Meta Demos Neural Computers - But They Can't Do Math
A 19-person Meta AI and KAUST team including Jürgen Schmidhuber proposes Neural Computers - systems where the neural network itself is the running computer, trained solely on screen recordings.

Every language model you've ever run is a tenant. The neural weights live inside a conventional machine that handles memory management, execution flow, and I/O - all the plumbing the model itself never touches. The model reasons; the Von Neumann CPU underneath executes.
A 19-person team from Meta AI and the King Abdullah University of Science and Technology (KAUST) wants to collapse that distinction. Their paper, submitted to arXiv on April 7, proposes Neural Computers (NCs): systems where the neural network itself is the running computer, not just a process hosted on one. Co-signed by LSTM inventor Jürgen Schmidhuber, it's one of the more ambitious architecture proposals to surface this year.
Whether it's an engineering roadmap or a thought experiment dressed up in benchmark tables depends on what you make of prototypes that still can't add two two-digit numbers reliably.
TL;DR
- Neural Computers fold computation, memory, and I/O into a single learned system - the model runs the interface, not the other way around
- Three prototypes trained only on screen recordings: CLIGen (terminal) and GUIWorld (Ubuntu desktop)
- 110 hours of goal-directed interaction data beat 1,400 hours of random exploration
- Current systems handle interface rendering and short-horizon control but fail at two-digit arithmetic
- The paper outlines four unsolved problems separating prototypes from a general-purpose system
The Problem This Is Solving
The standard stack looks like this: hardware runs an operating system, the OS runs a Python runtime, the runtime loads your model, and your model finally does the thing you care about. Every layer adds latency, complexity, and attack surface.
Agents built on today's models face a version of this overhead on every interaction. A computer use agent - like the ones Anthropic has been building since the Vercept acquisition - still needs a real operating system to generate screenshots and execute actions. The model watches through a camera; it doesn't own the hardware.
The Meta and KAUST paper asks whether you can remove the intermediate layers completely. Instead of an agent that perceives a desktop, what if the desktop itself was a neural state?
 Jürgen Schmidhuber, inventor of LSTMs and co-author of the Neural Computers paper, is a professor at KAUST in Saudi Arabia.
Source: upload.wikimedia.org
Jürgen Schmidhuber, inventor of LSTMs and co-author of the Neural Computers paper, is a professor at KAUST in Saudi Arabia.
Source: upload.wikimedia.org
How It Works Under the Hood
The Conceptual Shift
The paper defines a Neural Computer as a system that unifies "computation, memory, and I/O in a learned runtime state." Three terms in that sentence matter.
Computation means the system executes logic, not just predicts tokens. Memory means state persists and updates across interactions. I/O means the system receives inputs and produces outputs that look like a running program's outputs - specifically, screen frames.
The paper distinguishes NCs from two things they're often confused with. Agents act over external environments - they sit on top of a conventional computer and call tools. World models simulate how environments change - they predict future states. Neither is the environment itself. A Neural Computer is meant to be the environment - the running substrate.
The long-term target is what the authors call a Completely Neural Computer (CNC): Turing-complete, reprogrammable via instructions rather than code, with stable behavior during ordinary operation.
Building From Screen Recordings
The most practically interesting piece is how the prototypes were trained. The team had no access to operating system internals, source code, or execution logs. They trained on raw I/O traces: sequences of screen pixels and user actions.
For the terminal prototypes (CLIGen), they used around 1,100 hours of terminal session recordings. For GUIWorld, they built a dataset of about 1,510 hours of Ubuntu desktop footage. The models - all diffusion transformers - learn to predict the next screen frame given the current screen state and the next user action.
# Conceptual forward pass for a Neural Computer prototype
#
# Inputs:
# frame_t - current screen state as pixel sequence
# instruction - natural language goal (optional)
# action_t - next user action (keypress, mouse event, command)
#
# Output:
# frame_t+1 - next screen state generated by the model
#
# The model has no access to:
# - process memory
# - file system state
# - system calls
# - anything except what appears on screen
nc_state = model(frame_t, instruction, action_t)
frame_next = decode(nc_state)
This is what makes the approach different from conventional emulation or simulation. A traditional terminal emulator maintains explicit state: environment variables, file descriptors, process trees. The NC has none of that. It learns the surface behavior by watching enough examples of inputs producing outputs.
What the Experiments Revealed
The team tested four different methods for injecting action signals into the GUI model. "Model 4" - using cross-attention inside each transformer block, rather than latent modulation at the input - performed best, scoring highest on interface consistency and short-horizon task completion.
The more interesting finding came from the training data composition. GUIWorld models trained on 110 hours of goal-directed interaction data outperformed models trained on roughly 1,400 hours of random exploration. This confirms a pattern seen elsewhere in RL research: quality of demonstrations matters more than quantity, especially for learning purposeful behavior.
The terminal models learned to render color, cursor position, and layout accurately. The GUI model learned page transitions, short-term state continuation, and basic local interaction. Both categories work well as visual renderers.
The arithmetic failure is where the story gets complicated.
Why This Matters for Agent Design
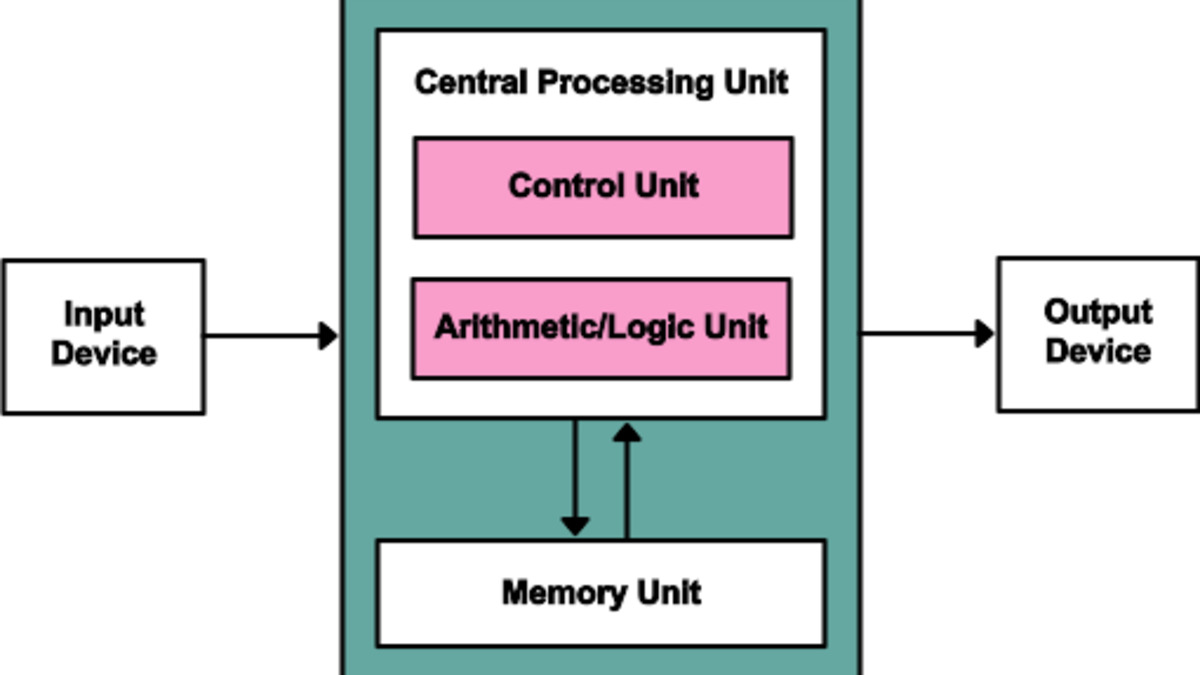 Neural Computers aim to replace this separation - CPU, memory, and I/O would unify into a single learned system.
Source: commons.wikimedia.org
Neural Computers aim to replace this separation - CPU, memory, and I/O would unify into a single learned system.
Source: commons.wikimedia.org
The paper sits at an intersection the industry hasn't fully mapped yet. Most current agentic work assumes the Von Neumann stack stays intact and you add a model on top. That's the tool-use approach: the agent calls APIs, reads files, writes output - but conventional software does the actual execution.
A few recent projects have poked at the boundary. Percepta built a deterministic WebAssembly interpreter inside transformer weights, executing programs at 33K tokens per second. The NC paper goes further by removing the explicit programming model completely - no WASM, no bytecode, just learned pixel-to-pixel transitions.
For agent designers, the immediate practical implication is limited: these systems aren't ready to host a production workflow. But the research opens a question that matters for how you think about the next five years. If models eventually provide reliable execution environments, the permission boundaries and isolation guarantees you build today may need to be rethought from scratch. The table below positions NCs against the alternatives the paper explicitly contrasts.
| System | Where Logic Lives | Environment | Reprogrammable Via |
|---|---|---|---|
| Conventional computer | CPU / OS | External | Source code |
| AI agent | External LLM | Conventional OS | Prompt / tool config |
| World model | Neural weights | Learned simulation | Retraining |
| Neural Computer | Neural weights | Neural weights | Instructions (target) |
Known Gotchas
Arithmetic is broken. The paper states explicitly that "even at the level of two-digit addition, current models still struggle to compute stably." Rendering and reasoning are different problems. The model learned what addition looks like on screen; it didn't learn to execute it. This isn't a tuning problem - it reflects a deep gap between visual prediction and symbolic computation.
No routine reuse. Conventional computers build up capability by stacking software. You write a function once and call it from anywhere. Current NC prototypes can't do this. Every behavior must emerge from training; there's no mechanism to extend the system without retraining.
Long sequences degrade. Diffusion transformers drift under extended rollouts. State that was consistent at step 10 may be corrupted by step 100. The paper identifies this as a known open problem with no current fix.
Training data quality bottleneck. The 110-vs-1,400 hour finding is promising, but sourcing high-quality goal-directed screen recordings at scale is its own hard problem. Web scraping and synthetic data generation both have significant limitations here.
The paper doesn't hide these problems. The authors describe current NCs as "fragile reasoners that excel as visual renderers" - a fair summary of what the benchmarks actually show.
The gap between the paper's vision and its current prototypes is wide. That's expected for early-stage research, and the roadmap the authors lay out is specific enough to be useful: Turing completeness, universal programmability, behavioral consistency, and machine-native semantics are the four unsolved problems standing between today's demos and a deployable system. That list gives you a way to measure progress, which puts this work ahead of most papers proposing new computing approaches for intellectual honesty.
Schmidhuber has been predicting self-improving neural systems for decades. He may be right eventually. The prototypes just need to learn arithmetic first.
Sources:

