Meituan's LongCat-2.0 Was Topping OpenRouter in Disguise
Meituan open-sources LongCat-2.0, a 1.6T MoE model trained on 50,000 Chinese ASICs that secretly topped OpenRouter under the alias Owl Alpha.

The story broke on June 30 when Meituan, a Beijing-based food delivery and super-app giant, announced it was open-sourcing LongCat-2.0, a 1.6 trillion-parameter mixture-of-experts model. The reveal came with an admission: LongCat-2.0 had been running in public for two months already, ranked among the top three models by daily token volume on OpenRouter - only nobody knew it was from Meituan. The model had been operating under the alias "Owl Alpha."
That stealth period is now the most discussed part of the launch. Before anyone knew who built it, Owl Alpha ranked first on the Hermes Agent workspace, second on Claude Code usage, and third across OpenClaw deployments, all measured by monthly call volume on OpenRouter. It was averaging 559 billion tokens per day and clocking around 10.1 trillion monthly tokens at its peak. Real developer usage at real scale, completely unbranded.
Key Specs
| Spec | Value |
|---|---|
| Total Parameters | 1.6 trillion (MoE) |
| Active Parameters | 33B - 56B per token (avg 48B) |
| Context Window | 1 million tokens native |
| License | MIT |
| Training Hardware | 50,000 Chinese ASICs |
| Training Data | 30T+ tokens |
| Pricing (promo) | $0.30/$1.20 per M input/output tokens |
The Owl Alpha Reveal
Running an anonymized model on OpenRouter isn't unusual for teams that want unbiased usage data before a public launch. What's unusual is doing it at trillion-parameter scale, hitting top-three rankings across major developer workloads, and sustaining that for two months before anyone confirmed who built it.
Meituan describes LongCat-2.0 as purpose-built for agentic software engineering. The model was developed specifically to compete in the coding agent category - the same slot where Anthropic's Claude Sonnet and OpenAI's GPT-5.5 get the most enterprise API traffic. The Owl Alpha experiment gave the team live signal on real workloads before committing to a public brand.
It also meant the model arrived with a track record rather than a press release. Developers already knew it worked at scale.
 Meituan, best known outside China as a food delivery and super-app company, has been building out a serious AI research division.
Source: thenextweb.com
Meituan, best known outside China as a food delivery and super-app company, has been building out a serious AI research division.
Source: thenextweb.com
Architecture
LongCat Sparse Attention
The 1 million-token context window is the headline spec, but the mechanism behind it - LongCat Sparse Attention (LSA) - is what makes it feasible at this scale. Standard full attention is quadratic in sequence length. LSA selects key information from a query instead of attending to every token pair, reducing the effective compute cost from quadratic to linear.
LSA does this through three layered optimizations. Streaming-aware Indexing converts fragmented memory access into predictable sequential reads, which matters on any hardware where memory bandwidth is the bottleneck. Cross-Layer Indexing amortizes attention score calculations across adjacent transformer layers instead of recomputing from scratch at each layer. Hierarchical Indexing uses a two-stage coarse-to-fine scoring approach: a fast coarse pass narrows the candidate set, then a precise pass scores only the survivors.
Together these let LongCat-2.0 handle 1 million-token prompts without the memory overhead that makes full attention impractical at that length.
Dynamic MoE Activation
The 1.6 trillion parameter count is the model's total expert capacity. Per token, the active computation is 33 to 56 billion parameters, averaging about 48 billion. The range isn't random noise - it reflects a design choice where zero-computation experts sit idle on simple tokens and only activate on complex ones. A routine string interpolation consumes far less compute than a multi-file refactor. The model adjusts dynamically, which matters for inference cost when you're running at 559 billion tokens per day.
The architecture also includes a 135 billion parameter n-gram embedding module on top of the core MoE, which improves token prediction efficiency for repetitive code patterns common in software engineering tasks.
MOPD Post-Training
The post-training phase uses MOPD - Multi-Teacher On-Policy Distillation - which fuses three specialist clusters into the unified model. Agent Experts handle tool invocation, API parsing, and multi-step workflows. Reasoning Experts cover mathematics, logic chains, and multi-hop inference. Interaction Experts focus on instruction following, alignment, and hallucination suppression.
Rather than a single generalist teacher, the model learns from three domains simultaneously, each contributing the behaviors most relevant to its specialization.
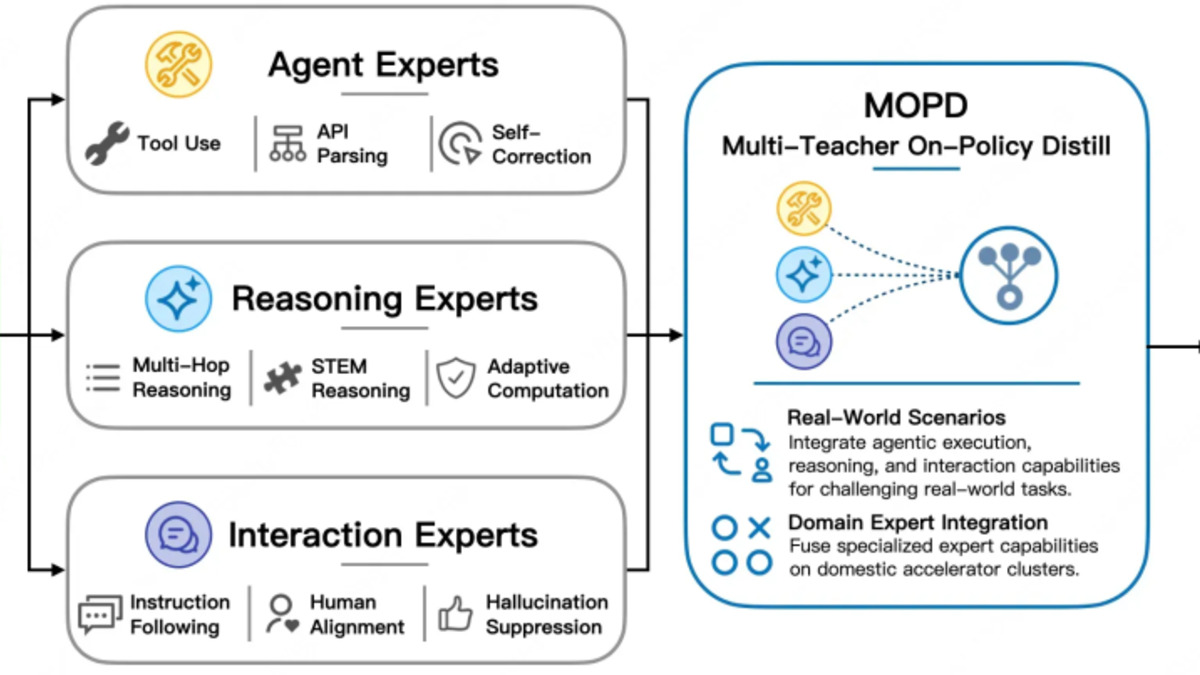 MOPD distills Agent, Reasoning, and Interaction expert clusters into a single model without sacrificing per-domain quality.
Source: longcatai.org
MOPD distills Agent, Reasoning, and Interaction expert clusters into a single model without sacrificing per-domain quality.
Source: longcatai.org
The Chinese Chip Milestone
The detail that created the most attention outside China was the training infrastructure. LongCat-2.0 was pretrained from scratch on a cluster of 50,000 domestic Chinese ASICs - no NVIDIA hardware involved. The cluster sustained over 1 trillion tokens per day of training throughput.
Meituan has not publicly identified the chip supplier. Industry observers, including analyst Rui Ma on X, have pointed to Huawei Ascend as the most likely candidate, but Meituan's announcement only references "domestic chips."
The significance here is specific. DeepSeek previously demonstrated Chinese models could achieve frontier-class results on reasoning benchmarks while using domestically made hardware for inference. LongCat-2.0 goes further: domestic hardware for both pretraining and inference at 1.6 trillion parameters. Pretraining is where the compute demand is most unforgiving - inefficient hardware at that stage causes training instability and dramatically higher costs. Completing a trillion-parameter pretraining run on domestic ASICs, with consistent throughput above 1T tokens/day, is a different category of achievement.
This matters because U.S. export controls are mainly aimed at cutting off the high-end training compute China can access. Chinese models now account for more than 60% of OpenRouter token traffic by volume. If major labs can complete trillion-parameter pretraining without NVIDIA hardware, the export control calculus changes.
Benchmark Performance
| Benchmark | LongCat-2.0 | GPT-5.5 | Claude Opus 4.6 | DeepSeek V4 Flash |
|---|---|---|---|---|
| SWE-bench Pro | 59.5 | 58.6 | - | - |
| FORTE | 73.2 | - | 73.2 | - |
| Terminal-Bench 2.1 | 70.8 | - | - | - |
| SWE-bench Multilingual | 77.3 | - | - | - |
| BrowseComp | 79.9 | - | - | - |
On SWE-bench Pro, LongCat-2.0 scores 59.5, narrowly ahead of GPT-5.5's 58.6 and putting it in the top tier of agentic coding benchmarks. Terminal-Bench 2.1, which tests command-line workflows requiring iteration and tool coordination, comes in at 70.8. The FORTE score of 73.2 ties Claude Opus 4.6 on the general corporate workflow simulator.
The benchmark set skews heavily toward agentic coding and software engineering tasks, which reflects what the model was built for. Numbers on general-purpose reasoning benchmarks (MMLU, GPQA) are not included in the official announcement.
Pricing and Access
The launch promotion prices LongCat-2.0 at $0.30 per million input tokens and $1.20 per million output tokens. Cached context reads are free. Standard rates after the promotion are $0.75 input / $2.95 output per million tokens.
For comparison: GPT-5.5 runs at $5.00/$30.00 and Claude Sonnet 5 at $2.00/$10.00. Even at standard rates, LongCat-2.0 is roughly 2.5x cheaper than Claude Sonnet 5 on output tokens, which is where the cost compounds in long agentic runs.
Access is live via longcat.ai, OpenRouter, and the LongCat API. Model weights for self-hosted deployment are listed as "coming soon" on Hugging Face and GitHub at time of writing.
What To Watch
The MIT license enables unrestricted commercial deployment and modification - no copyleft requirements, no usage restrictions. This is a more permissive stance than what Alibaba uses for Qwen models, and more open than DeepSeek's licensing. In practice, it means any company can fine-tune, quantize, and deploy LongCat-2.0 in production without legal review.
Three things are still unresolved. The chip supplier has not been officially named, which limits independent verification of the training claims. The model weights aren't yet on Hugging Face, so the "fully open" framing is incomplete until that changes. And the benchmark set is narrow enough that LongCat-2.0's general-purpose performance - outside agentic coding - is not well characterized.
That third point matters most for enterprise teams with varied workloads. The DeepSeek V4 release showed that a model optimized for one class of tasks can look different on the benchmarks a sales deck doesn't highlight. Waiting for community evals on general reasoning before routing production agentic coding traffic to LongCat-2.0 is probably the right call - but the Owl Alpha data suggests the model handles real developer workloads better than any benchmark sheet can show.
Sources:
- VentureBeat: Meituan open sources LongCat-2.0
- LongCat AI Official Model Page
- The Next Web: China's Meituan trained on domestic chips
- SCMP: China debuts biggest AI model trained on local chips
- Geopolitechs: LongCat-2.0 China's Most Unexpected AI Model
- Yahoo Tech: The Stealth AI Model That Was Quietly Topping OpenRouter
- Rui Ma on X: Huawei Ascend chip speculation
- Novalogiq: Full technical breakdown
