Meta's KernelEvolve Automates Kernel Tuning in Production
Meta's KernelEvolve AI agent autonomously generates and optimizes hardware kernels across NVIDIA, AMD, and MTIA chips, delivering over 60% inference gains in production.

Meta published the full technical breakdown of KernelEvolve on April 2 - an AI agent that creates and improves low-level hardware kernels at production scale across NVIDIA GPUs, AMD GPUs, and Meta's custom MTIA silicon. The numbers are real: over 60% inference throughput improvement on their Andromeda ads model, over 25% training throughput gains on MTIA, and a 100% pass rate on KernelBench's 250 benchmark problems. The system has been running in production, serving trillions of daily inference requests.
Key Stats
| Metric | Result |
|---|---|
| Inference gain (NVIDIA, Andromeda) | 60%+ vs torch.compile baseline |
| Training gain (MTIA ads model) | 25%+ |
| KernelBench pass rate | 100% (250/250 problems) |
| Operators confirmed | 160 PyTorch ATen ops across 3 platforms |
| Hardware coverage | NVIDIA GPUs, AMD GPUs, MTIA 300-500 |
| Output languages | Triton, CuTe DSL, FlyDSL, CUDA, HIP, MTIA C++ |
| Paper | ISCA 2026 (arXiv:2512.23236) |
The Problem KernelEvolve Solves
Vendor libraries like cuBLAS cover standard operations well - GEMMs, convolutions, pooling. Meta's ads ranking stack uses a long tail of custom operators that exist in no vendor library: feature hashing, sequence truncation, fused feature interactions, specialized attention variants for ranking. Every new model architecture adds more.
The combinatorial math gets out of hand fast. The number of unique kernel configurations scales as hardware variants × model architectures × operator types. Meta is shipping four MTIA chip generations in two years - the 300 through 500 series. Running the old playbook of hand-tuned kernels from expert engineers doesn't work at that pace.
Why Not Just Use torch.compile?
torch.compile covers the general case reliably. But for Meta's custom operators on MTIA silicon, there's no compiler support, no vendor library, and the chip's architecture wasn't in any model's training data. The 60% NVIDIA inference gain is measured against a baseline that already uses torch.compile and vendor-provided kernels - KernelEvolve finds performance on top of what standard tooling can reach. That's a harder comparison point than most systems report.
Separately, ByteDance's CUDA Agent (which we covered in March) attacks a narrower version of the same problem using reinforcement learning trained on GPU profiling trajectories. CUDA Agent achieves a 2.11x improvement over torch.compile on their target workloads. KernelEvolve trades that focused benchmark performance for broader hardware coverage and the ability to target proprietary silicon that has never appeared in public training data.
Architecture Teardown
KernelEvolve has six components designed to compound - each one improves what the others can find.
LLM Synthesizer
The synthesizer produces candidate kernels across multiple languages: Triton and TLX for high-level GPU work, CuTe DSL and FlyDSL for closer-to-metal GPU operations, CUDA C++ and HIP for vendor-specific paths, and MTIA C++ for Meta's in-house chips. Prompts are dynamically constructed with runtime diagnostics and performance feedback from prior candidates in the same search session - not static templates.
A representative Triton kernel structure (illustrative of the system's output format, based on the published paper description) shows how KernelEvolve handles tiling and memory access for a fused operation:
import triton
import triton.language as tl
@triton.jit
def fused_feature_kernel(
x_ptr, w_ptr, out_ptr,
M, N, K,
stride_xm, stride_xk,
stride_wk, stride_wn,
BLOCK_M: tl.constexpr,
BLOCK_N: tl.constexpr,
BLOCK_K: tl.constexpr,
):
# Tile IDs determined by tree search based on profiler feedback
pid_m = tl.program_id(0)
pid_n = tl.program_id(1)
offsets_m = pid_m * BLOCK_M + tl.arange(0, BLOCK_M)
offsets_n = pid_n * BLOCK_N + tl.arange(0, BLOCK_N)
# Block sizes (BLOCK_M=128, BLOCK_N=64) are not hand-picked -
# the tree search engine selects them from profiler diagnostics
The synthesizer creates the kernel structure. The block sizes and memory access patterns are chosen by the tree search engine based on hardware profiler output.
Tree Search Engine
This is the component that separates KernelEvolve from one-shot code generation. It uses Monte Carlo tree search combined with evolutionary strategies. Each node in the tree carries a "configurable memory" controlling how it uses prior knowledge: inherit the parent trajectory, compare against sibling candidates, combine insights from both, or restart completely to escape a local optimum.
The search engine doesn't just observe that kernel A runs 1.2× faster than kernel B. It sees why - whether the bottleneck is memory bandwidth, compute throughput, or occupancy limits - and directs the next generation of candidates accordingly. The evaluation framework provides structured diagnostics, not just timing numbers.
 The tree search engine navigates the optimization space by combining MCTS with evolutionary strategies. Each node carries configurable memory that can inherit from parents, compare siblings, or restart to escape local optima.
Source: engineering.fb.com
The tree search engine navigates the optimization space by combining MCTS with evolutionary strategies. Each node carries configurable memory that can inherit from parents, compare siblings, or restart to escape local optima.
Source: engineering.fb.com
Retrieval-Augmented Knowledge Base
This is how KernelEvolve handles hardware it has never seen. Meta encodes MTIA's architecture manuals, memory hierarchy specifications, instruction sets, and optimization patterns into a hierarchical knowledge base. The LLM queries it at inference time - so it can write MTIA C++ code for a chip that postdates its training cutoff, by injecting the chip's documentation as context.
The paper describes a compounding effect the authors call "in-context reinforcement learning": successful optimizations are written back into the knowledge base as reusable skills. Early sessions explore the hardest problems; later sessions start from much better priors. It's closer to a curriculum memory system than RL in any technical sense, but the practical result is the same - the system improves without retraining.
Automated Evaluation Framework
Every candidate kernel gets confirmed on two dimensions: bitwise correctness against a reference implementation, and actual performance on real hardware. The framework uses TritonBench for Triton kernels, PyTorch Profiler and NCU for NVIDIA paths, Proton for instruction-level latency on NVIDIA, and MTIA Insight for Meta's custom silicon. The search engine gets structured diagnostics - not just throughput numbers but memory-bound vs compute-bound classification - which feeds directly into the next search iteration.
Meta validated 160 PyTorch ATen operators across three hardware platforms, producing 480 unique configurations. All passed correctness checks.
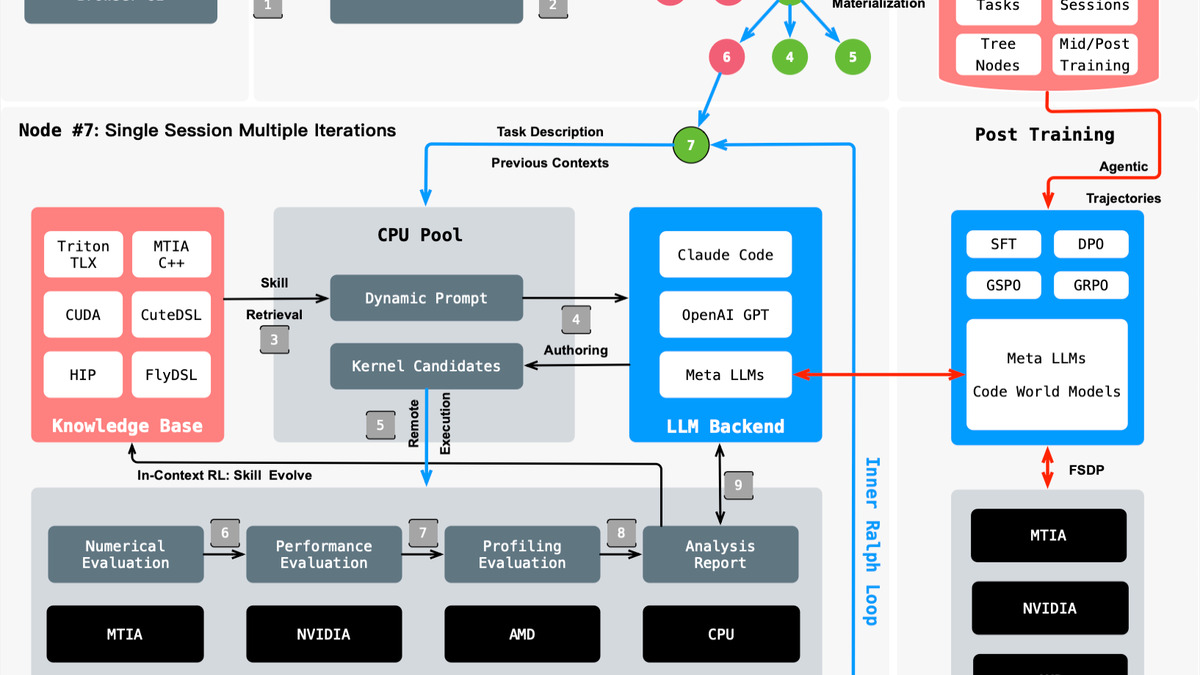 How a kernel optimization request flows through KernelEvolve's six components, from initial synthesis through evaluation, profiling, and knowledge base update.
Source: engineering.fb.com
How a kernel optimization request flows through KernelEvolve's six components, from initial synthesis through evaluation, profiling, and knowledge base update.
Source: engineering.fb.com
Shared Data Foundation and Agentic RL
Every session contributes its findings back to a shared pool available to future sessions. The system also generates structured training data from optimization trajectories - code transformations paired with evaluation feedback - used to post-train smaller specialized models with kernel performance as the reward signal. The flywheel is real: the system gets better over time without any human intervention.
Where KernelEvolve Fits in Meta's Infrastructure
KernelEvolve doesn't operate alone. It's the hardware execution layer of Meta's broader Ranking Engineer Agent (REA) system, described in a March 17 engineering post from Meta. REA operates at the ML model layer - it autonomously discovers better ranking model architectures through hypothesis generation and experiment management, with 3 engineers using REA delivering improvement proposals for 8 models where the same work historically required 2 engineers per model. KernelEvolve then handles the hardware execution layer: once REA's exploration surfaces better models, KernelEvolve produces optimized kernels to run them in production.
When a new chip arrives, the engineering cost shifts from writing thousands of kernels by hand to curating a set of hardware documents and injecting them into the knowledge base.
The two-layer architecture closes a loop that previously required substantial human coordination - ML exploration happens in REA, hardware optimization happens in KernelEvolve, and both feed findings back into shared knowledge stores that compound over time.
Hardware and Language Compatibility
| Hardware | Output Languages | Profiling Tools |
|---|---|---|
| NVIDIA GPUs | Triton, CuTe DSL, CUDA C++ | NCU, Proton, TritonBench |
| AMD GPUs | HIP, Triton | TritonBench, PyTorch Profiler |
| Meta MTIA 300-500 | FlyDSL, MTIA C++ | MTIA Insight |
| CPU | C++, SIMD intrinsics | Custom benchmarks |
For teams building similar systems, the CUDA programming guide covers the underlying kernel optimization concepts that KernelEvolve's synthesizer builds on.
Where It Falls Short
KernelEvolve is Meta's internal infrastructure - the first and biggest limitation is that you can't use it. The paper is public (arXiv:2512.23236), the architecture is documented, but the implementation - the knowledge base contents, the job harness, the MTIA integration, the internal tooling scaffolding - is all proprietary. Reproducing the NVIDIA results is theoretically feasible for a well-resourced engineering team; reproducing the MTIA gains requires hardware that isn't commercially available.
The 60% inference gain framing also needs some scrutiny. Meta's custom workloads have unusually high operator diversity - fused feature interactions, feature hashing, and sequence operations that vendor libraries don't support. Teams running more standard workloads controlled by GEMMs and convolutions will find less headroom, because the standard tooling already covers those cases well.
The "in-context reinforcement learning" framing in the paper is worth reading with skepticism. Writing successful optimizations into a retrieval store and improving future session quality is a sound engineering pattern. Calling it reinforcement learning stretches the definition clearly - there's no policy gradient, no spread reward signal, no neural network being updated. The results are real; the terminology is chosen for impact.
ISCA 2026 acceptance is the meaningful signal here. The International Symposium on Computer Architecture is a top-tier venue with serious peer review, not a workshop or company blog. The committee evaluates measurement methodology and implementation details carefully. For teams designing their own kernel optimization pipelines, the paper is worth reading - especially the tree search engine design and the hierarchical knowledge base structure. Both are applicable regardless of whether you have access to Meta's infrastructure.
Sources:

