data pipelines."
 Alexandr Wang, Meta's Chief AI Officer, oversaw the nine-month ground-up rebuild of Meta's AI infrastructure.
Source: meta.com
Alexandr Wang, Meta's Chief AI Officer, oversaw the nine-month ground-up rebuild of Meta's AI infrastructure.
Source: meta.com
A Natively Multimodal Design
Muse Spark accepts voice, text, and image inputs. Output is text only - no voice synthesis, no image generation. Wang described it as "a natively multimodal reasoning model w/ support for tool-use, visual chain of thought, & multi-agent orchestration." The unified input framework is what enabled the compute efficiency Meta cites: the model reportedly hits comparable capability to Llama 4 Maverick using 10x less compute during pretraining.
Token efficiency backs this up. Artificial Analysis benchmarked Muse Spark at 58 million output tokens for the full Intelligence Index evaluation. Claude Opus 4.6's Adaptive Reasoning mode consumed 157 million tokens on the same suite. GPT-5.4 used 120 million. Whether that efficiency holds at scale in production is a different question, but the numbers from controlled eval are compelling.
Contemplating Mode
Meta's answer to GPT Pro and Gemini Deep Think is called Contemplating mode. Rather than a single reasoning chain, it runs multiple agents in parallel, coordinates their outputs, and returns a synthesized response. On Humanity's Last Exam without tools, the Contemplating mode score of 50.2 beats Gemini's Deep Think (48.4) and GPT-5.4 Pro (43.9). The agentic benchmarks leaderboard will likely track how this holds up in longer-horizon tasks.
Where Muse Spark Leads
Health is the clearest win. The 42.8 on HealthBench Hard isn't a narrow margin - it tops every other frontier model in the comparison. Zuckerberg framed this in consumer terms: "It's a world-class assistant and particularly strong in areas related to personal superintelligence like visual understanding, health, social content, shopping, games, and more."
On DeepSearchQA, Muse Spark's 74.8 beats Gemini 3.1 Pro's 69.7 by a meaningful margin, which matters given how Meta plans to use the model - as an agentic assistant that can search and act across Meta's app ecosystem, not just answer questions.
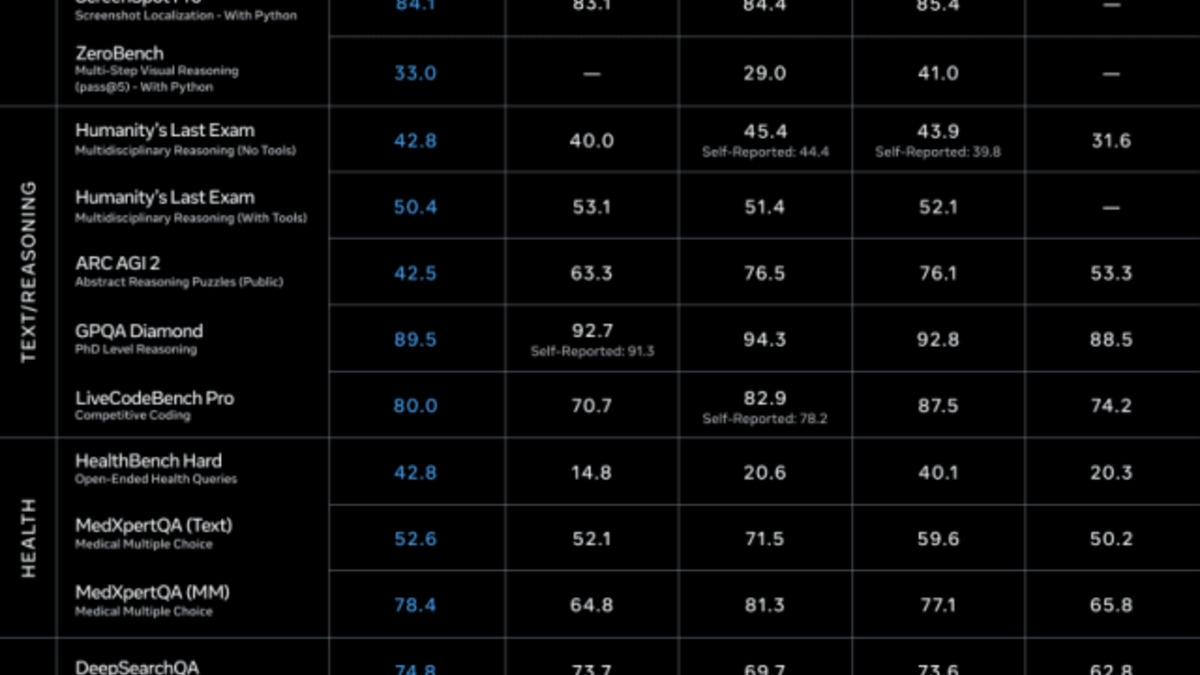 Muse Spark benchmark results compared to GPT-5.4, Gemini 3.1 Pro, and Grok 4.2 across health, reasoning, and search tasks.
Source: officechai.com
Muse Spark benchmark results compared to GPT-5.4, Gemini 3.1 Pro, and Grok 4.2 across health, reasoning, and search tasks.
Source: officechai.com
Where It Falls Short
The coding and abstract reasoning numbers are a real problem if Muse Spark is meant to compete across the board. Terminal-Bench 2.0 at 59.0 puts it 16 points behind GPT-5.4 and nearly 10 behind Gemini 3.1 Pro. For developers who use frontier models to produce and debug code, that gap is wide enough to steer toward alternatives.
The ARC-AGI-2 deficit is harder to dismiss as a niche concern. That benchmark measures novel pattern recognition - the kind of reasoning that doesn't benefit from having seen similar training examples. A 34-point gap compared to Gemini and GPT-5.4 suggests a structural limitation, not a data gap. Wang acknowledged rough edges: "There are certainly rough edges we will polish over time."
What It Does Not Tell You
Meta hasn't disclosed model parameters, training data details, or context window size. The closed-source decision, which this publication reported the day before launch, means independent researchers can't audit the architecture or probe for safety issues at weight level.
The health benchmark lead raises a specific question that Meta hasn't answered: was HealthBench Hard part of the evaluation suite used to guide training decisions? A model optimized toward a benchmark it's then compared against isn't the same as a model that generalizes well in clinical settings. Meta says 1,000 physicians contributed to health feature development, but the methodology behind that process isn't public.
The API access story is also incomplete. A private API preview for select partners was announced with the consumer rollout, but pricing, rate limits, and which partners are included haven't been disclosed. For enterprise teams assessing whether to build on Muse Spark's health or science capabilities, that's not a minor gap.
 Meta AI, now powered by Muse Spark, is rolling out across the Meta AI app, Facebook, Instagram, and Threads.
Source: 9to5mac.com
Meta AI, now powered by Muse Spark, is rolling out across the Meta AI app, Facebook, Instagram, and Threads.
Source: 9to5mac.com
Zuckerberg sketched the longer-term direction: "We are building products that don't just answer your questions but act as agents that do things for you." Muse Spark is the first model shipped under that framing - but the agentic capabilities on display today are search and tool-use, not autonomous multi-step action at the level competitors have demonstrated.
Muse Spark's health and science scores are the strongest argument that Meta Superintelligence Labs rebuilt something truly new rather than repackaging Llama infrastructure. The abstract reasoning and coding deficits are concrete, specific, and large enough that any developer evaluating the model for production use needs to test those dimensions directly before committing.
Sources: Meta announcement - Meta AI blog - Artificial Analysis - OfficeChai benchmark breakdown - TechCrunch - Interesting Engineering - Zuckerberg on Threads
Last updated

